 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Collaborative Ensemble Framework for CTR Prediction
Nov 20, 2024



Recent advances in foundation models have established scaling laws that enable the development of larger models to achieve enhanced performance, motivating extensive research into large-scale recommendation models. However, simply increasing the model size in recommendation systems, even with large amounts of data, does not always result in the expected performance improvements. In this paper, we propose a novel framework, Collaborative Ensemble Training Network (CETNet), to leverage multiple distinct models, each with its own embedding table, to capture unique feature interaction patterns. Unlike naive model scaling, our approach emphasizes diversity and collaboration through collaborative learning, where models iteratively refine their predictions. To dynamically balance contributions from each model, we introduce a confidence-based fusion mechanism using general softmax, where model confidence is computed via negation entropy. This design ensures that more confident models have a greater influence on the final prediction while benefiting from the complementary strengths of other models. We validate our framework on three public datasets (AmazonElectronics, TaobaoAds, and KuaiVideo) as well as a large-scale industrial dataset from Meta, demonstrating its superior performance over individual models and state-of-the-art baselines. Additionally, we conduct further experiments on the Criteo and Avazu datasets to compare our method with the multi-embedding paradigm. Our results show that our framework achieves comparable or better performance with smaller embedding sizes, offering a scalable and efficient solution for CTR prediction tasks.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
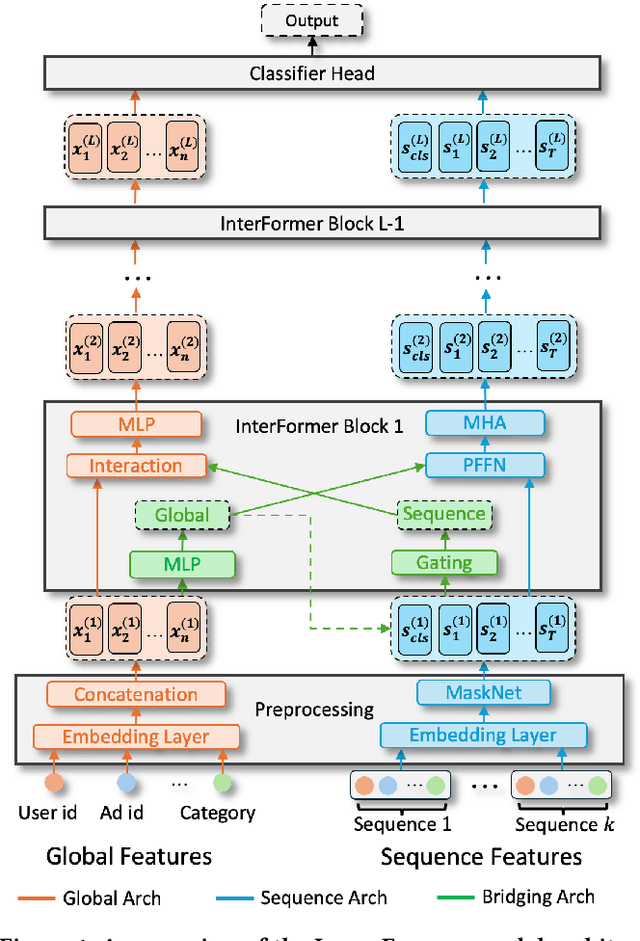
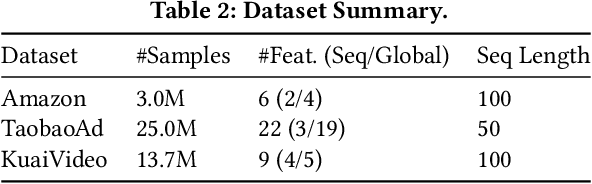
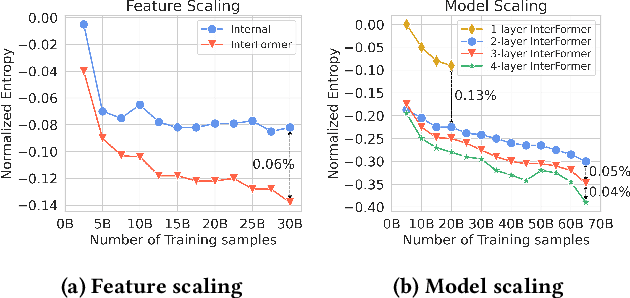
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations
Apr 11, 2023



Multi-task learning (MTL) aims at enhancing the performance and efficiency of machine learning models by training them on multiple tasks simultaneously. However, MTL research faces two challenges: 1) modeling the relationships between tasks to effectively share knowledge between them, and 2) jointly learning task-specific and shared knowledge. In this paper, we present a novel model Adaptive Task-to-Task Fusion Network (AdaTT) to address both challenges. AdaTT is a deep fusion network built with task specific and optional shared fusion units at multiple levels. By leveraging a residual mechanism and gating mechanism for task-to-task fusion, these units adaptively learn shared knowledge and task specific knowledge. To evaluate the performance of AdaTT, we conduct experiments on a public benchmark and an industrial recommendation dataset using various task groups. Results demonstrate AdaTT can significantly outperform existing state-of-the-art baselines.
Defending against GAN-based Deepfake Attacks via Transformation-aware Adversarial Faces
Jun 12, 2020


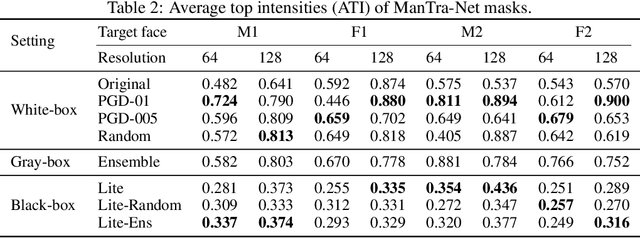
Deepfake represents a category of face-swapping attacks that leverage machine learning models such as autoencoders or generative adversarial networks. Although the concept of the face-swapping is not new, its recent technical advances make fake content (e.g., images, videos) more realistic and imperceptible to Humans. Various detection techniques for Deepfake attacks have been explored. These methods, however, are passive measures against Deepfakes as they are mitigation strategies after the high-quality fake content is generated. More importantly, we would like to think ahead of the attackers with robust defenses. This work aims to take an offensive measure to impede the generation of high-quality fake images or videos. Specifically, we propose to use novel transformation-aware adversarially perturbed faces as a defense against GAN-based Deepfake attacks. Different from the naive adversarial faces, our proposed approach leverages differentiable random image transformations during the generation. We also propose to use an ensemble-based approach to enhance the defense robustness against GAN-based Deepfake variants under the black-box setting. We show that training a Deepfake model with adversarial faces can lead to a significant degradation in the quality of synthesized faces. This degradation is twofold. On the one hand, the quality of the synthesized faces is reduced with more visual artifacts such that the synthesized faces are more obviously fake or less convincing to human observers. On the other hand, the synthesized faces can easily be detected based on various metrics.
Generative Poisoning Attack Method Against Neural Networks
Mar 03, 2017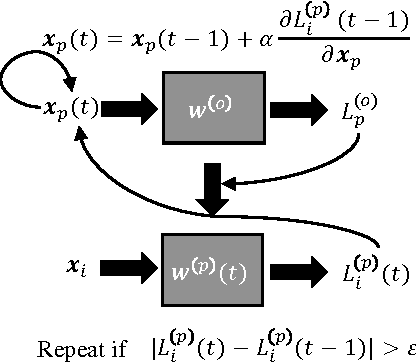


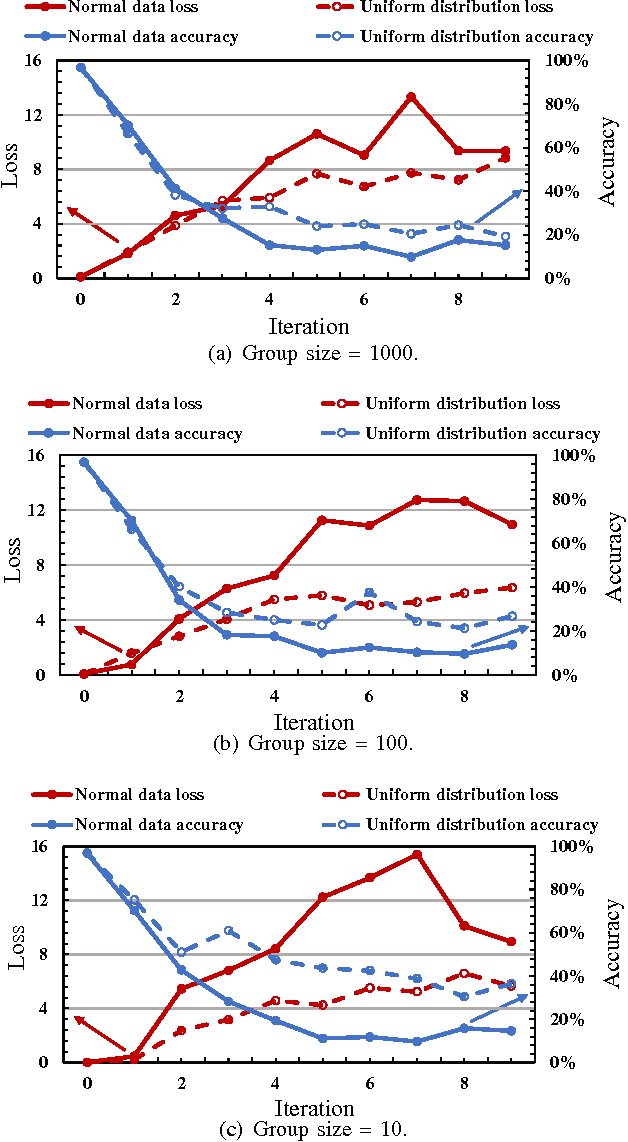
Poisoning attack is identified as a severe security threat to machine learning algorithms. In many applications, for example, deep neural network (DNN) models collect public data as the inputs to perform re-training, where the input data can be poisoned. Although poisoning attack against support vector machines (SVM) has been extensively studied before, there is still very limited knowledge about how such attack can be implemented on neural networks (NN), especially DNNs. In this work, we first examine the possibility of applying traditional gradient-based method (named as the direct gradient method) to generate poisoned data against NNs by leveraging the gradient of the target model w.r.t. the normal data. We then propose a generative method to accelerate the generation rate of the poisoned data: an auto-encoder (generator) used to generate poisoned data is updated by a reward function of the loss, and the target NN model (discriminator) receives the poisoned data to calculate the loss w.r.t. the normal data. Our experiment results show that the generative method can speed up the poisoned data generation rate by up to 239.38x compared with the direct gradient method, with slightly lower model accuracy degradation. A countermeasure is also designed to detect such poisoning attack methods by checking the loss of the target model.