 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
Meta Lattice: Model Space Redesign for Cost-Effective Industry-Scale Ads Recommendations
Dec 15, 2025The rapidly evolving landscape of products, surfaces, policies, and regulations poses significant challenges for deploying state-of-the-art recommendation models at industry scale, primarily due to data fragmentation across domains and escalating infrastructure costs that hinder sustained quality improvements. To address this challenge, we propose Lattice, a recommendation framework centered around model space redesign that extends Multi-Domain, Multi-Objective (MDMO) learning beyond models and learning objectives. Lattice addresses these challenges through a comprehensive model space redesign that combines cross-domain knowledge sharing, data consolidation, model unification, distillation, and system optimizations to achieve significant improvements in both quality and cost-efficiency. Our deployment of Lattice at Meta has resulted in 10% revenue-driving top-line metrics gain, 11.5% user satisfaction improvement, 6% boost in conversion rate, with 20% capacity saving.
A Collaborative Ensemble Framework for CTR Prediction
Nov 20, 2024



Recent advances in foundation models have established scaling laws that enable the development of larger models to achieve enhanced performance, motivating extensive research into large-scale recommendation models. However, simply increasing the model size in recommendation systems, even with large amounts of data, does not always result in the expected performance improvements. In this paper, we propose a novel framework, Collaborative Ensemble Training Network (CETNet), to leverage multiple distinct models, each with its own embedding table, to capture unique feature interaction patterns. Unlike naive model scaling, our approach emphasizes diversity and collaboration through collaborative learning, where models iteratively refine their predictions. To dynamically balance contributions from each model, we introduce a confidence-based fusion mechanism using general softmax, where model confidence is computed via negation entropy. This design ensures that more confident models have a greater influence on the final prediction while benefiting from the complementary strengths of other models. We validate our framework on three public datasets (AmazonElectronics, TaobaoAds, and KuaiVideo) as well as a large-scale industrial dataset from Meta, demonstrating its superior performance over individual models and state-of-the-art baselines. Additionally, we conduct further experiments on the Criteo and Avazu datasets to compare our method with the multi-embedding paradigm. Our results show that our framework achieves comparable or better performance with smaller embedding sizes, offering a scalable and efficient solution for CTR prediction tasks.
InterFormer: Towards Effective Heterogeneous Interaction Learning for Click-Through Rate Prediction
Nov 15, 2024
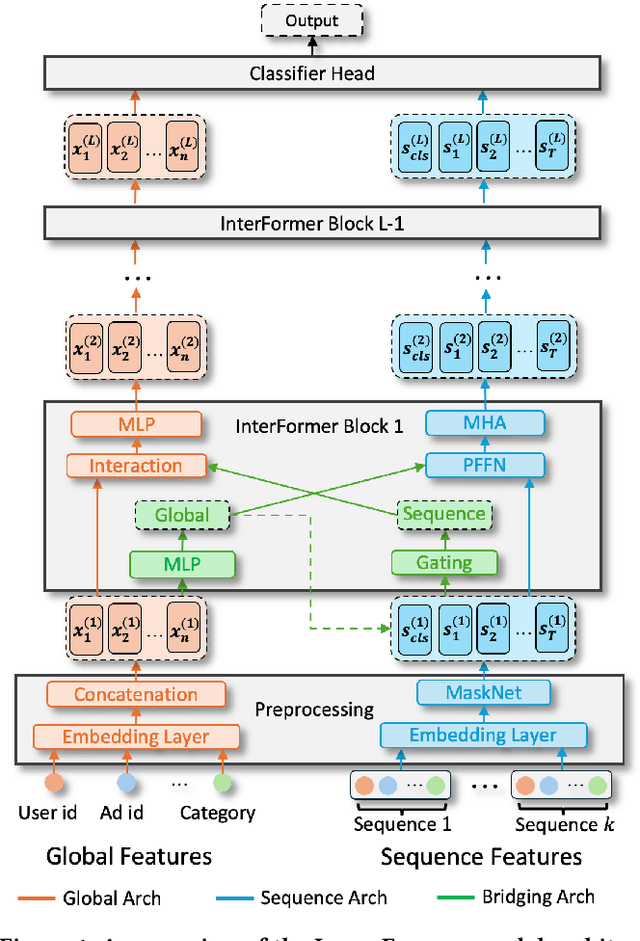
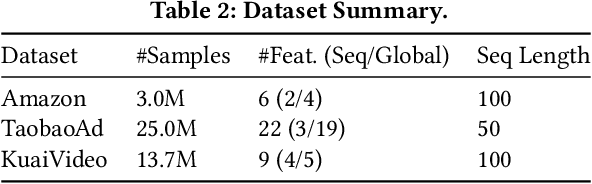
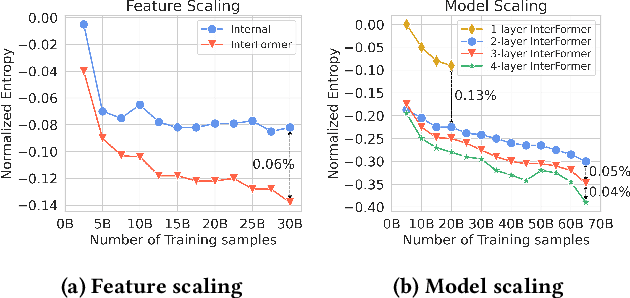
Click-through rate (CTR) prediction, which predicts the probability of a user clicking an ad, is a fundamental task in recommender systems. The emergence of heterogeneous information, such as user profile and behavior sequences, depicts user interests from different aspects. A mutually beneficial integration of heterogeneous information is the cornerstone towards the success of CTR prediction. However, most of the existing methods suffer from two fundamental limitations, including (1) insufficient inter-mode interaction due to the unidirectional information flow between modes, and (2) aggressive information aggregation caused by early summarization, resulting in excessive information loss. To address the above limitations, we propose a novel module named InterFormer to learn heterogeneous information interaction in an interleaving style. To achieve better interaction learning, InterFormer enables bidirectional information flow for mutually beneficial learning across different modes. To avoid aggressive information aggregation, we retain complete information in each data mode and use a separate bridging arch for effective information selection and summarization. Our proposed InterFormer achieves state-of-the-art performance on three public datasets and a large-scale industrial dataset.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
AdaTT: Adaptive Task-to-Task Fusion Network for Multitask Learning in Recommendations
Apr 11, 2023



Multi-task learning (MTL) aims at enhancing the performance and efficiency of machine learning models by training them on multiple tasks simultaneously. However, MTL research faces two challenges: 1) modeling the relationships between tasks to effectively share knowledge between them, and 2) jointly learning task-specific and shared knowledge. In this paper, we present a novel model Adaptive Task-to-Task Fusion Network (AdaTT) to address both challenges. AdaTT is a deep fusion network built with task specific and optional shared fusion units at multiple levels. By leveraging a residual mechanism and gating mechanism for task-to-task fusion, these units adaptively learn shared knowledge and task specific knowledge. To evaluate the performance of AdaTT, we conduct experiments on a public benchmark and an industrial recommendation dataset using various task groups. Results demonstrate AdaTT can significantly outperform existing state-of-the-art baselines.
Imputation-Free Learning from Incomplete Observations
Jul 05, 2021

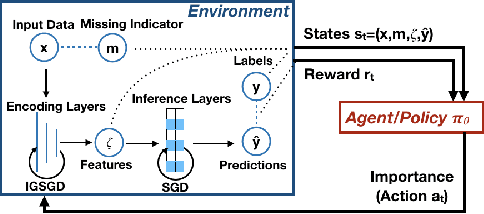
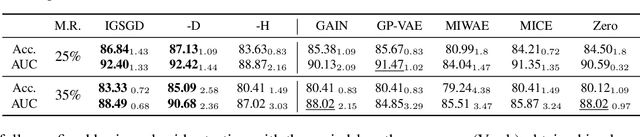
Although recent works have developed methods that can generate estimations (or imputations) of the missing entries in a dataset to facilitate downstream analysis, most depend on assumptions that may not align with real-world applications and could suffer from poor performance in subsequent tasks. This is particularly true if the data have large missingness rates or a small population. More importantly, the imputation error could be propagated into the prediction step that follows, causing the gradients used to train the prediction models to be biased. Consequently, in this work, we introduce the importance guided stochastic gradient descent (IGSGD) method to train multilayer perceptrons (MLPs) and long short-term memories (LSTMs) to directly perform inference from inputs containing missing values without imputation. Specifically, we employ reinforcement learning (RL) to adjust the gradients used to train the models via back-propagation. This not only reduces bias but allows the model to exploit the underlying information behind missingness patterns. We test the proposed approach on real-world time-series (i.e., MIMIC-III), tabular data obtained from an eye clinic, and a standard dataset (i.e., MNIST), where our imputation-free predictions outperform the traditional two-step imputation-based predictions using state-of-the-art imputation methods.
Improving Zero-shot Voice Style Transfer via Disentangled Representation Learning
Mar 17, 2021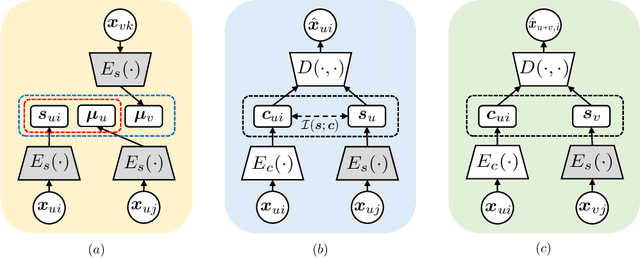


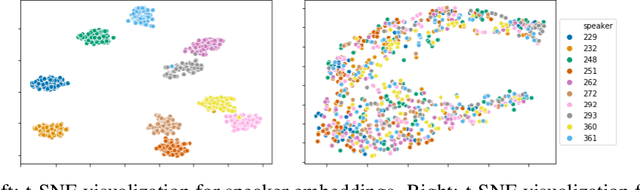
Voice style transfer, also called voice conversion, seeks to modify one speaker's voice to generate speech as if it came from another (target) speaker. Previous works have made progress on voice conversion with parallel training data and pre-known speakers. However, zero-shot voice style transfer, which learns from non-parallel data and generates voices for previously unseen speakers, remains a challenging problem. We propose a novel zero-shot voice transfer method via disentangled representation learning. The proposed method first encodes speaker-related style and voice content of each input voice into separated low-dimensional embedding spaces, and then transfers to a new voice by combining the source content embedding and target style embedding through a decoder. With information-theoretic guidance, the style and content embedding spaces are representative and (ideally) independent of each other. On real-world VCTK datasets, our method outperforms other baselines and obtains state-of-the-art results in terms of transfer accuracy and voice naturalness for voice style transfer experiments under both many-to-many and zero-shot setups.
FairFil: Contrastive Neural Debiasing Method for Pretrained Text Encoders
Mar 11, 2021
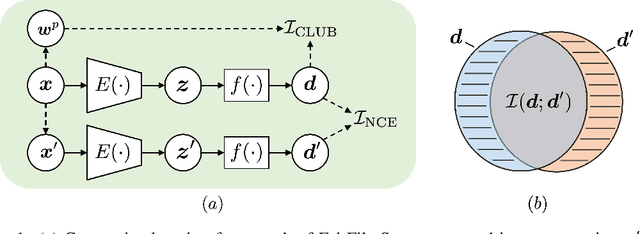
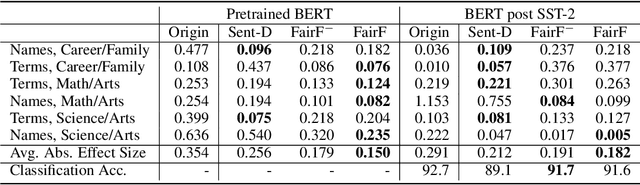
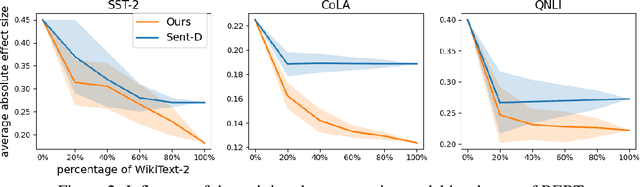
Pretrained text encoders, such as BERT, have been applied increasingly in various natural language processing (NLP) tasks, and have recently demonstrated significant performance gains. However, recent studies have demonstrated the existence of social bias in these pretrained NLP models. Although prior works have made progress on word-level debiasing, improved sentence-level fairness of pretrained encoders still lacks exploration. In this paper, we proposed the first neural debiasing method for a pretrained sentence encoder, which transforms the pretrained encoder outputs into debiased representations via a fair filter (FairFil) network. To learn the FairFil, we introduce a contrastive learning framework that not only minimizes the correlation between filtered embeddings and bias words but also preserves rich semantic information of the original sentences. On real-world datasets, our FairFil effectively reduces the bias degree of pretrained text encoders, while continuously showing desirable performance on downstream tasks. Moreover, our post-hoc method does not require any retraining of the text encoders, further enlarging FairFil's application space.
Weakly supervised cross-domain alignment with optimal transport
Aug 14, 2020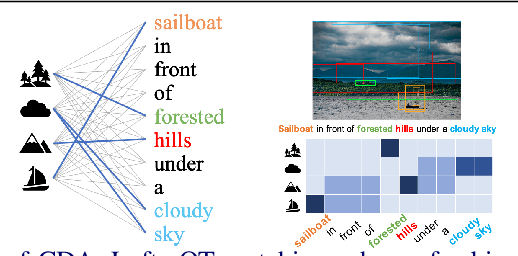
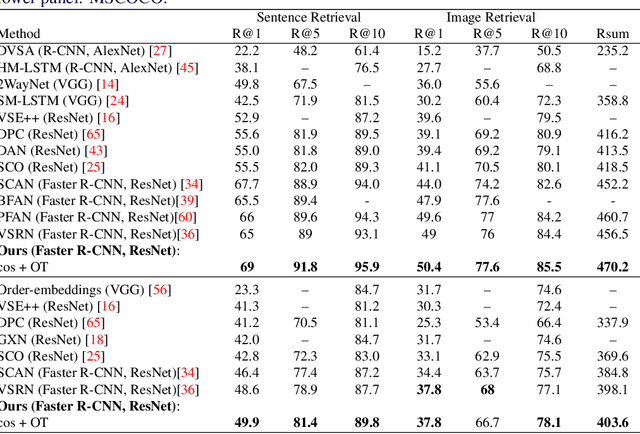
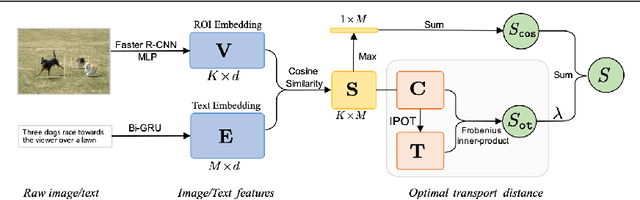
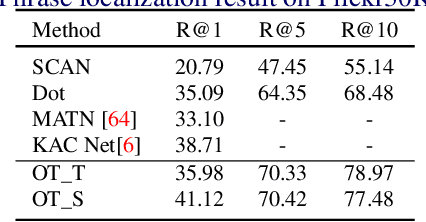
Cross-domain alignment between image objects and text sequences is key to many visual-language tasks, and it poses a fundamental challenge to both computer vision and natural language processing. This paper investigates a novel approach for the identification and optimization of fine-grained semantic similarities between image and text entities, under a weakly-supervised setup, improving performance over state-of-the-art solutions. Our method builds upon recent advances in optimal transport (OT) to resolve the cross-domain matching problem in a principled manner. Formulated as a drop-in regularizer, the proposed OT solution can be efficiently computed and used in combination with other existing approaches. We present empirical evidence to demonstrate the effectiveness of our approach, showing how it enables simpler model architectures to outperform or be comparable with more sophisticated designs on a range of vision-language tasks.