 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Retrieval Scaling with Hierarchical Indexing for Large Scale Recommendation
Apr 14, 2026The increase in data volume, computational resources, and model parameters during training has led to the development of numerous large-scale industrial retrieval models for recommendation tasks. However, effectively and efficiently deploying these large-scale foundational retrieval models remains a critical challenge that has not been fully addressed. Common quick-win solutions for deploying these massive models include relying on offline computations (such as cached user dictionaries) or distilling large models into smaller ones. Yet, both approaches fall short of fully leveraging the representational and inference capabilities of foundational models. In this paper, we explore whether it is possible to learn a hierarchical organization over the memory of foundational retrieval models. Such a hierarchical structure would enable more efficient search by reducing retrieval costs while preserving exactness. To achieve this, we propose jointly learning a hierarchical index using cross-attention and residual quantization for large-scale retrieval models. We also present its real-world deployment at Meta, supporting daily advertisement recommendations for billions of Facebook and Instagram users. Interestingly, we discovered that the intermediate nodes in the learned index correspond to a small set of high-quality data. Fine-tuning the model on this set further improves inference performance, and concretize the concept of "test-time training" within the recommendation system domain. We demonstrate these findings using both internal and public datasets with strong baseline comparisons and hope they contribute to the community's efforts in developing the next generation of foundational retrieval models.
On the Convergence Analysis of Muon
May 29, 2025The majority of parameters in neural networks are naturally represented as matrices. However, most commonly used optimizers treat these matrix parameters as flattened vectors during optimization, potentially overlooking their inherent structural properties. Recently, an optimizer called Muon has been proposed, specifically designed to optimize matrix-structured parameters. Extensive empirical evidence shows that Muon can significantly outperform traditional optimizers when training neural networks. Nonetheless, the theoretical understanding of Muon's convergence behavior and the reasons behind its superior performance remain limited. In this work, we present a comprehensive convergence rate analysis of Muon and its comparison with Gradient Descent (GD). We further characterize the conditions under which Muon can outperform GD. Our theoretical results reveal that Muon can benefit from the low-rank and approximate blockwise diagonal structure of Hessian matrices -- phenomena widely observed in practical neural network training. Our experimental results support and corroborate the theoretical findings.
Enhancing Embedding Representation Stability in Recommendation Systems with Semantic ID
Apr 02, 2025The exponential growth of online content has posed significant challenges to ID-based models in industrial recommendation systems, ranging from extremely high cardinality and dynamically growing ID space, to highly skewed engagement distributions, to prediction instability as a result of natural id life cycles (e.g, the birth of new IDs and retirement of old IDs). To address these issues, many systems rely on random hashing to handle the id space and control the corresponding model parameters (i.e embedding table). However, this approach introduces data pollution from multiple ids sharing the same embedding, leading to degraded model performance and embedding representation instability. This paper examines these challenges and introduces Semantic ID prefix ngram, a novel token parameterization technique that significantly improves the performance of the original Semantic ID. Semantic ID prefix ngram creates semantically meaningful collisions by hierarchically clustering items based on their content embeddings, as opposed to random assignments. Through extensive experimentation, we demonstrate that Semantic ID prefix ngram not only addresses embedding instability but also significantly improves tail id modeling, reduces overfitting, and mitigates representation shifts. We further highlight the advantages of Semantic ID prefix ngram in attention-based models that contextualize user histories, showing substantial performance improvements. We also report our experience of integrating Semantic ID into Meta production Ads Ranking system, leading to notable performance gains and enhanced prediction stability in live deployments.
Tuning-Free Bilevel Optimization: New Algorithms and Convergence Analysis
Oct 07, 2024



Bilevel optimization has recently attracted considerable attention due to its abundant applications in machine learning problems. However, existing methods rely on prior knowledge of problem parameters to determine stepsizes, resulting in significant effort in tuning stepsizes when these parameters are unknown. In this paper, we propose two novel tuning-free algorithms, D-TFBO and S-TFBO. D-TFBO employs a double-loop structure with stepsizes adaptively adjusted by the "inverse of cumulative gradient norms" strategy. S-TFBO features a simpler fully single-loop structure that updates three variables simultaneously with a theory-motivated joint design of adaptive stepsizes for all variables. We provide a comprehensive convergence analysis for both algorithms and show that D-TFBO and S-TFBO respectively require $O(\frac{1}{\epsilon})$ and $O(\frac{1}{\epsilon}\log^4(\frac{1}{\epsilon}))$ iterations to find an $\epsilon$-accurate stationary point, (nearly) matching their well-tuned counterparts using the information of problem parameters. Experiments on various problems show that our methods achieve performance comparable to existing well-tuned approaches, while being more robust to the selection of initial stepsizes. To the best of our knowledge, our methods are the first to completely eliminate the need for stepsize tuning, while achieving theoretical guarantees.
Hierarchical Structured Neural Network for Retrieval
Aug 13, 2024



Embedding Based Retrieval (EBR) is a crucial component of the retrieval stage in (Ads) Recommendation System that utilizes Two Tower or Siamese Networks to learn embeddings for both users and items (ads). It then employs an Approximate Nearest Neighbor Search (ANN) to efficiently retrieve the most relevant ads for a specific user. Despite the recent rise to popularity in the industry, they have a couple of limitations. Firstly, Two Tower model architecture uses a single dot product interaction which despite their efficiency fail to capture the data distribution in practice. Secondly, the centroid representation and cluster assignment, which are components of ANN, occur after the training process has been completed. As a result, they do not take into account the optimization criteria used for retrieval model. In this paper, we present Hierarchical Structured Neural Network (HSNN), a deployed jointly optimized hierarchical clustering and neural network model that can take advantage of sophisticated interactions and model architectures that are more common in the ranking stages while maintaining a sub-linear inference cost. We achieve 6.5% improvement in offline evaluation and also demonstrate 1.22% online gains through A/B experiments. HSNN has been successfully deployed into the Ads Recommendation system and is currently handling major portion of the traffic. The paper shares our experience in developing this system, dealing with challenges like freshness, volatility, cold start recommendations, cluster collapse and lessons deploying the model in a large scale retrieval production system.
Stochastic Smoothed Gradient Descent Ascent for Federated Minimax Optimization
Nov 02, 2023In recent years, federated minimax optimization has attracted growing interest due to its extensive applications in various machine learning tasks. While Smoothed Alternative Gradient Descent Ascent (Smoothed-AGDA) has proved its success in centralized nonconvex minimax optimization, how and whether smoothing technique could be helpful in federated setting remains unexplored. In this paper, we propose a new algorithm termed Federated Stochastic Smoothed Gradient Descent Ascent (FESS-GDA), which utilizes the smoothing technique for federated minimax optimization. We prove that FESS-GDA can be uniformly used to solve several classes of federated minimax problems and prove new or better analytical convergence results for these settings. We showcase the practical efficiency of FESS-GDA in practical federated learning tasks of training generative adversarial networks (GANs) and fair classification.
Achieving Linear Speedup in Non-IID Federated Bilevel Learning
Feb 10, 2023



Federated bilevel optimization has received increasing attention in various emerging machine learning and communication applications. Recently, several Hessian-vector-based algorithms have been proposed to solve the federated bilevel optimization problem. However, several important properties in federated learning such as the partial client participation and the linear speedup for convergence (i.e., the convergence rate and complexity are improved linearly with respect to the number of sampled clients) in the presence of non-i.i.d.~datasets, still remain open. In this paper, we fill these gaps by proposing a new federated bilevel algorithm named FedMBO with a novel client sampling scheme in the federated hypergradient estimation. We show that FedMBO achieves a convergence rate of $\mathcal{O}\big(\frac{1}{\sqrt{nK}}+\frac{1}{K}+\frac{\sqrt{n}}{K^{3/2}}\big)$ on non-i.i.d.~datasets, where $n$ is the number of participating clients in each round, and $K$ is the total number of iteration. This is the first theoretical linear speedup result for non-i.i.d.~federated bilevel optimization. Extensive experiments validate our theoretical results and demonstrate the effectiveness of our proposed method.
Decentralized Stochastic Bilevel Optimization with Improved Per-Iteration Complexity
Oct 23, 2022Bilevel optimization recently has received tremendous attention due to its great success in solving important machine learning problems like meta learning, reinforcement learning, and hyperparameter optimization. Extending single-agent training on bilevel problems to the decentralized setting is a natural generalization, and there has been a flurry of work studying decentralized bilevel optimization algorithms. However, it remains unknown how to design the distributed algorithm with sample complexity and convergence rate comparable to SGD for stochastic optimization, and at the same time without directly computing the exact Hessian or Jacobian matrices. In this paper we propose such an algorithm. More specifically, we propose a novel decentralized stochastic bilevel optimization (DSBO) algorithm that only requires first order stochastic oracle, Hessian-vector product and Jacobian-vector product oracle. The sample complexity of our algorithm matches the currently best known results for DSBO, and the advantage of our algorithm is that it does not require estimating the full Hessian and Jacobian matrices, thereby having improved per-iteration complexity.
Efficiently Escaping Saddle Points in Bilevel Optimization
Feb 08, 2022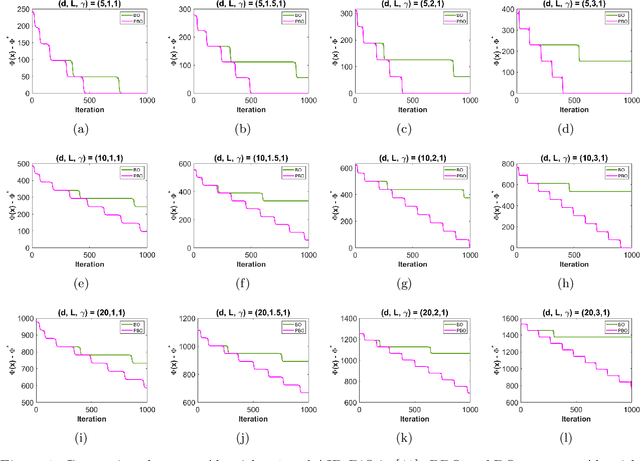
Bilevel optimization is one of the fundamental problems in machine learning and optimization. Recent theoretical developments in bilevel optimization focus on finding the first-order stationary points for nonconvex-strongly-convex cases. In this paper, we analyze algorithms that can escape saddle points in nonconvex-strongly-convex bilevel optimization. Specifically, we show that the perturbed approximate implicit differentiation (AID) with a warm start strategy finds $\epsilon$-approximate local minimum of bilevel optimization in $\tilde{O}(\epsilon^{-2})$ iterations with high probability. Moreover, we propose an inexact NEgative-curvature-Originated-from-Noise Algorithm (iNEON), a pure first-order algorithm that can escape saddle point and find local minimum of stochastic bilevel optimization. As a by-product, we provide the first nonasymptotic analysis of perturbed multi-step gradient descent ascent (GDmax) algorithm that converges to local minimax point for minimax problems.
On the Convergence of Projected Alternating Maximization for Equitable and Optimal Transport
Oct 01, 2021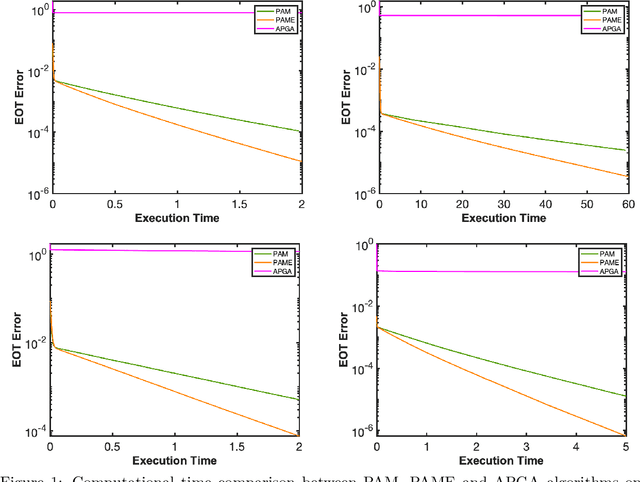

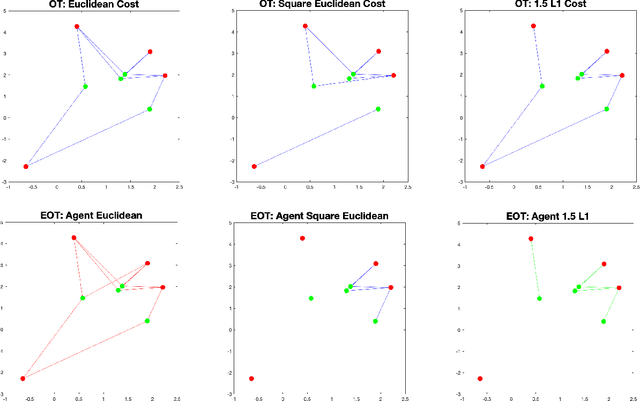
This paper studies the equitable and optimal transport (EOT) problem, which has many applications such as fair division problems and optimal transport with multiple agents etc. In the discrete distributions case, the EOT problem can be formulated as a linear program (LP). Since this LP is prohibitively large for general LP solvers, Scetbon \etal \cite{scetbon2021equitable} suggests to perturb the problem by adding an entropy regularization. They proposed a projected alternating maximization algorithm (PAM) to solve the dual of the entropy regularized EOT. In this paper, we provide the first convergence analysis of PAM. A novel rounding procedure is proposed to help construct the primal solution for the original EOT problem. We also propose a variant of PAM by incorporating the extrapolation technique that can numerically improve the performance of PAM. Results in this paper may shed lights on block coordinate (gradient) descent methods for general optimization problems.