 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFinite-Particle Rates for Regularized Stein Variational Gradient Descent
Feb 05, 2026We derive finite-particle rates for the regularized Stein variational gradient descent (R-SVGD) algorithm introduced by He et al. (2024) that corrects the constant-order bias of the SVGD by applying a resolvent-type preconditioner to the kernelized Wasserstein gradient. For the resulting interacting $N$-particle system, we establish explicit non-asymptotic bounds for time-averaged (annealed) empirical measures, illustrating convergence in the \emph{true} (non-kernelized) Fisher information and, under a $\mathrm{W}_1\mathrm{I}$ condition on the target, corresponding $\mathrm{W}_1$ convergence for a large class of smooth kernels. Our analysis covers both continuous- and discrete-time dynamics and yields principled tuning rules for the regularization parameter, step size, and averaging horizon that quantify the trade-off between approximating the Wasserstein gradient flow and controlling finite-particle estimation error.
Total Variation Rates for Riemannian Flow Matching
Feb 05, 2026Riemannian flow matching (RFM) extends flow-based generative modeling to data supported on manifolds by learning a time-dependent tangent vector field whose flow-ODE transports a simple base distribution to the data law. We develop a nonasymptotic Total Variation (TV) convergence analysis for RFM samplers that use a learned vector field together with Euler discretization on manifolds. Our key technical ingredient is a differential inequality governing the evolution of TV between two manifold ODE flows, which expresses the time-derivative of TV through the divergence of the vector-field mismatch and the score of the reference flow; controlling these terms requires establishing new bounds that explicitly account for parallel transport and curvature. Under smoothness assumptions on the population flow-matching field and either uniform (compact manifolds) or mean-square (Hadamard manifolds) approximation guarantees for the learned field, we obtain explicit bounds of the form $\mathrm{TV}\le C_{\mathrm{Lip}}\,h + C_{\varepsilon}\,\varepsilon$ (with an additional higher-order $\varepsilon^2$ term on compact manifolds), cleanly separating numerical discretization and learning errors. Here, $h$ is the step-size and $\varepsilon$ is the target accuracy. Instantiations yield \emph{explicit} polynomial iteration complexities on the hypersphere $S^d$, and on the SPD$(n)$ manifolds under mild moment conditions.
Dependence-Aware Label Aggregation for LLM-as-a-Judge via Ising Models
Jan 29, 2026Large-scale AI evaluation increasingly relies on aggregating binary judgments from $K$ annotators, including LLMs used as judges. Most classical methods, e.g., Dawid-Skene or (weighted) majority voting, assume annotators are conditionally independent given the true label $Y\in\{0,1\}$, an assumption often violated by LLM judges due to shared data, architectures, prompts, and failure modes. Ignoring such dependencies can yield miscalibrated posteriors and even confidently incorrect predictions. We study label aggregation through a hierarchy of dependence-aware models based on Ising graphical models and latent factors. For class-dependent Ising models, the Bayes log-odds is generally quadratic in votes; for class-independent couplings, it reduces to a linear weighted vote with correlation-adjusted parameters. We present finite-$K$ examples showing that methods based on conditional independence can flip the Bayes label despite matching per-annotator marginals. We prove separation results demonstrating that these methods remain strictly suboptimal as the number of judges grows, incurring nonvanishing excess risk under latent factors. Finally, we evaluate the proposed method on three real-world datasets, demonstrating improved performance over the classical baselines.
Dense Associative Memory with Epanechnikov Energy
Jun 12, 2025We propose a novel energy function for Dense Associative Memory (DenseAM) networks, the log-sum-ReLU (LSR), inspired by optimal kernel density estimation. Unlike the common log-sum-exponential (LSE) function, LSR is based on the Epanechnikov kernel and enables exact memory retrieval with exponential capacity without requiring exponential separation functions. Moreover, it introduces abundant additional \emph{emergent} local minima while preserving perfect pattern recovery -- a characteristic previously unseen in DenseAM literature. Empirical results show that LSR energy has significantly more local minima (memories) that have comparable log-likelihood to LSE-based models. Analysis of LSR's emergent memories on image datasets reveals a degree of creativity and novelty, hinting at this method's potential for both large-scale memory storage and generative tasks.
Riemannian Proximal Sampler for High-accuracy Sampling on Manifolds
Feb 11, 2025We introduce the Riemannian Proximal Sampler, a method for sampling from densities defined on Riemannian manifolds. The performance of this sampler critically depends on two key oracles: the Manifold Brownian Increments (MBI) oracle and the Riemannian Heat-kernel (RHK) oracle. We establish high-accuracy sampling guarantees for the Riemannian Proximal Sampler, showing that generating samples with $\varepsilon$-accuracy requires $O(\log(1/\varepsilon))$ iterations in Kullback-Leibler divergence assuming access to exact oracles and $O(\log^2(1/\varepsilon))$ iterations in the total variation metric assuming access to sufficiently accurate inexact oracles. Furthermore, we present practical implementations of these oracles by leveraging heat-kernel truncation and Varadhan's asymptotics. In the latter case, we interpret the Riemannian Proximal Sampler as a discretization of the entropy-regularized Riemannian Proximal Point Method on the associated Wasserstein space. We provide preliminary numerical results that illustrate the effectiveness of the proposed methodology.
Gaussian and Bootstrap Approximation for Matching-based Average Treatment Effect Estimators
Dec 22, 2024We establish Gaussian approximation bounds for covariate and rank-matching-based Average Treatment Effect (ATE) estimators. By analyzing these estimators through the lens of stabilization theory, we employ the Malliavin-Stein method to derive our results. Our bounds precisely quantify the impact of key problem parameters, including the number of matches and treatment balance, on the accuracy of the Gaussian approximation. Additionally, we develop multiplier bootstrap procedures to estimate the limiting distribution in a fully data-driven manner, and we leverage the derived Gaussian approximation results to further obtain bootstrap approximation bounds. Our work not only introduces a novel theoretical framework for commonly used ATE estimators, but also provides data-driven methods for constructing non-asymptotically valid confidence intervals.
Provable In-context Learning for Mixture of Linear Regressions using Transformers
Oct 18, 2024We theoretically investigate the in-context learning capabilities of transformers in the context of learning mixtures of linear regression models. For the case of two mixtures, we demonstrate the existence of transformers that can achieve an accuracy, relative to the oracle predictor, of order $\mathcal{\tilde{O}}((d/n)^{1/4})$ in the low signal-to-noise ratio (SNR) regime and $\mathcal{\tilde{O}}(\sqrt{d/n})$ in the high SNR regime, where $n$ is the length of the prompt, and $d$ is the dimension of the problem. Additionally, we derive in-context excess risk bounds of order $\mathcal{O}(L/\sqrt{B})$, where $B$ denotes the number of (training) prompts, and $L$ represents the number of attention layers. The order of $L$ depends on whether the SNR is low or high. In the high SNR regime, we extend the results to $K$-component mixture models for finite $K$. Extensive simulations also highlight the advantages of transformers for this task, outperforming other baselines such as the Expectation-Maximization algorithm.
Transformers Handle Endogeneity in In-Context Linear Regression
Oct 02, 2024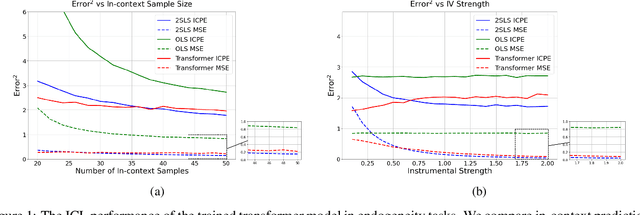
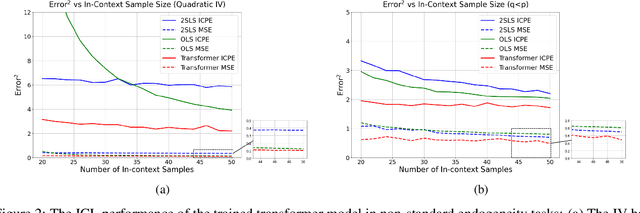
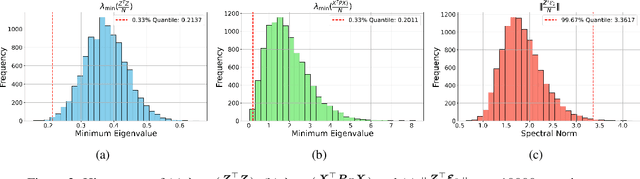
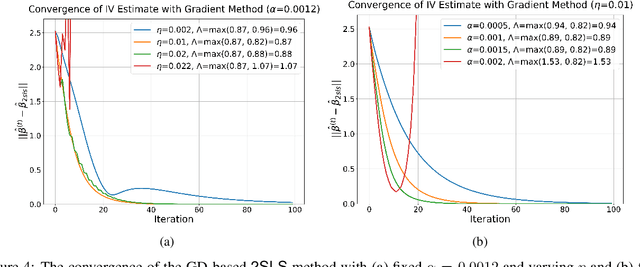
We explore the capability of transformers to address endogeneity in in-context linear regression. Our main finding is that transformers inherently possess a mechanism to handle endogeneity effectively using instrumental variables (IV). First, we demonstrate that the transformer architecture can emulate a gradient-based bi-level optimization procedure that converges to the widely used two-stage least squares $(\textsf{2SLS})$ solution at an exponential rate. Next, we propose an in-context pretraining scheme and provide theoretical guarantees showing that the global minimizer of the pre-training loss achieves a small excess loss. Our extensive experiments validate these theoretical findings, showing that the trained transformer provides more robust and reliable in-context predictions and coefficient estimates than the $\textsf{2SLS}$ method, in the presence of endogeneity.
Improved Finite-Particle Convergence Rates for Stein Variational Gradient Descent
Sep 13, 2024We provide finite-particle convergence rates for the Stein Variational Gradient Descent (SVGD) algorithm in the Kernel Stein Discrepancy ($\mathsf{KSD}$) and Wasserstein-2 metrics. Our key insight is the observation that the time derivative of the relative entropy between the joint density of $N$ particle locations and the $N$-fold product target measure, starting from a regular initial distribution, splits into a dominant `negative part' proportional to $N$ times the expected $\mathsf{KSD}^2$ and a smaller `positive part'. This observation leads to $\mathsf{KSD}$ rates of order $1/\sqrt{N}$, providing a near optimal double exponential improvement over the recent result by~\cite{shi2024finite}. Under mild assumptions on the kernel and potential, these bounds also grow linearly in the dimension $d$. By adding a bilinear component to the kernel, the above approach is used to further obtain Wasserstein-2 convergence. For the case of `bilinear + Mat\'ern' kernels, we derive Wasserstein-2 rates that exhibit a curse-of-dimensionality similar to the i.i.d. setting. We also obtain marginal convergence and long-time propagation of chaos results for the time-averaged particle laws.
Stochastic Optimization Algorithms for Instrumental Variable Regression with Streaming Data
May 29, 2024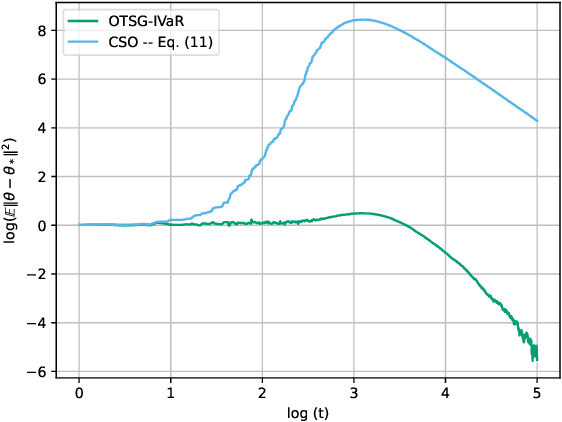

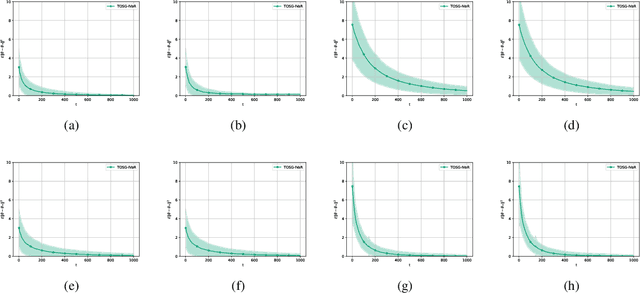
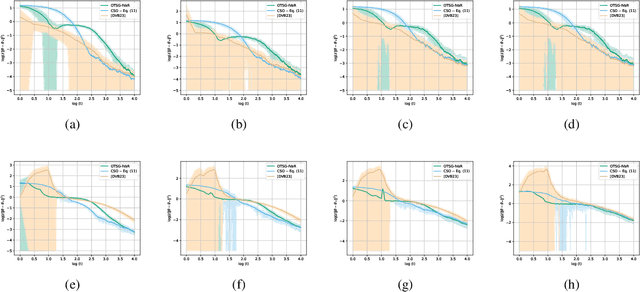
We develop and analyze algorithms for instrumental variable regression by viewing the problem as a conditional stochastic optimization problem. In the context of least-squares instrumental variable regression, our algorithms neither require matrix inversions nor mini-batches and provides a fully online approach for performing instrumental variable regression with streaming data. When the true model is linear, we derive rates of convergence in expectation, that are of order $\mathcal{O}(\log T/T)$ and $\mathcal{O}(1/T^{1-\iota})$ for any $\iota>0$, respectively under the availability of two-sample and one-sample oracles, respectively, where $T$ is the number of iterations. Importantly, under the availability of the two-sample oracle, our procedure avoids explicitly modeling and estimating the relationship between confounder and the instrumental variables, demonstrating the benefit of the proposed approach over recent works based on reformulating the problem as minimax optimization problems. Numerical experiments are provided to corroborate the theoretical results.