 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniLab: A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
Jun 02, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, FastSAC, FlashSAC, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://unilabsim.github.io.
A Heterogeneous Architecture for Robot RL Beyond GPU-Dominant Paradigms
May 28, 2026Simulation-based RL for contemporary robot control is increasingly organized around GPU-resident simulation: physics, rollout collection, and learning are placed on a single GPU-centric execution path. This paradigm has greatly improved training speed, but it has also encouraged a default assumption that efficient training requires physics to reside on the GPU. We revisit this assumption. Our view is that, in simulation-dominated robot control, the essential question is not which processor runs physics, but whether simulation throughput, policy learning, and runtime synchronization form an efficient end-to-end loop. We present UniLab, a heterogeneous CPU-simulation / GPU-learning architecture that decouples CPU-parallel simulation from GPU policy updates through a unified runtime for data movement, buffering, and synchronization. UniLab is implemented as a complete and extensible training system using MuJoCoUni and MotrixSim CPU-batched physics backends, supporting PPO, SAC, FlashSAC, TD3, and APPO. On representative simulation-based robot control tasks, UniLab improves end-to-end training efficiency by 3--10$\times$ under the same hardware configuration, while reducing dependence on the NVIDIA CUDA-based software stack and supporting cross-platform execution on the Apple macOS platform and the AMD ROCm and Intel XPU accelerator backends. These results show that GPU simulation is an effective path to efficient training, but not a necessary one, broadening the practical system choices available for robot RL training. Project page: https://github.com/unilabsim/UniLab.
Know More, Know Clearer: A Meta-Cognitive Framework for Knowledge Augmentation in Large Language Models
Feb 13, 2026Knowledge augmentation has significantly enhanced the performance of Large Language Models (LLMs) in knowledge-intensive tasks. However, existing methods typically operate on the simplistic premise that model performance equates with internal knowledge, overlooking the knowledge-confidence gaps that lead to overconfident errors or uncertain truths. To bridge this gap, we propose a novel meta-cognitive framework for reliable knowledge augmentation via differentiated intervention and alignment. Our approach leverages internal cognitive signals to partition the knowledge space into mastered, confused, and missing regions, guiding targeted knowledge expansion. Furthermore, we introduce a cognitive consistency mechanism to synchronize subjective certainty with objective accuracy, ensuring calibrated knowledge boundaries. Extensive experiments demonstrate the our framework consistently outperforms strong baselines, validating its rationality in not only enhancing knowledge capabilities but also fostering cognitive behaviors that better distinguish knowns from unknowns.
ABot-N0: Technical Report on the VLA Foundation Model for Versatile Embodied Navigation
Feb 12, 2026Embodied navigation has long been fragmented by task-specific architectures. We introduce ABot-N0, a unified Vision-Language-Action (VLA) foundation model that achieves a ``Grand Unification'' across 5 core tasks: Point-Goal, Object-Goal, Instruction-Following, POI-Goal, and Person-Following. ABot-N0 utilizes a hierarchical ``Brain-Action'' architecture, pairing an LLM-based Cognitive Brain for semantic reasoning with a Flow Matching-based Action Expert for precise, continuous trajectory generation. To support large-scale learning, we developed the ABot-N0 Data Engine, curating 16.9M expert trajectories and 5.0M reasoning samples across 7,802 high-fidelity 3D scenes (10.7 $\text{km}^2$). ABot-N0 achieves new SOTA performance across 7 benchmarks, significantly outperforming specialized models. Furthermore, our Agentic Navigation System integrates a planner with hierarchical topological memory, enabling robust, long-horizon missions in dynamic real-world environments.
Diffusion Model's Generalization Can Be Characterized by Inductive Biases toward a Data-Dependent Ridge Manifold
Feb 05, 2026When a diffusion model is not memorizing the training data set, how does it generalize exactly? A quantitative understanding of the distribution it generates would be beneficial to, for example, an assessment of the model's performance for downstream applications. We thus explicitly characterize what diffusion model generates, by proposing a log-density ridge manifold and quantifying how the generated data relate to this manifold as inference dynamics progresses. More precisely, inference undergoes a reach-align-slide process centered around the ridge manifold: trajectories first reach a neighborhood of the manifold, then align as being pushed toward or away from the manifold in normal directions, and finally slide along the manifold in tangent directions. Within the scope of this general behavior, different training errors will lead to different normal and tangent motions, which can be quantified, and these detailed motions characterize when inter-mode generations emerge. More detailed understanding of training dynamics will lead to more accurate quantification of the generation inductive bias, and an example of random feature model will be considered, for which we can explicitly illustrate how diffusion model's inductive biases originate as a composition of architectural bias and training accuracy, and how they evolve with the inference dynamics. Experiments on synthetic multimodal distributions and MNIST latent diffusion support the predicted directional effects, in both low- and high-dimensions.
Finite-Particle Rates for Regularized Stein Variational Gradient Descent
Feb 05, 2026We derive finite-particle rates for the regularized Stein variational gradient descent (R-SVGD) algorithm introduced by He et al. (2024) that corrects the constant-order bias of the SVGD by applying a resolvent-type preconditioner to the kernelized Wasserstein gradient. For the resulting interacting $N$-particle system, we establish explicit non-asymptotic bounds for time-averaged (annealed) empirical measures, illustrating convergence in the \emph{true} (non-kernelized) Fisher information and, under a $\mathrm{W}_1\mathrm{I}$ condition on the target, corresponding $\mathrm{W}_1$ convergence for a large class of smooth kernels. Our analysis covers both continuous- and discrete-time dynamics and yields principled tuning rules for the regularization parameter, step size, and averaging horizon that quantify the trade-off between approximating the Wasserstein gradient flow and controlling finite-particle estimation error.
Wavelet Predictive Representations for Non-Stationary Reinforcement Learning
Oct 06, 2025The real world is inherently non-stationary, with ever-changing factors, such as weather conditions and traffic flows, making it challenging for agents to adapt to varying environmental dynamics. Non-Stationary Reinforcement Learning (NSRL) addresses this challenge by training agents to adapt rapidly to sequences of distinct Markov Decision Processes (MDPs). However, existing NSRL approaches often focus on tasks with regularly evolving patterns, leading to limited adaptability in highly dynamic settings. Inspired by the success of Wavelet analysis in time series modeling, specifically its ability to capture signal trends at multiple scales, we propose WISDOM to leverage wavelet-domain predictive task representations to enhance NSRL. WISDOM captures these multi-scale features in evolving MDP sequences by transforming task representation sequences into the wavelet domain, where wavelet coefficients represent both global trends and fine-grained variations of non-stationary changes. In addition to the auto-regressive modeling commonly employed in time series forecasting, we devise a wavelet temporal difference (TD) update operator to enhance tracking and prediction of MDP evolution. We theoretically prove the convergence of this operator and demonstrate policy improvement with wavelet task representations. Experiments on diverse benchmarks show that WISDOM significantly outperforms existing baselines in both sample efficiency and asymptotic performance, demonstrating its remarkable adaptability in complex environments characterized by non-stationary and stochastically evolving tasks.
Brain-inspired AI Agent: The Way Towards AGI
Dec 12, 2024Artificial General Intelligence (AGI), widely regarded as the fundamental goal of artificial intelligence, represents the realization of cognitive capabilities that enable the handling of general tasks with human-like proficiency. Researchers in brain-inspired AI seek inspiration from the operational mechanisms of the human brain, aiming to replicate its functional rules in intelligent models. Moreover, with the rapid development of large-scale models in recent years, the concept of agents has garnered increasing attention, with researchers widely recognizing it as a necessary pathway toward achieving AGI. In this article, we propose the concept of a brain-inspired AI agent and analyze how to extract relatively feasible and agent-compatible cortical region functionalities and their associated functional connectivity networks from the complex mechanisms of the human brain. Implementing these structures within an agent enables it to achieve basic cognitive intelligence akin to human capabilities. Finally, we explore the limitations and challenges for realizing brain-inspired agents and discuss their future development.
Evaluating the design space of diffusion-based generative models
Jun 18, 2024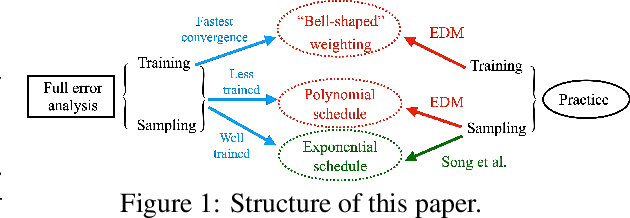

Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides some perspectives on why the time and variance schedule used in [Karras et al. 2022] could be better tuned than the pioneering version in [Song et al. 2020].
A Separation in Heavy-Tailed Sampling: Gaussian vs. Stable Oracles for Proximal Samplers
May 27, 2024We study the complexity of heavy-tailed sampling and present a separation result in terms of obtaining high-accuracy versus low-accuracy guarantees i.e., samplers that require only $O(\log(1/\varepsilon))$ versus $\Omega(\text{poly}(1/\varepsilon))$ iterations to output a sample which is $\varepsilon$-close to the target in $\chi^2$-divergence. Our results are presented for proximal samplers that are based on Gaussian versus stable oracles. We show that proximal samplers based on the Gaussian oracle have a fundamental barrier in that they necessarily achieve only low-accuracy guarantees when sampling from a class of heavy-tailed targets. In contrast, proximal samplers based on the stable oracle exhibit high-accuracy guarantees, thereby overcoming the aforementioned limitation. We also prove lower bounds for samplers under the stable oracle and show that our upper bounds cannot be fundamentally improved.