 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating the design space of diffusion-based generative models
Paper and Code
Jun 18, 2024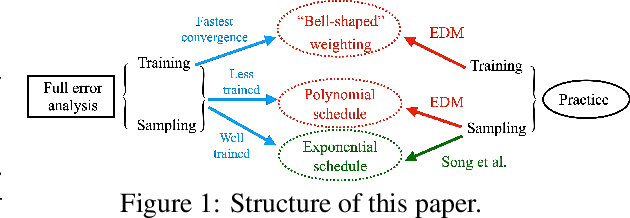

Most existing theoretical investigations of the accuracy of diffusion models, albeit significant, assume the score function has been approximated to a certain accuracy, and then use this a priori bound to control the error of generation. This article instead provides a first quantitative understanding of the whole generation process, i.e., both training and sampling. More precisely, it conducts a non-asymptotic convergence analysis of denoising score matching under gradient descent. In addition, a refined sampling error analysis for variance exploding models is also provided. The combination of these two results yields a full error analysis, which elucidates (again, but this time theoretically) how to design the training and sampling processes for effective generation. For instance, our theory implies a preference toward noise distribution and loss weighting that qualitatively agree with the ones used in [Karras et al. 2022]. It also provides some perspectives on why the time and variance schedule used in [Karras et al. 2022] could be better tuned than the pioneering version in [Song et al. 2020].