 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn-Average Stability of Multipass Preconditioned SGD and Effective Dimension
Mar 12, 2026We study trade-offs between the population risk curvature, geometry of the noise, and preconditioning on the generalisation ability of the multipass Preconditioned Stochastic Gradient Descent (PSGD). Many practical optimisation heuristics implicitly navigate this trade-off in different ways -- for instance, some aim to whiten gradient noise, while others aim to align updates with expected loss curvature. When the geometry of the population risk curvature and the geometry of the gradient noise do not match, an aggressive choice that improves one aspect can amplify instability along the other, leading to suboptimal statistical behavior. In this paper we employ on-average algorithmic stability to connect generalisation of PSGD to the effective dimension that depends on these sources of curvature. While existing techniques for on-average stability of SGD are limited to a single pass, as first contribution we develop a new on-average stability analysis for multipass SGD that handles the correlations induced by data reuse. This allows us to derive excess risk bounds that depend on the effective dimension. In particular, we show that an improperly chosen preconditioner can yield suboptimal effective dimension dependence in both optimisation and generalisation. Finally, we complement our upper bounds with matching, instance-dependent lower bounds.
Diffusion Models and the Manifold Hypothesis: Log-Domain Smoothing is Geometry Adaptive
Oct 02, 2025



Diffusion models have achieved state-of-the-art performance, demonstrating remarkable generalisation capabilities across diverse domains. However, the mechanisms underpinning these strong capabilities remain only partially understood. A leading conjecture, based on the manifold hypothesis, attributes this success to their ability to adapt to low-dimensional geometric structure within the data. This work provides evidence for this conjecture, focusing on how such phenomena could result from the formulation of the learning problem through score matching. We inspect the role of implicit regularisation by investigating the effect of smoothing minimisers of the empirical score matching objective. Our theoretical and empirical results confirm that smoothing the score function -- or equivalently, smoothing in the log-density domain -- produces smoothing tangential to the data manifold. In addition, we show that the manifold along which the diffusion model generalises can be controlled by choosing an appropriate smoothing.
Towards a Complete Analysis of Langevin Monte Carlo: Beyond Poincaré Inequality
Mar 07, 2023Langevin diffusions are rapidly convergent under appropriate functional inequality assumptions. Hence, it is natural to expect that with additional smoothness conditions to handle the discretization errors, their discretizations like the Langevin Monte Carlo (LMC) converge in a similar fashion. This research program was initiated by Vemapala and Wibisono (2019), who established results under log-Sobolev inequalities. Chewi et al. (2022) extended the results to handle the case of Poincar\'e inequalities. In this paper, we go beyond Poincar\'e inequalities, and push this research program to its limit. We do so by establishing upper and lower bounds for Langevin diffusions and LMC under weak Poincar\'e inequalities that are satisfied by a large class of densities including polynomially-decaying heavy-tailed densities (i.e., Cauchy-type). Our results explicitly quantify the effect of the initializer on the performance of the LMC algorithm. In particular, we show that as the tail goes from sub-Gaussian, to sub-exponential, and finally to Cauchy-like, the dependency on the initial error goes from being logarithmic, to polynomial, and then finally to being exponential. This three-step phase transition is in particular unavoidable as demonstrated by our lower bounds, clearly defining the boundaries of LMC.
Mean-Square Analysis of Discretized Itô Diffusions for Heavy-tailed Sampling
Mar 01, 2023We analyze the complexity of sampling from a class of heavy-tailed distributions by discretizing a natural class of It\^o diffusions associated with weighted Poincar\'e inequalities. Based on a mean-square analysis, we establish the iteration complexity for obtaining a sample whose distribution is $\epsilon$ close to the target distribution in the Wasserstein-2 metric. In this paper, our results take the mean-square analysis to its limits, i.e., we invariably only require that the target density has finite variance, the minimal requirement for a mean-square analysis. To obtain explicit estimates, we compute upper bounds on certain moments associated with heavy-tailed targets under various assumptions. We also provide similar iteration complexity results for the case where only function evaluations of the unnormalized target density are available by estimating the gradients using a Gaussian smoothing technique. We provide illustrative examples based on the multivariate $t$-distribution.
Time-independent Generalization Bounds for SGLD in Non-convex Settings
Nov 25, 2021
We establish generalization error bounds for stochastic gradient Langevin dynamics (SGLD) with constant learning rate under the assumptions of dissipativity and smoothness, a setting that has received increased attention in the sampling/optimization literature. Unlike existing bounds for SGLD in non-convex settings, ours are time-independent and decay to zero as the sample size increases. Using the framework of uniform stability, we establish time-independent bounds by exploiting the Wasserstein contraction property of the Langevin diffusion, which also allows us to circumvent the need to bound gradients using Lipschitz-like assumptions. Our analysis also supports variants of SGLD that use different discretization methods, incorporate Euclidean projections, or use non-isotropic noise.
Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
May 18, 2020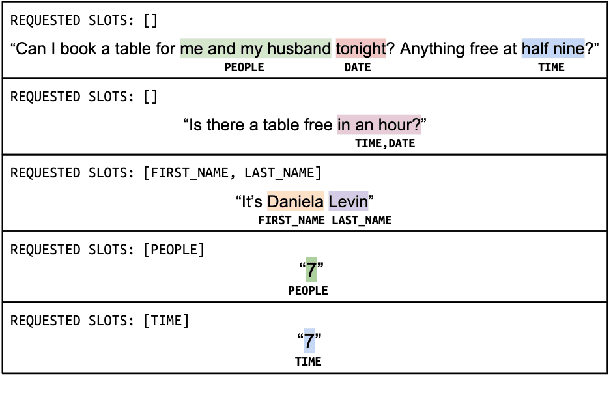

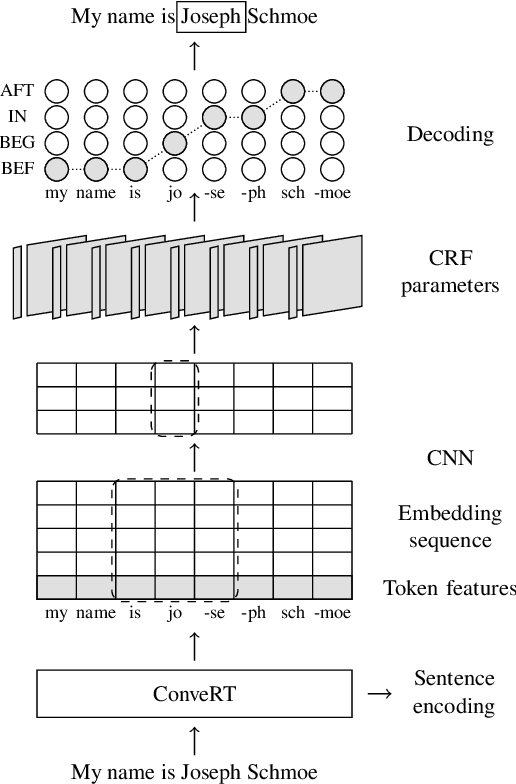

We introduce Span-ConveRT, a light-weight model for dialog slot-filling which frames the task as a turn-based span extraction task. This formulation allows for a simple integration of conversational knowledge coded in large pretrained conversational models such as ConveRT (Henderson et al., 2019). We show that leveraging such knowledge in Span-ConveRT is especially useful for few-shot learning scenarios: we report consistent gains over 1) a span extractor that trains representations from scratch in the target domain, and 2) a BERT-based span extractor. In order to inspire more work on span extraction for the slot-filling task, we also release RESTAURANTS-8K, a new challenging data set of 8,198 utterances, compiled from actual conversations in the restaurant booking domain.