 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNRGPT: An Energy-based Alternative for GPT
Dec 18, 2025



Generative Pre-trained Transformer (GPT) architectures are the most popular design for language modeling. Energy-based modeling is a different paradigm that views inference as a dynamical process operating on an energy landscape. We propose a minimal modification of the GPT setting to unify it with the EBM framework. The inference step of our model, which we call eNeRgy-GPT (NRGPT), is conceptualized as an exploration of the tokens on the energy landscape. We prove, and verify empirically, that under certain circumstances this exploration becomes gradient descent, although they don't necessarily lead to the best performing models. We demonstrate that our model performs well for simple language (Shakespeare dataset), algebraic ListOPS tasks, and richer settings such as OpenWebText language modeling. We also observe that our models may be more resistant to overfitting, doing so only during very long training.
Modern Methods in Associative Memory
Jul 08, 2025Associative Memories like the famous Hopfield Networks are elegant models for describing fully recurrent neural networks whose fundamental job is to store and retrieve information. In the past few years they experienced a surge of interest due to novel theoretical results pertaining to their information storage capabilities, and their relationship with SOTA AI architectures, such as Transformers and Diffusion Models. These connections open up possibilities for interpreting the computation of traditional AI networks through the theoretical lens of Associative Memories. Additionally, novel Lagrangian formulations of these networks make it possible to design powerful distributed models that learn useful representations and inform the design of novel architectures. This tutorial provides an approachable introduction to Associative Memories, emphasizing the modern language and methods used in this area of research, with practical hands-on mathematical derivations and coding notebooks.
Dense Associative Memory with Epanechnikov Energy
Jun 12, 2025We propose a novel energy function for Dense Associative Memory (DenseAM) networks, the log-sum-ReLU (LSR), inspired by optimal kernel density estimation. Unlike the common log-sum-exponential (LSE) function, LSR is based on the Epanechnikov kernel and enables exact memory retrieval with exponential capacity without requiring exponential separation functions. Moreover, it introduces abundant additional \emph{emergent} local minima while preserving perfect pattern recovery -- a characteristic previously unseen in DenseAM literature. Empirical results show that LSR energy has significantly more local minima (memories) that have comparable log-likelihood to LSE-based models. Analysis of LSR's emergent memories on image datasets reveals a degree of creativity and novelty, hinting at this method's potential for both large-scale memory storage and generative tasks.
Small Models, Smarter Learning: The Power of Joint Task Training
May 23, 2025The ability of a model to learn a task depends strongly on both the task difficulty and the model size. We aim to understand how task difficulty relates to the minimum number of parameters required for learning specific tasks in small transformer models. Our study focuses on the ListOps dataset, which consists of nested mathematical operations. We gradually increase task difficulty by introducing new operations or combinations of operations into the training data. We observe that sum modulo n is the hardest to learn. Curiously, when combined with other operations such as maximum and median, the sum operation becomes easier to learn and requires fewer parameters. We show that joint training not only improves performance but also leads to qualitatively different model behavior. We show evidence that models trained only on SUM might be memorizing and fail to capture the number structure in the embeddings. In contrast, models trained on a mixture of SUM and other operations exhibit number-like representations in the embedding space, and a strong ability to distinguish parity. Furthermore, the SUM-only model relies more heavily on its feedforward layers, while the jointly trained model activates the attention mechanism more. Finally, we show that learning pure SUM can be induced in models below the learning threshold of pure SUM, by pretraining them on MAX+MED. Our findings indicate that emergent abilities in language models depend not only on model size, but also the training curriculum.
Dense Associative Memory Through the Lens of Random Features
Oct 31, 2024

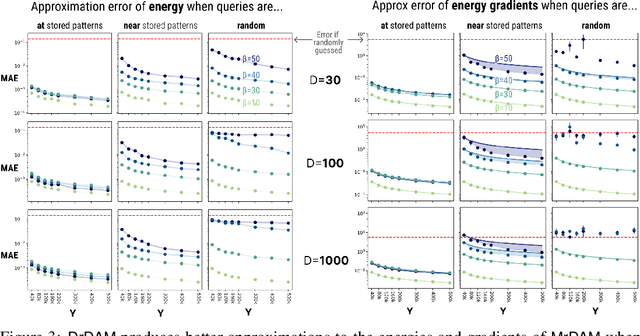
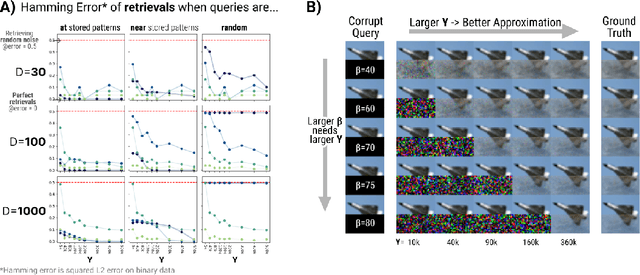
Dense Associative Memories are high storage capacity variants of the Hopfield networks that are capable of storing a large number of memory patterns in the weights of the network of a given size. Their common formulations typically require storing each pattern in a separate set of synaptic weights, which leads to the increase of the number of synaptic weights when new patterns are introduced. In this work we propose an alternative formulation of this class of models using random features, commonly used in kernel methods. In this formulation the number of network's parameters remains fixed. At the same time, new memories can be added to the network by modifying existing weights. We show that this novel network closely approximates the energy function and dynamics of conventional Dense Associative Memories and shares their desirable computational properties.
Transformer Explainer: Interactive Learning of Text-Generative Models
Aug 08, 2024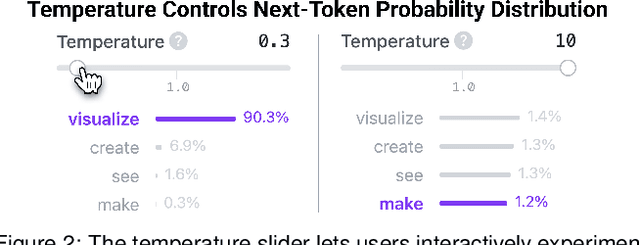
Transformers have revolutionized machine learning, yet their inner workings remain opaque to many. We present Transformer Explainer, an interactive visualization tool designed for non-experts to learn about Transformers through the GPT-2 model. Our tool helps users understand complex Transformer concepts by integrating a model overview and enabling smooth transitions across abstraction levels of mathematical operations and model structures. It runs a live GPT-2 instance locally in the user's browser, empowering users to experiment with their own input and observe in real-time how the internal components and parameters of the Transformer work together to predict the next tokens. Our tool requires no installation or special hardware, broadening the public's education access to modern generative AI techniques. Our open-sourced tool is available at https://poloclub.github.io/transformer-explainer/. A video demo is available at https://youtu.be/ECR4oAwocjs.
Interactive Visual Learning for Stable Diffusion
Apr 22, 2024Diffusion-based generative models' impressive ability to create convincing images has garnered global attention. However, their complex internal structures and operations often pose challenges for non-experts to grasp. We introduce Diffusion Explainer, the first interactive visualization tool designed to elucidate how Stable Diffusion transforms text prompts into images. It tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations. This integration enables users to fluidly transition between multiple levels of abstraction through animations and interactive elements. Offering real-time hands-on experience, Diffusion Explainer allows users to adjust Stable Diffusion's hyperparameters and prompts without the need for installation or specialized hardware. Accessible via users' web browsers, Diffusion Explainer is making significant strides in democratizing AI education, fostering broader public access. More than 7,200 users spanning 113 countries have used our open-sourced tool at https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/MbkIADZjPnA.
Memory in Plain Sight: A Survey of the Uncanny Resemblances between Diffusion Models and Associative Memories
Sep 28, 2023


Diffusion Models (DMs) have recently set state-of-the-art on many generation benchmarks. However, there are myriad ways to describe them mathematically, which makes it difficult to develop a simple understanding of how they work. In this survey, we provide a concise overview of DMs from the perspective of dynamical systems and Ordinary Differential Equations (ODEs) which exposes a mathematical connection to the highly related yet often overlooked class of energy-based models, called Associative Memories (AMs). Energy-based AMs are a theoretical framework that behave much like denoising DMs, but they enable us to directly compute a Lyapunov energy function on which we can perform gradient descent to denoise data. We then summarize the 40 year history of energy-based AMs, beginning with the original Hopfield Network, and discuss new research directions for AMs and DMs that are revealed by characterizing the extent of their similarities and differences
Diffusion Explainer: Visual Explanation for Text-to-image Stable Diffusion
May 08, 2023


Diffusion-based generative models' impressive ability to create convincing images has captured global attention. However, their complex internal structures and operations often make them difficult for non-experts to understand. We present Diffusion Explainer, the first interactive visualization tool that explains how Stable Diffusion transforms text prompts into images. Diffusion Explainer tightly integrates a visual overview of Stable Diffusion's complex components with detailed explanations of their underlying operations, enabling users to fluidly transition between multiple levels of abstraction through animations and interactive elements. By comparing the evolutions of image representations guided by two related text prompts over refinement timesteps, users can discover the impact of prompts on image generation. Diffusion Explainer runs locally in users' web browsers without the need for installation or specialized hardware, broadening the public's education access to modern AI techniques. Our open-sourced tool is available at: https://poloclub.github.io/diffusion-explainer/. A video demo is available at https://youtu.be/Zg4gxdIWDds.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.