 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFacilitating Human-LLM Collaboration through Factuality Scores and Source Attributions
May 30, 2024



While humans increasingly rely on large language models (LLMs), they are susceptible to generating inaccurate or false information, also known as "hallucinations". Technical advancements have been made in algorithms that detect hallucinated content by assessing the factuality of the model's responses and attributing sections of those responses to specific source documents. However, there is limited research on how to effectively communicate this information to users in ways that will help them appropriately calibrate their trust toward LLMs. To address this issue, we conducted a scenario-based study (N=104) to systematically compare the impact of various design strategies for communicating factuality and source attribution on participants' ratings of trust, preferences, and ease in validating response accuracy. Our findings reveal that participants preferred a design in which phrases within a response were color-coded based on the computed factuality scores. Additionally, participants increased their trust ratings when relevant sections of the source material were highlighted or responses were annotated with reference numbers corresponding to those sources, compared to when they received no annotation in the source material. Our study offers practical design guidelines to facilitate human-LLM collaboration and it promotes a new human role to carefully evaluate and take responsibility for their use of LLM outputs.
Helping the Helper: Supporting Peer Counselors via AI-Empowered Practice and Feedback
May 15, 2023Millions of users come to online peer counseling platforms to seek support on diverse topics ranging from relationship stress to anxiety. However, studies show that online peer support groups are not always as effective as expected largely due to users' negative experiences with unhelpful counselors. Peer counselors are key to the success of online peer counseling platforms, but most of them often do not have systematic ways to receive guidelines or supervision. In this work, we introduce CARE: an interactive AI-based tool to empower peer counselors through automatic suggestion generation. During the practical training stage, CARE helps diagnose which specific counseling strategies are most suitable in the given context and provides tailored example responses as suggestions. Counselors can choose to select, modify, or ignore any suggestion before replying to the support seeker. Building upon the Motivational Interviewing framework, CARE utilizes large-scale counseling conversation data together with advanced natural language generation techniques to achieve these functionalities. We demonstrate the efficacy of CARE by performing both quantitative evaluations and qualitative user studies through simulated chats and semi-structured interviews. We also find that CARE especially helps novice counselors respond better in challenging situations.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.
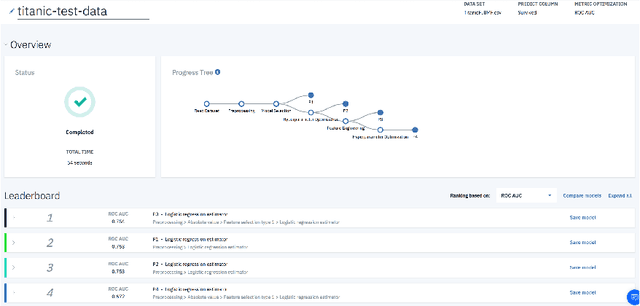
AutoDS: Towards Human-Centered Automation of Data Science
Jan 13, 2021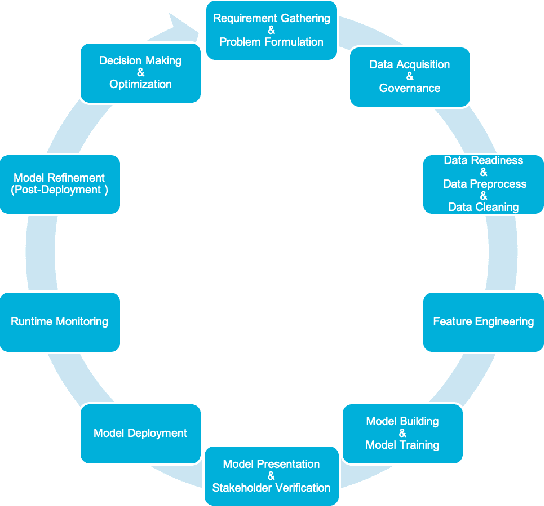
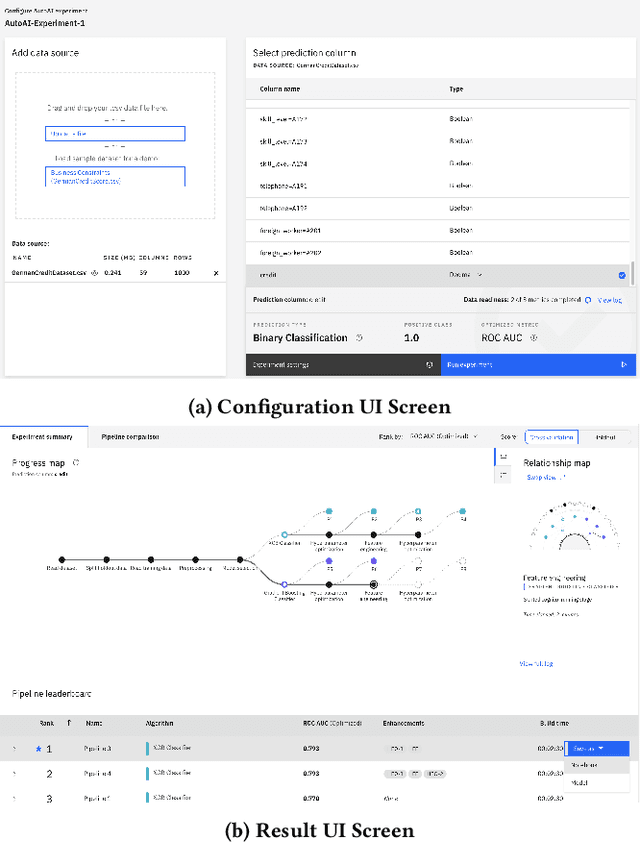
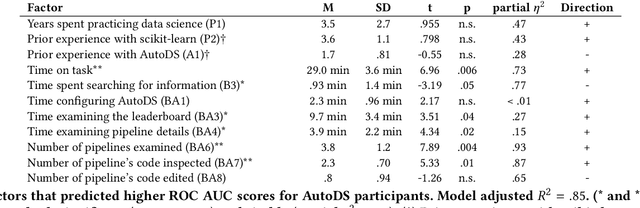
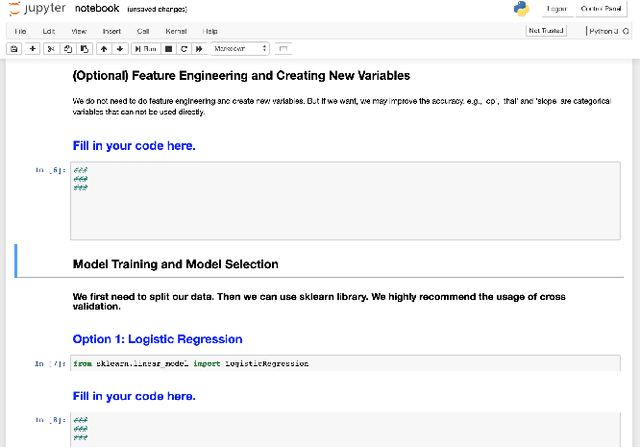
Data science (DS) projects often follow a lifecycle that consists of laborious tasks for data scientists and domain experts (e.g., data exploration, model training, etc.). Only till recently, machine learning(ML) researchers have developed promising automation techniques to aid data workers in these tasks. This paper introduces AutoDS, an automated machine learning (AutoML) system that aims to leverage the latest ML automation techniques to support data science projects. Data workers only need to upload their dataset, then the system can automatically suggest ML configurations, preprocess data, select algorithm, and train the model. These suggestions are presented to the user via a web-based graphical user interface and a notebook-based programming user interface. We studied AutoDS with 30 professional data scientists, where one group used AutoDS, and the other did not, to complete a data science project. As expected, AutoDS improves productivity; Yet surprisingly, we find that the models produced by the AutoDS group have higher quality and less errors, but lower human confidence scores. We reflect on the findings by presenting design implications for incorporating automation techniques into human work in the data science lifecycle.
How Data Scientists Work Together With Domain Experts in Scientific Collaborations: To Find The Right Answer Or To Ask The Right Question?
Sep 08, 2019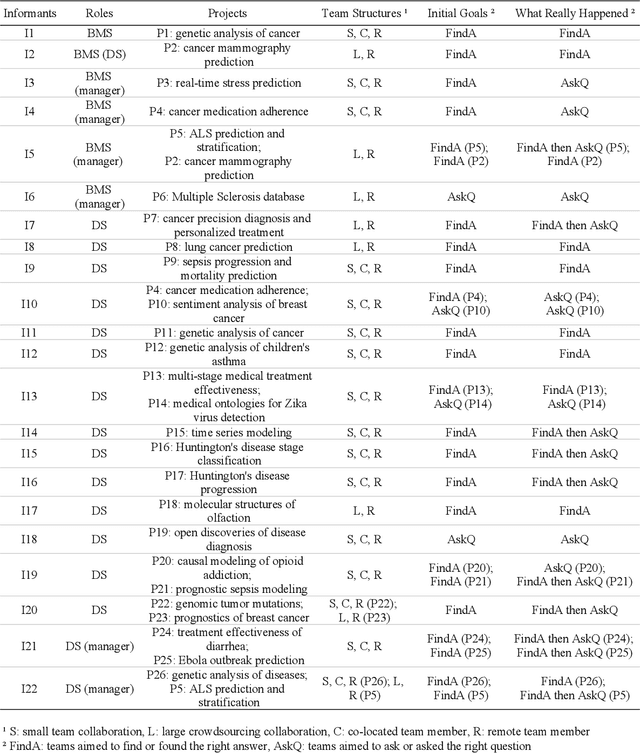

In recent years there has been an increasing trend in which data scientists and domain experts work together to tackle complex scientific questions. However, such collaborations often face challenges. In this paper, we aim to decipher this collaboration complexity through a semi-structured interview study with 22 interviewees from teams of bio-medical scientists collaborating with data scientists. In the analysis, we adopt the Olsons' four-dimensions framework proposed in Distance Matters to code interview transcripts. Our findings suggest that besides the glitches in the collaboration readiness, technology readiness, and coupling of work dimensions, the tensions that exist in the common ground building process influence the collaboration outcomes, and then persist in the actual collaboration process. In contrast to prior works' general account of building a high level of common ground, the breakdowns of content common ground together with the strengthen of process common ground in this process is more beneficial for scientific discovery. We discuss why that is and what the design suggestions are, and conclude the paper with future directions and limitations.
Human-AI Collaboration in Data Science: Exploring Data Scientists' Perceptions of Automated AI
Sep 05, 2019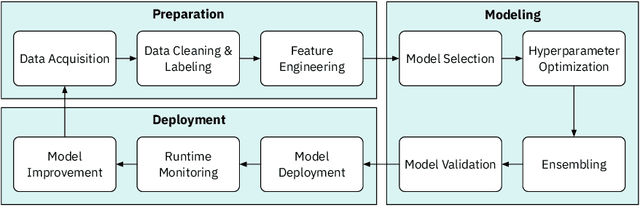
The rapid advancement of artificial intelligence (AI) is changing our lives in many ways. One application domain is data science. New techniques in automating the creation of AI, known as AutoAI or AutoML, aim to automate the work practices of data scientists. AutoAI systems are capable of autonomously ingesting and pre-processing data, engineering new features, and creating and scoring models based on a target objectives (e.g. accuracy or run-time efficiency). Though not yet widely adopted, we are interested in understanding how AutoAI will impact the practice of data science. We conducted interviews with 20 data scientists who work at a large, multinational technology company and practice data science in various business settings. Our goal is to understand their current work practices and how these practices might change with AutoAI. Reactions were mixed: while informants expressed concerns about the trend of automating their jobs, they also strongly felt it was inevitable. Despite these concerns, they remained optimistic about their future job security due to a view that the future of data science work will be a collaboration between humans and AI systems, in which both automation and human expertise are indispensable.