 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCURL: Simple Contrastive User Representation Learning from Command Sequences
Jul 29, 2022

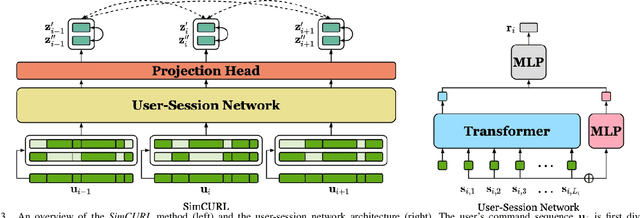

User modeling is crucial to understanding user behavior and essential for improving user experience and personalized recommendations. When users interact with software, vast amounts of command sequences are generated through logging and analytics systems. These command sequences contain clues to the users' goals and intents. However, these data modalities are highly unstructured and unlabeled, making it difficult for standard predictive systems to learn from. We propose SimCURL, a simple yet effective contrastive self-supervised deep learning framework that learns user representation from unlabeled command sequences. Our method introduces a user-session network architecture, as well as session dropout as a novel way of data augmentation. We train and evaluate our method on a real-world command sequence dataset of more than half a billion commands. Our method shows significant improvement over existing methods when the learned representation is transferred to downstream tasks such as experience and expertise classification.
How Data Scientists Work Together With Domain Experts in Scientific Collaborations: To Find The Right Answer Or To Ask The Right Question?
Sep 08, 2019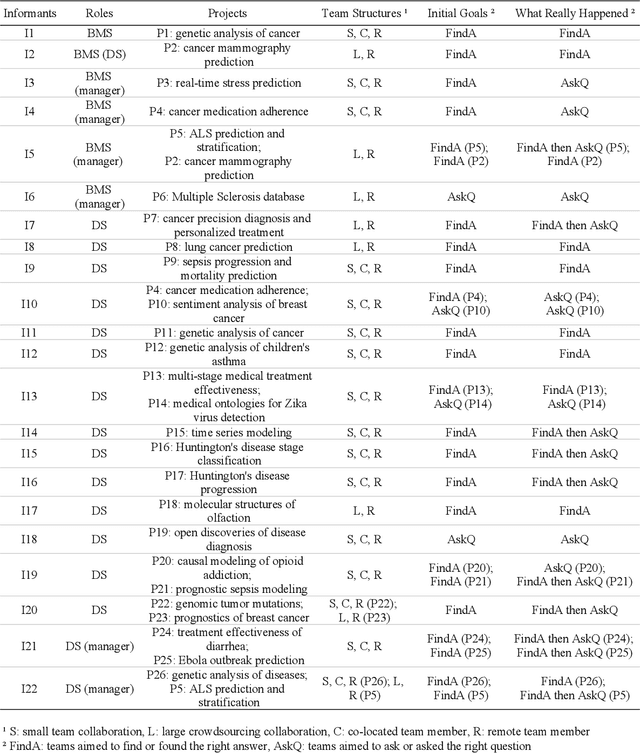

In recent years there has been an increasing trend in which data scientists and domain experts work together to tackle complex scientific questions. However, such collaborations often face challenges. In this paper, we aim to decipher this collaboration complexity through a semi-structured interview study with 22 interviewees from teams of bio-medical scientists collaborating with data scientists. In the analysis, we adopt the Olsons' four-dimensions framework proposed in Distance Matters to code interview transcripts. Our findings suggest that besides the glitches in the collaboration readiness, technology readiness, and coupling of work dimensions, the tensions that exist in the common ground building process influence the collaboration outcomes, and then persist in the actual collaboration process. In contrast to prior works' general account of building a high level of common ground, the breakdowns of content common ground together with the strengthen of process common ground in this process is more beneficial for scientific discovery. We discuss why that is and what the design suggestions are, and conclude the paper with future directions and limitations.