 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerate, Evaluate, Iterate: Synthetic Data for Human-in-the-Loop Refinement of LLM Judges
Nov 06, 2025The LLM-as-a-judge paradigm enables flexible, user-defined evaluation, but its effectiveness is often limited by the scarcity of diverse, representative data for refining criteria. We present a tool that integrates synthetic data generation into the LLM-as-a-judge workflow, empowering users to create tailored and challenging test cases with configurable domains, personas, lengths, and desired outcomes, including borderline cases. The tool also supports AI-assisted inline editing of existing test cases. To enhance transparency and interpretability, it reveals the prompts and explanations behind each generation. In a user study (N=24), 83% of participants preferred the tool over manually creating or selecting test cases, as it allowed them to rapidly generate diverse synthetic data without additional workload. The generated synthetic data proved as effective as hand-crafted data for both refining evaluation criteria and aligning with human preferences. These findings highlight synthetic data as a promising alternative, particularly in contexts where efficiency and scalability are critical.
A Case Study Investigating the Role of Generative AI in Quality Evaluations of Epics in Agile Software Development
May 12, 2025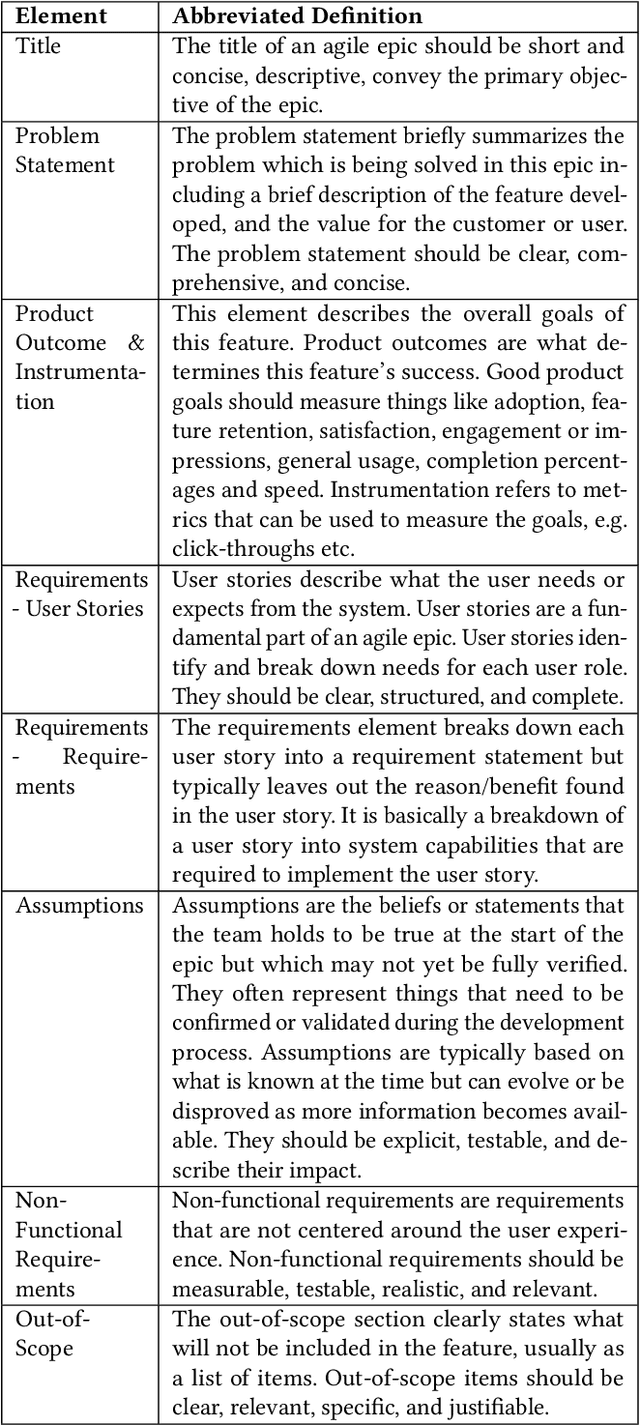
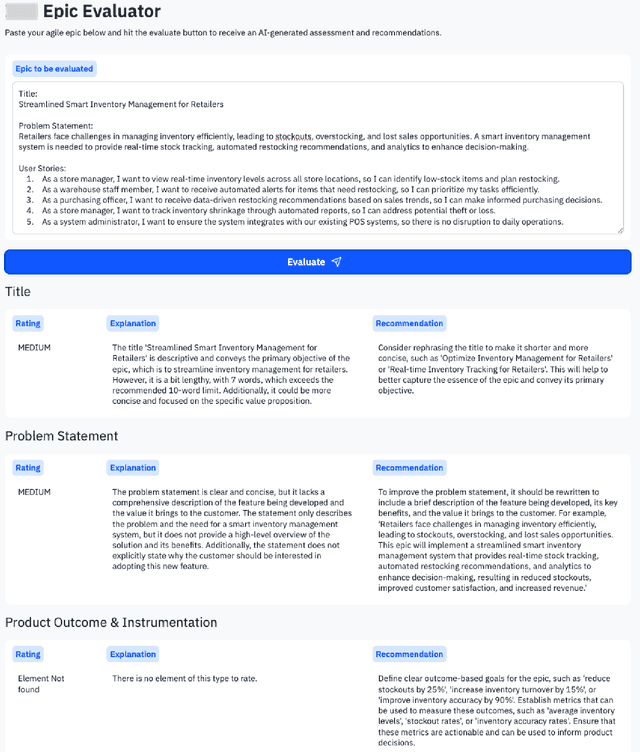
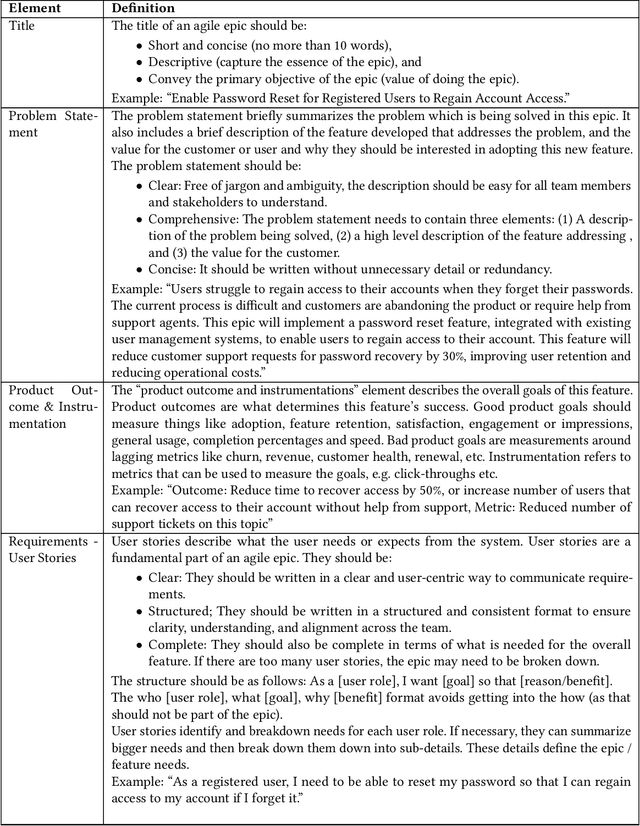
The broad availability of generative AI offers new opportunities to support various work domains, including agile software development. Agile epics are a key artifact for product managers to communicate requirements to stakeholders. However, in practice, they are often poorly defined, leading to churn, delivery delays, and cost overruns. In this industry case study, we investigate opportunities for large language models (LLMs) to evaluate agile epic quality in a global company. Results from a user study with 17 product managers indicate how LLM evaluations could be integrated into their work practices, including perceived values and usage in improving their epics. High levels of satisfaction indicate that agile epics are a new, viable application of AI evaluations. However, our findings also outline challenges, limitations, and adoption barriers that can inform both practitioners and researchers on the integration of such evaluations into future agile work practices.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Can Large Language Models Adapt to Other Agents In-Context?
Dec 27, 2024As the research community aims to build better AI assistants that are more dynamic and personalized to the diversity of humans that they interact with, there is increased interest in evaluating the theory of mind capabilities of large language models (LLMs). Indeed, several recent studies suggest that LLM theory of mind capabilities are quite impressive, approximating human-level performance. Our paper aims to rebuke this narrative and argues instead that past studies were not directly measuring agent performance, potentially leading to findings that are illusory in nature as a result. We draw a strong distinction between what we call literal theory of mind i.e. measuring the agent's ability to predict the behavior of others and functional theory of mind i.e. adapting to agents in-context based on a rational response to predictions of their behavior. We find that top performing open source LLMs may display strong capabilities in literal theory of mind, depending on how they are prompted, but seem to struggle with functional theory of mind -- even when partner policies are exceedingly simple. Our work serves to highlight the double sided nature of inductive bias in LLMs when adapting to new situations. While this bias can lead to strong performance over limited horizons, it often hinders convergence to optimal long-term behavior.
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
Oct 15, 2024
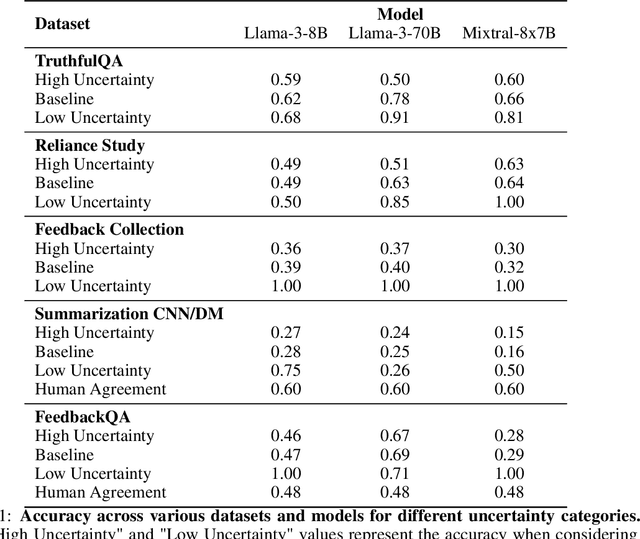
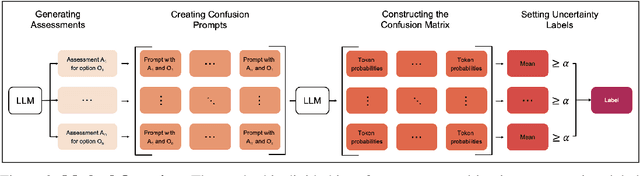

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.
Helping the Helper: Supporting Peer Counselors via AI-Empowered Practice and Feedback
May 15, 2023Millions of users come to online peer counseling platforms to seek support on diverse topics ranging from relationship stress to anxiety. However, studies show that online peer support groups are not always as effective as expected largely due to users' negative experiences with unhelpful counselors. Peer counselors are key to the success of online peer counseling platforms, but most of them often do not have systematic ways to receive guidelines or supervision. In this work, we introduce CARE: an interactive AI-based tool to empower peer counselors through automatic suggestion generation. During the practical training stage, CARE helps diagnose which specific counseling strategies are most suitable in the given context and provides tailored example responses as suggestions. Counselors can choose to select, modify, or ignore any suggestion before replying to the support seeker. Building upon the Motivational Interviewing framework, CARE utilizes large-scale counseling conversation data together with advanced natural language generation techniques to achieve these functionalities. We demonstrate the efficacy of CARE by performing both quantitative evaluations and qualitative user studies through simulated chats and semi-structured interviews. We also find that CARE especially helps novice counselors respond better in challenging situations.
Fairness Evaluation in Text Classification: Machine Learning Practitioner Perspectives of Individual and Group Fairness
Mar 01, 2023Mitigating algorithmic bias is a critical task in the development and deployment of machine learning models. While several toolkits exist to aid machine learning practitioners in addressing fairness issues, little is known about the strategies practitioners employ to evaluate model fairness and what factors influence their assessment, particularly in the context of text classification. Two common approaches of evaluating the fairness of a model are group fairness and individual fairness. We run a study with Machine Learning practitioners (n=24) to understand the strategies used to evaluate models. Metrics presented to practitioners (group vs. individual fairness) impact which models they consider fair. Participants focused on risks associated with underpredicting/overpredicting and model sensitivity relative to identity token manipulations. We discover fairness assessment strategies involving personal experiences or how users form groups of identity tokens to test model fairness. We provide recommendations for interactive tools for evaluating fairness in text classification.
Slack Channels Ecology in Enterprises: How Employees Collaborate Through Group Chat
Jun 04, 2019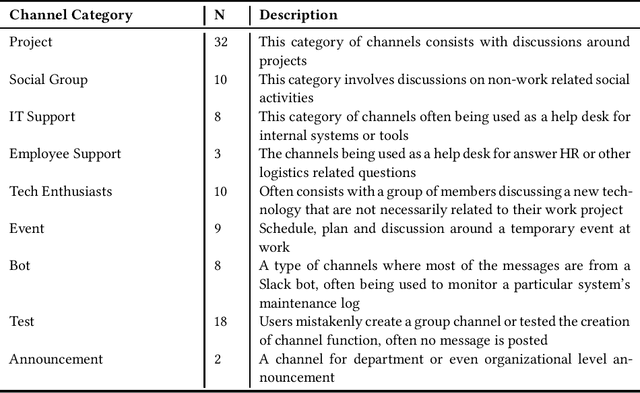
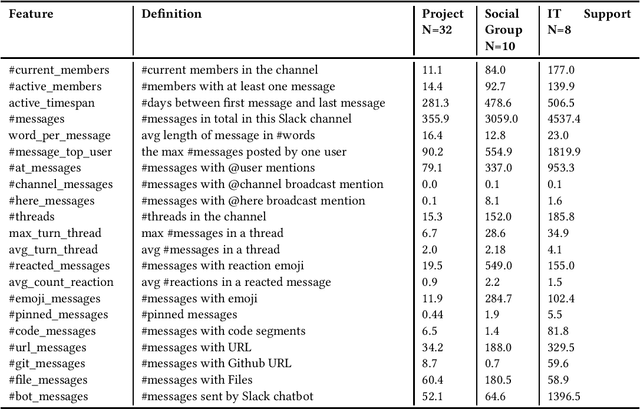

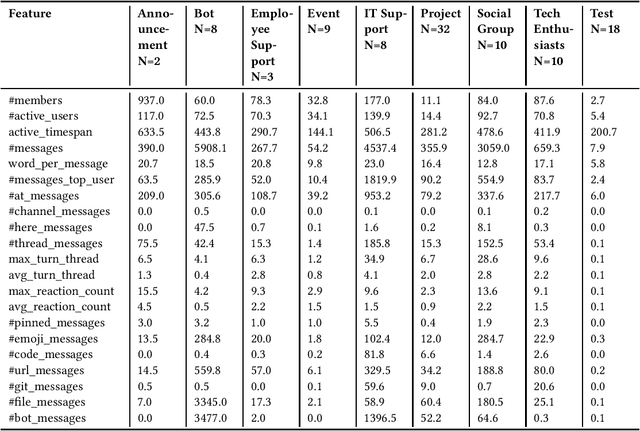
Despite the long history of studying instant messaging usage in organizations, we know very little about how today's people participate in group chat channels and interact with others. In this short note, we aim to update the existing knowledge on how group chat is used in the context of today's organizations. We have the privilege of collecting a total of 4300 publicly available group chat channels in Slack from an R\&D department in a multinational IT company. Through qualitative coding of 100 channels, we identified 9 channel categories such as project based channels and event channels. We further defined a feature metric with 21 features to depict the group communication style for these group chat channels, with which we successfully trained a machine learning model that can automatically classify a given group channel into one of the 9 categories. In addition, we illustrated how these communication metrics could be used for analyzing teams' collaboration activities. We focused on 117 project teams as we have their performance data, and further collected 54 out of the 117 teams' Slack group data and generated the communication style metrics for each of them. With these data, we are able to build a regression model to reveal the relationship between these group communication styles and one indicator of the project team performance.