 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting by Analogy: OOD Generalization of Visuomotor Policies via Functional Correspondence
Jun 15, 2025End-to-end visuomotor policies trained using behavior cloning have shown a remarkable ability to generate complex, multi-modal low-level robot behaviors. However, at deployment time, these policies still struggle to act reliably when faced with out-of-distribution (OOD) visuals induced by objects, backgrounds, or environment changes. Prior works in interactive imitation learning solicit corrective expert demonstrations under the OOD conditions -- but this can be costly and inefficient. We observe that task success under OOD conditions does not always warrant novel robot behaviors. In-distribution (ID) behaviors can directly be transferred to OOD conditions that share functional similarities with ID conditions. For example, behaviors trained to interact with in-distribution (ID) pens can apply to interacting with a visually-OOD pencil. The key challenge lies in disambiguating which ID observations functionally correspond to the OOD observation for the task at hand. We propose that an expert can provide this OOD-to-ID functional correspondence. Thus, instead of collecting new demonstrations and re-training at every OOD encounter, our method: (1) detects the need for feedback by first checking if current observations are OOD and then identifying whether the most similar training observations show divergent behaviors, (2) solicits functional correspondence feedback to disambiguate between those behaviors, and (3) intervenes on the OOD observations with the functionally corresponding ID observations to perform deployment-time generalization. We validate our method across diverse real-world robotic manipulation tasks with a Franka Panda robotic manipulator. Our results show that test-time functional correspondences can improve the generalization of a vision-based diffusion policy to OOD objects and environment conditions with low feedback.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Second-order Theory of Mind for Human Teachers and Robot Learners
Mar 17, 2025Confusing or otherwise unhelpful learner feedback creates or perpetuates erroneous beliefs that the teacher and learner have of each other, thereby increasing the cognitive burden placed upon the human teacher. For example, the robot's feedback might cause the human to misunderstand what the learner knows about the learning objective or how the learner learns. At the same time -- and in addition to the learning objective -- the learner might misunderstand how the teacher perceives the learner's task knowledge and learning processes. To ease the teaching burden, the learner should provide feedback that accounts for these misunderstandings and elicits efficient teaching from the human. This work endows an AI learner with a Second-order Theory of Mind that models perceived rationality as a source for the erroneous beliefs a teacher and learner may have of one another. It also explores how a learner can ease the teaching burden and improve teacher efficacy if it selects feedback which accounts for its model of the teacher's beliefs about the learner and its learning objective.
Bi-Directional Mental Model Reconciliation for Human-Robot Interaction with Large Language Models
Mar 10, 2025In human-robot interactions, human and robot agents maintain internal mental models of their environment, their shared task, and each other. The accuracy of these representations depends on each agent's ability to perform theory of mind, i.e. to understand the knowledge, preferences, and intentions of their teammate. When mental models diverge to the extent that it affects task execution, reconciliation becomes necessary to prevent the degradation of interaction. We propose a framework for bi-directional mental model reconciliation, leveraging large language models to facilitate alignment through semi-structured natural language dialogue. Our framework relaxes the assumption of prior model reconciliation work that either the human or robot agent begins with a correct model for the other agent to align to. Through our framework, both humans and robots are able to identify and communicate missing task-relevant context during interaction, iteratively progressing toward a shared mental model.
The Sense of Agency in Assistive Robotics Using Shared Autonomy
Jan 13, 2025Sense of agency is one factor that influences people's preferences for robot assistance and a phenomenon from cognitive science that represents the experience of control over one's environment. However, in assistive robotics literature, we often see paradigms that optimize measures like task success and cognitive load, rather than sense of agency. In fact, prior work has found that participants sometimes express a preference for paradigms, such as direct teleoperation, which do not perform well with those other metrics but give more control to the user. In this work, we focus on a subset of assistance paradigms for manipulation called shared autonomy in which the system combines control signals from the user and the automated control. We run a study to evaluate sense of agency and show that higher robot autonomy during assistance leads to improved task performance but a decreased sense of agency, indicating a potential trade-off between task performance and sense of agency. From our findings, we discuss the relation between sense of agency and optimality, and we consider a proxy metric for a component of sense of agency which might enable us to build systems that monitor and maintain sense of agency in real time.
Towards an LLM-Based Speech Interface for Robot-Assisted Feeding
Oct 27, 2024Physically assistive robots present an opportunity to significantly increase the well-being and independence of individuals with motor impairments or other forms of disability who are unable to complete activities of daily living (ADLs). Speech interfaces, especially ones that utilize Large Language Models (LLMs), can enable individuals to effectively and naturally communicate high-level commands and nuanced preferences to robots. In this work, we demonstrate an LLM-based speech interface for a commercially available assistive feeding robot. Our system is based on an iteratively designed framework, from the paper "VoicePilot: Harnessing LLMs as Speech Interfaces for Physically Assistive Robots," that incorporates human-centric elements for integrating LLMs as interfaces for robots. It has been evaluated through a user study with 11 older adults at an independent living facility. Videos are located on our project website: https://sites.google.com/andrew.cmu.edu/voicepilot/.
Conformalized Interactive Imitation Learning: Handling Expert Shift and Intermittent Feedback
Oct 11, 2024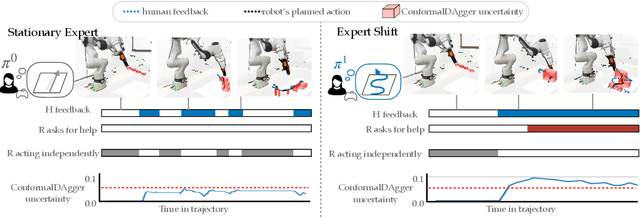

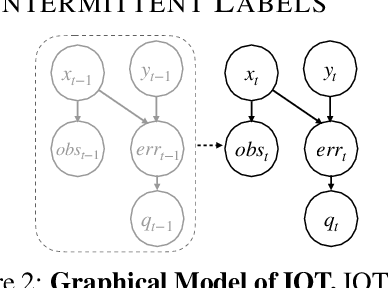

In interactive imitation learning (IL), uncertainty quantification offers a way for the learner (i.e. robot) to contend with distribution shifts encountered during deployment by actively seeking additional feedback from an expert (i.e. human) online. Prior works use mechanisms like ensemble disagreement or Monte Carlo dropout to quantify when black-box IL policies are uncertain; however, these approaches can lead to overconfident estimates when faced with deployment-time distribution shifts. Instead, we contend that we need uncertainty quantification algorithms that can leverage the expert human feedback received during deployment time to adapt the robot's uncertainty online. To tackle this, we draw upon online conformal prediction, a distribution-free method for constructing prediction intervals online given a stream of ground-truth labels. Human labels, however, are intermittent in the interactive IL setting. Thus, from the conformal prediction side, we introduce a novel uncertainty quantification algorithm called intermittent quantile tracking (IQT) that leverages a probabilistic model of intermittent labels, maintains asymptotic coverage guarantees, and empirically achieves desired coverage levels. From the interactive IL side, we develop ConformalDAgger, a new approach wherein the robot uses prediction intervals calibrated by IQT as a reliable measure of deployment-time uncertainty to actively query for more expert feedback. We compare ConformalDAgger to prior uncertainty-aware DAgger methods in scenarios where the distribution shift is (and isn't) present because of changes in the expert's policy. We find that in simulated and hardware deployments on a 7DOF robotic manipulator, ConformalDAgger detects high uncertainty when the expert shifts and increases the number of interventions compared to baselines, allowing the robot to more quickly learn the new behavior.
DegustaBot: Zero-Shot Visual Preference Estimation for Personalized Multi-Object Rearrangement
Jul 11, 2024De gustibus non est disputandum ("there is no accounting for others' tastes") is a common Latin maxim describing how many solutions in life are determined by people's personal preferences. Many household tasks, in particular, can only be considered fully successful when they account for personal preferences such as the visual aesthetic of the scene. For example, setting a table could be optimized by arranging utensils according to traditional rules of Western table setting decorum, without considering the color, shape, or material of each object, but this may not be a completely satisfying solution for a given person. Toward this end, we present DegustaBot, an algorithm for visual preference learning that solves household multi-object rearrangement tasks according to personal preference. To do this, we use internet-scale pre-trained vision-and-language foundation models (VLMs) with novel zero-shot visual prompting techniques. To evaluate our method, we collect a large dataset of naturalistic personal preferences in a simulated table-setting task, and conduct a user study in order to develop two novel metrics for determining success based on personal preference. This is a challenging problem and we find that 50% of our model's predictions are likely to be found acceptable by at least 20% of people.
Conformalized Teleoperation: Confidently Mapping Human Inputs to High-Dimensional Robot Actions
Jun 11, 2024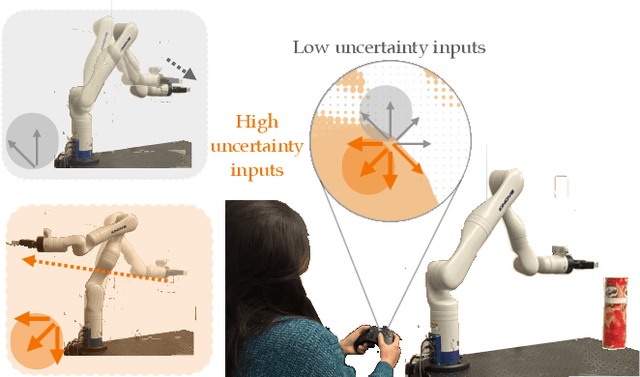
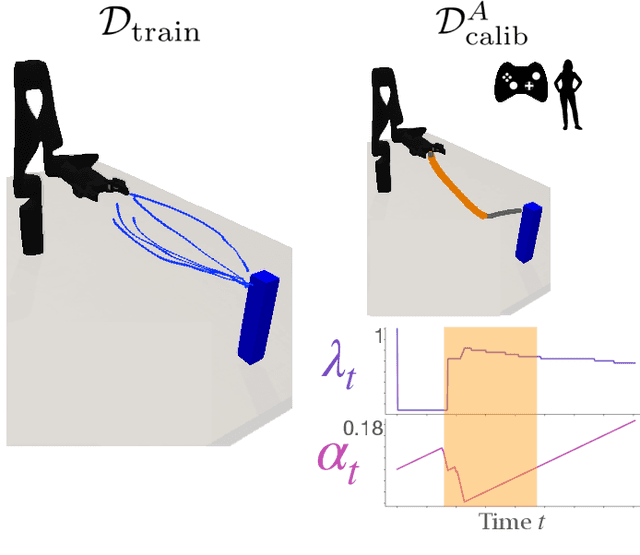
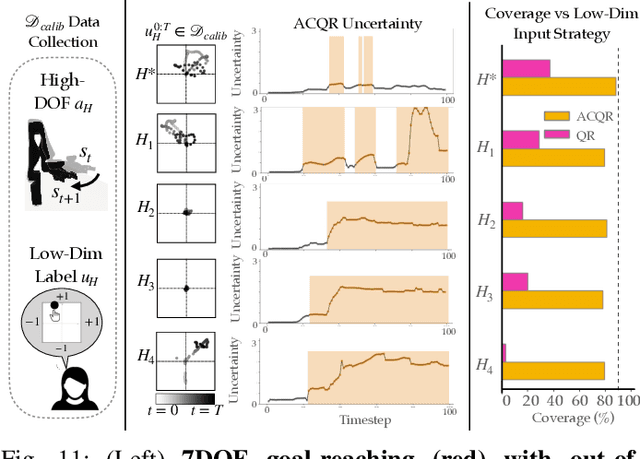
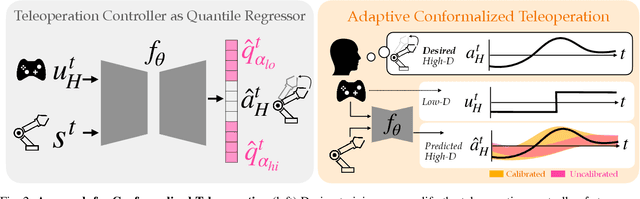
Assistive robotic arms often have more degrees-of-freedom than a human teleoperator can control with a low-dimensional input, like a joystick. To overcome this challenge, existing approaches use data-driven methods to learn a mapping from low-dimensional human inputs to high-dimensional robot actions. However, determining if such a black-box mapping can confidently infer a user's intended high-dimensional action from low-dimensional inputs remains an open problem. Our key idea is to adapt the assistive map at training time to additionally estimate high-dimensional action quantiles, and then calibrate these quantiles via rigorous uncertainty quantification methods. Specifically, we leverage adaptive conformal prediction which adjusts the intervals over time, reducing the uncertainty bounds when the mapping is performant and increasing the bounds when the mapping consistently mis-predicts. Furthermore, we propose an uncertainty-interval-based mechanism for detecting high-uncertainty user inputs and robot states. We evaluate the efficacy of our proposed approach in a 2D assistive navigation task and two 7DOF Kinova Jaco tasks involving assistive cup grasping and goal reaching. Our findings demonstrate that conformalized assistive teleoperation manages to detect (but not differentiate between) high uncertainty induced by diverse preferences and induced by low-precision trajectories in the mapping's training dataset. On the whole, we see this work as a key step towards enabling robots to quantify their own uncertainty and proactively seek intervention when needed.
Understanding Robot Minds: Leveraging Machine Teaching for Transparent Human-Robot Collaboration Across Diverse Groups
Apr 23, 2024



In this work, we aim to improve transparency and efficacy in human-robot collaboration by developing machine teaching algorithms suitable for groups with varied learning capabilities. While previous approaches focused on tailored approaches for teaching individuals, our method teaches teams with various compositions of diverse learners using team belief representations to address personalization challenges within groups. We investigate various group teaching strategies, such as focusing on individual beliefs or the group's collective beliefs, and assess their impact on learning robot policies for different team compositions. Our findings reveal that team belief strategies yield less variation in learning duration and better accommodate diverse teams compared to individual belief strategies, suggesting their suitability in mixed-proficiency settings with limited resources. Conversely, individual belief strategies provide a more uniform knowledge level, particularly effective for homogeneously inexperienced groups. Our study indicates that the teaching strategy's efficacy is significantly influenced by team composition and learner proficiency, highlighting the importance of real-time assessment of learner proficiency and adapting teaching approaches based on learner proficiency for optimal teaching outcomes.