 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDegustaBot: Zero-Shot Visual Preference Estimation for Personalized Multi-Object Rearrangement
Jul 11, 2024De gustibus non est disputandum ("there is no accounting for others' tastes") is a common Latin maxim describing how many solutions in life are determined by people's personal preferences. Many household tasks, in particular, can only be considered fully successful when they account for personal preferences such as the visual aesthetic of the scene. For example, setting a table could be optimized by arranging utensils according to traditional rules of Western table setting decorum, without considering the color, shape, or material of each object, but this may not be a completely satisfying solution for a given person. Toward this end, we present DegustaBot, an algorithm for visual preference learning that solves household multi-object rearrangement tasks according to personal preference. To do this, we use internet-scale pre-trained vision-and-language foundation models (VLMs) with novel zero-shot visual prompting techniques. To evaluate our method, we collect a large dataset of naturalistic personal preferences in a simulated table-setting task, and conduct a user study in order to develop two novel metrics for determining success based on personal preference. This is a challenging problem and we find that 50% of our model's predictions are likely to be found acceptable by at least 20% of people.
HARMONIC: A Multimodal Dataset of Assistive Human-Robot Collaboration
Jul 30, 2018
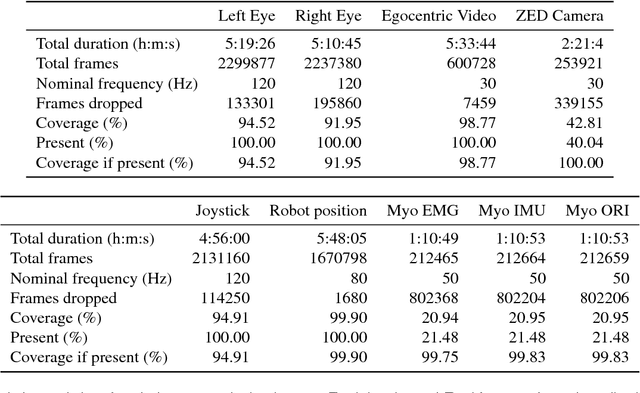
We present HARMONIC, a large multi-modal dataset of human interactions in a shared autonomy setting. The dataset provides human, robot, and environment data streams from twenty-four people engaged in an assistive eating task with a 6 degree-of-freedom (DOF) robot arm. From each participant, we recorded video of both eyes, egocentric video from a head-mounted camera, joystick commands, electromyography from the participant's forearm used to operate the joystick, third person stereo video, and the joint positions of the 6 DOF robot arm. Also included are several data streams that come as a direct result of these recordings, namely eye gaze fixations in the egocentric camera frame and body position skeletons. This dataset could be of interest to researchers studying intention prediction, human mental state modeling, and shared autonomy. Data streams are provided in a variety of formats such as video and human-readable csv or yaml files.