 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdapting by Analogy: OOD Generalization of Visuomotor Policies via Functional Correspondence
Jun 15, 2025End-to-end visuomotor policies trained using behavior cloning have shown a remarkable ability to generate complex, multi-modal low-level robot behaviors. However, at deployment time, these policies still struggle to act reliably when faced with out-of-distribution (OOD) visuals induced by objects, backgrounds, or environment changes. Prior works in interactive imitation learning solicit corrective expert demonstrations under the OOD conditions -- but this can be costly and inefficient. We observe that task success under OOD conditions does not always warrant novel robot behaviors. In-distribution (ID) behaviors can directly be transferred to OOD conditions that share functional similarities with ID conditions. For example, behaviors trained to interact with in-distribution (ID) pens can apply to interacting with a visually-OOD pencil. The key challenge lies in disambiguating which ID observations functionally correspond to the OOD observation for the task at hand. We propose that an expert can provide this OOD-to-ID functional correspondence. Thus, instead of collecting new demonstrations and re-training at every OOD encounter, our method: (1) detects the need for feedback by first checking if current observations are OOD and then identifying whether the most similar training observations show divergent behaviors, (2) solicits functional correspondence feedback to disambiguate between those behaviors, and (3) intervenes on the OOD observations with the functionally corresponding ID observations to perform deployment-time generalization. We validate our method across diverse real-world robotic manipulation tasks with a Franka Panda robotic manipulator. Our results show that test-time functional correspondences can improve the generalization of a vision-based diffusion policy to OOD objects and environment conditions with low feedback.
DegustaBot: Zero-Shot Visual Preference Estimation for Personalized Multi-Object Rearrangement
Jul 11, 2024De gustibus non est disputandum ("there is no accounting for others' tastes") is a common Latin maxim describing how many solutions in life are determined by people's personal preferences. Many household tasks, in particular, can only be considered fully successful when they account for personal preferences such as the visual aesthetic of the scene. For example, setting a table could be optimized by arranging utensils according to traditional rules of Western table setting decorum, without considering the color, shape, or material of each object, but this may not be a completely satisfying solution for a given person. Toward this end, we present DegustaBot, an algorithm for visual preference learning that solves household multi-object rearrangement tasks according to personal preference. To do this, we use internet-scale pre-trained vision-and-language foundation models (VLMs) with novel zero-shot visual prompting techniques. To evaluate our method, we collect a large dataset of naturalistic personal preferences in a simulated table-setting task, and conduct a user study in order to develop two novel metrics for determining success based on personal preference. This is a challenging problem and we find that 50% of our model's predictions are likely to be found acceptable by at least 20% of people.
Object Importance Estimation using Counterfactual Reasoning for Intelligent Driving
Dec 05, 2023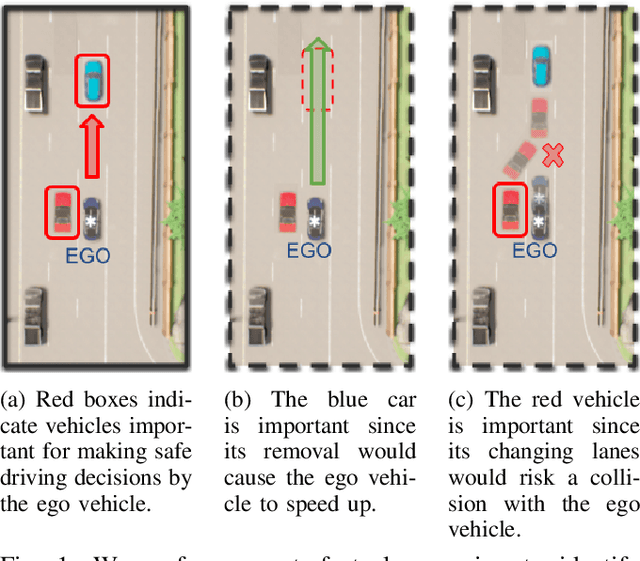
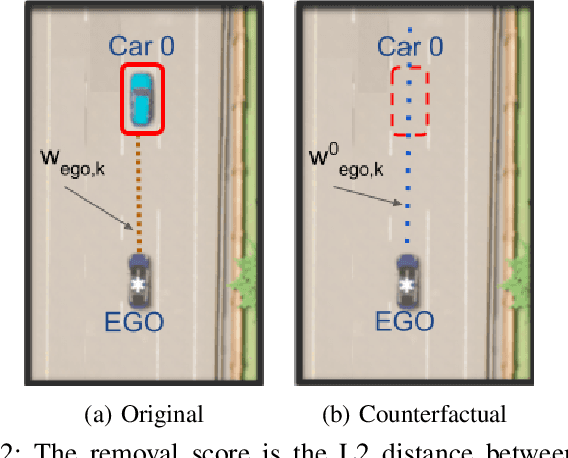
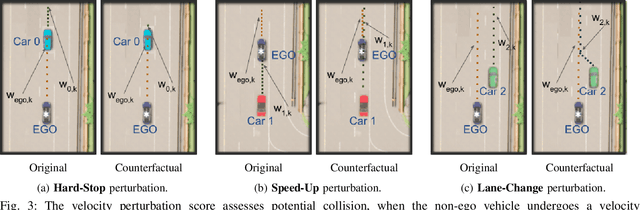
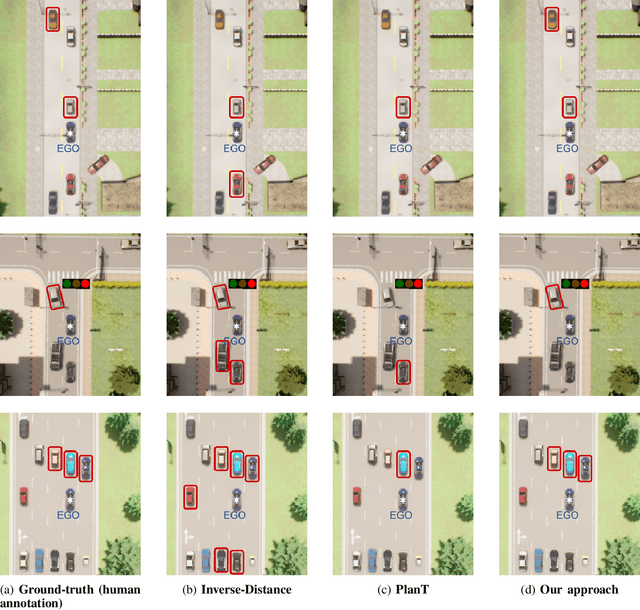
The ability to identify important objects in a complex and dynamic driving environment is essential for autonomous driving agents to make safe and efficient driving decisions. It also helps assistive driving systems decide when to alert drivers. We tackle object importance estimation in a data-driven fashion and introduce HOIST - Human-annotated Object Importance in Simulated Traffic. HOIST contains driving scenarios with human-annotated importance labels for vehicles and pedestrians. We additionally propose a novel approach that relies on counterfactual reasoning to estimate an object's importance. We generate counterfactual scenarios by modifying the motion of objects and ascribe importance based on how the modifications affect the ego vehicle's driving. Our approach outperforms strong baselines for the task of object importance estimation on HOIST. We also perform ablation studies to justify our design choices and show the significance of the different components of our proposed approach.
NEWSKVQA: Knowledge-Aware News Video Question Answering
Feb 08, 2022
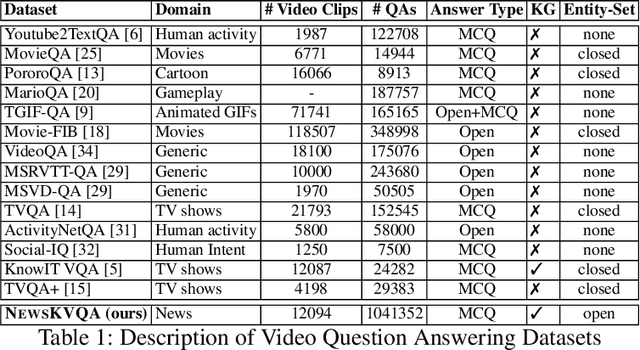
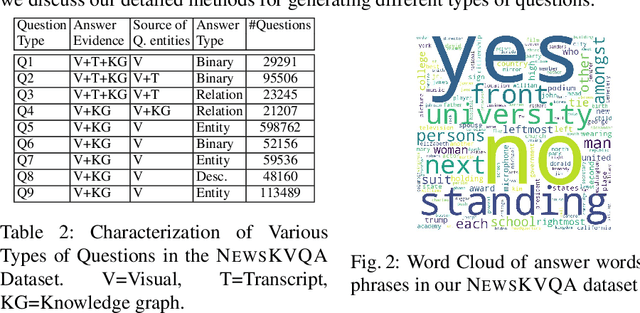
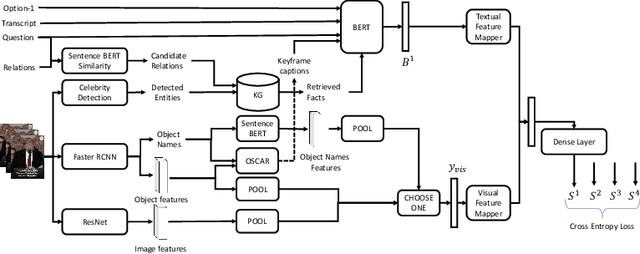
Answering questions in the context of videos can be helpful in video indexing, video retrieval systems, video summarization, learning management systems and surveillance video analysis. Although there exists a large body of work on visual question answering, work on video question answering (1) is limited to domains like movies, TV shows, gameplay, or human activity, and (2) is mostly based on common sense reasoning. In this paper, we explore a new frontier in video question answering: answering knowledge-based questions in the context of news videos. To this end, we curate a new dataset of 12K news videos spanning across 156 hours with 1M multiple-choice question-answer pairs covering 8263 unique entities. We make the dataset publicly available. Using this dataset, we propose a novel approach, NEWSKVQA (Knowledge-Aware News Video Question Answering) which performs multi-modal inferencing over textual multiple-choice questions, videos, their transcripts and knowledge base, and presents a strong baseline.
Syntactically Guided Generative Embeddings for Zero-Shot Skeleton Action Recognition
Jan 27, 2021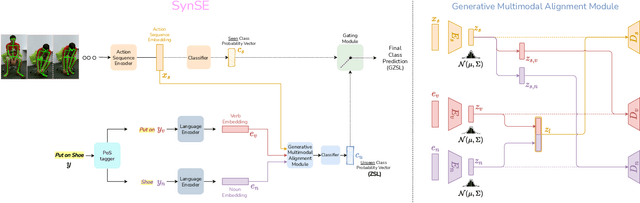
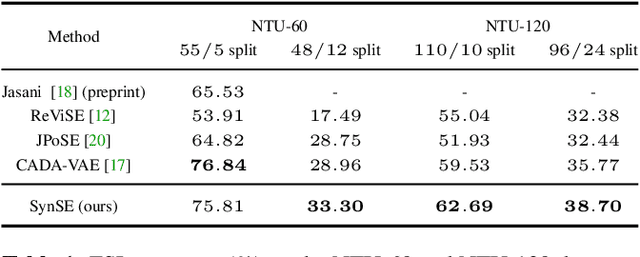
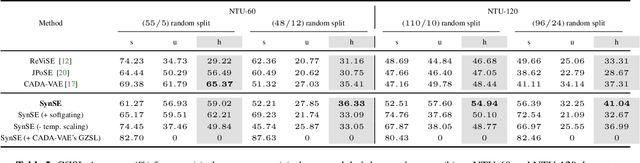
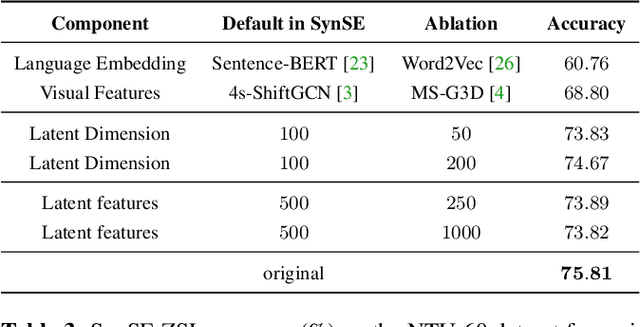
We introduce SynSE, a novel syntactically guided generative approach for Zero-Shot Learning (ZSL). Our end-to-end approach learns progressively refined generative embedding spaces constrained within and across the involved modalities (visual, language). The inter-modal constraints are defined between action sequence embedding and embeddings of Parts of Speech (PoS) tagged words in the corresponding action description. We deploy SynSE for the task of skeleton-based action sequence recognition. Our design choices enable SynSE to generalize compositionally, i.e., recognize sequences whose action descriptions contain words not encountered during training. We also extend our approach to the more challenging Generalized Zero-Shot Learning (GZSL) problem via a confidence-based gating mechanism. We are the first to present zero-shot skeleton action recognition results on the large-scale NTU-60 and NTU-120 skeleton action datasets with multiple splits. Our results demonstrate SynSE's state of the art performance in both ZSL and GZSL settings compared to strong baselines on the NTU-60 and NTU-120 datasets.
Quo Vadis, Skeleton Action Recognition ?
Jul 04, 2020
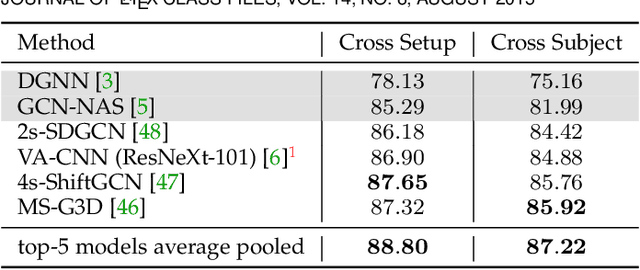
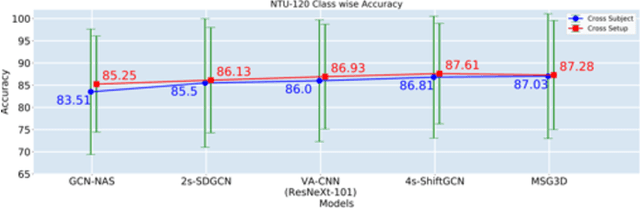
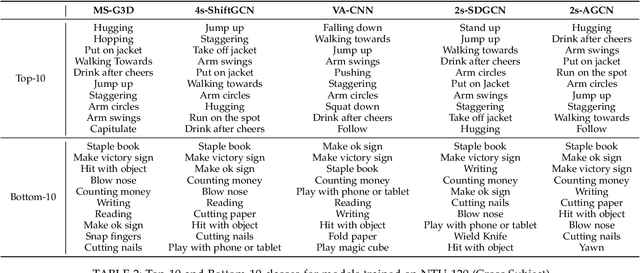
In this paper, we study current and upcoming frontiers across the landscape of skeleton-based human action recognition. To begin with, we benchmark state-of-the-art models on the NTU-120 dataset and provide multi-layered assessment of the results. To examine skeleton action recognition 'in the wild', we introduce Skeletics-152, a curated and 3-D pose-annotated subset of RGB videos sourced from Kinetics-700, a large-scale action dataset. The results from benchmarking the top performers of NTU-120 on Skeletics-152 reveal the challenges and domain gap induced by actions 'in the wild'. We extend our study to include out-of-context actions by introducing Skeleton-Mimetics, a dataset derived from the recently introduced Mimetics dataset. Finally, as a new frontier for action recognition, we introduce Metaphorics, a dataset with caption-style annotated YouTube videos of the popular social game Dumb Charades and interpretative dance performances. Overall, our work characterizes the strengths and limitations of existing approaches and datasets. It also provides an assessment of top-performing approaches across a spectrum of activity settings and via the introduced datasets, proposes new frontiers for human action recognition.