 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyntactically Guided Generative Embeddings for Zero-Shot Skeleton Action Recognition
Paper and Code
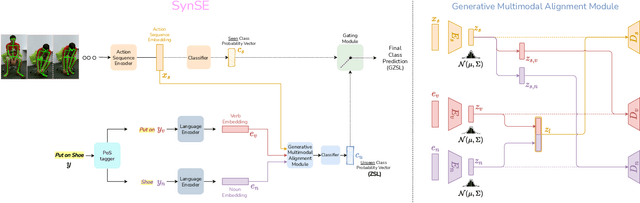
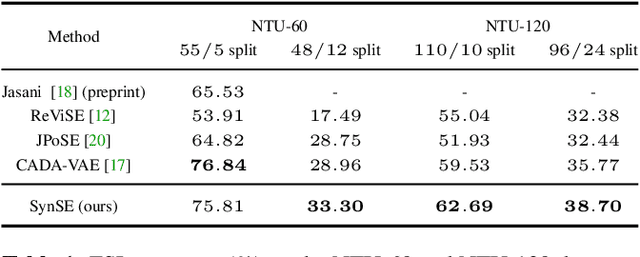
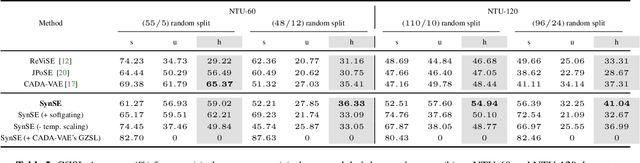
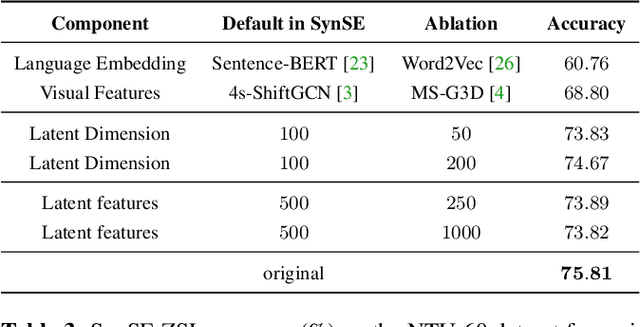
We introduce SynSE, a novel syntactically guided generative approach for Zero-Shot Learning (ZSL). Our end-to-end approach learns progressively refined generative embedding spaces constrained within and across the involved modalities (visual, language). The inter-modal constraints are defined between action sequence embedding and embeddings of Parts of Speech (PoS) tagged words in the corresponding action description. We deploy SynSE for the task of skeleton-based action sequence recognition. Our design choices enable SynSE to generalize compositionally, i.e., recognize sequences whose action descriptions contain words not encountered during training. We also extend our approach to the more challenging Generalized Zero-Shot Learning (GZSL) problem via a confidence-based gating mechanism. We are the first to present zero-shot skeleton action recognition results on the large-scale NTU-60 and NTU-120 skeleton action datasets with multiple splits. Our results demonstrate SynSE's state of the art performance in both ZSL and GZSL settings compared to strong baselines on the NTU-60 and NTU-120 datasets.