 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Interactive Learning on the Job via Facility Location Planning
May 01, 2025Collaborative robots must continually adapt to novel tasks and user preferences without overburdening the user. While prior interactive robot learning methods aim to reduce human effort, they are typically limited to single-task scenarios and are not well-suited for sustained, multi-task collaboration. We propose COIL (Cost-Optimal Interactive Learning) -- a multi-task interaction planner that minimizes human effort across a sequence of tasks by strategically selecting among three query types (skill, preference, and help). When user preferences are known, we formulate COIL as an uncapacitated facility location (UFL) problem, which enables bounded-suboptimal planning in polynomial time using off-the-shelf approximation algorithms. We extend our formulation to handle uncertainty in user preferences by incorporating one-step belief space planning, which uses these approximation algorithms as subroutines to maintain polynomial-time performance. Simulated and physical experiments on manipulation tasks show that our framework significantly reduces the amount of work allocated to the human while maintaining successful task completion.
Proceedings of 1st Workshop on Advancing Artificial Intelligence through Theory of Mind
Apr 28, 2025



This volume includes a selection of papers presented at the Workshop on Advancing Artificial Intelligence through Theory of Mind held at AAAI 2025 in Philadelphia US on 3rd March 2025. The purpose of this volume is to provide an open access and curated anthology for the ToM and AI research community.
Bi-Directional Mental Model Reconciliation for Human-Robot Interaction with Large Language Models
Mar 10, 2025In human-robot interactions, human and robot agents maintain internal mental models of their environment, their shared task, and each other. The accuracy of these representations depends on each agent's ability to perform theory of mind, i.e. to understand the knowledge, preferences, and intentions of their teammate. When mental models diverge to the extent that it affects task execution, reconciliation becomes necessary to prevent the degradation of interaction. We propose a framework for bi-directional mental model reconciliation, leveraging large language models to facilitate alignment through semi-structured natural language dialogue. Our framework relaxes the assumption of prior model reconciliation work that either the human or robot agent begins with a correct model for the other agent to align to. Through our framework, both humans and robots are able to identify and communicate missing task-relevant context during interaction, iteratively progressing toward a shared mental model.
Conformalized Interactive Imitation Learning: Handling Expert Shift and Intermittent Feedback
Oct 11, 2024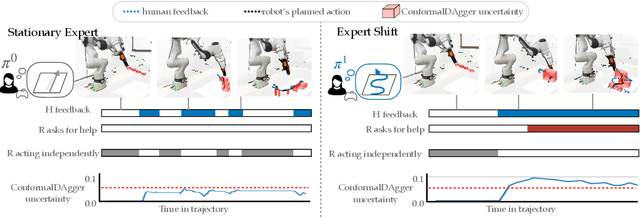

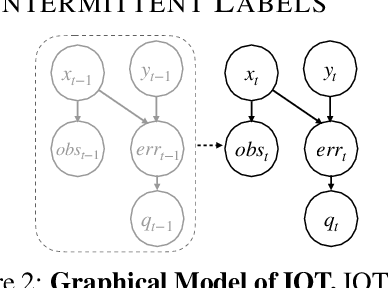

In interactive imitation learning (IL), uncertainty quantification offers a way for the learner (i.e. robot) to contend with distribution shifts encountered during deployment by actively seeking additional feedback from an expert (i.e. human) online. Prior works use mechanisms like ensemble disagreement or Monte Carlo dropout to quantify when black-box IL policies are uncertain; however, these approaches can lead to overconfident estimates when faced with deployment-time distribution shifts. Instead, we contend that we need uncertainty quantification algorithms that can leverage the expert human feedback received during deployment time to adapt the robot's uncertainty online. To tackle this, we draw upon online conformal prediction, a distribution-free method for constructing prediction intervals online given a stream of ground-truth labels. Human labels, however, are intermittent in the interactive IL setting. Thus, from the conformal prediction side, we introduce a novel uncertainty quantification algorithm called intermittent quantile tracking (IQT) that leverages a probabilistic model of intermittent labels, maintains asymptotic coverage guarantees, and empirically achieves desired coverage levels. From the interactive IL side, we develop ConformalDAgger, a new approach wherein the robot uses prediction intervals calibrated by IQT as a reliable measure of deployment-time uncertainty to actively query for more expert feedback. We compare ConformalDAgger to prior uncertainty-aware DAgger methods in scenarios where the distribution shift is (and isn't) present because of changes in the expert's policy. We find that in simulated and hardware deployments on a 7DOF robotic manipulator, ConformalDAgger detects high uncertainty when the expert shifts and increases the number of interventions compared to baselines, allowing the robot to more quickly learn the new behavior.
Conformalized Teleoperation: Confidently Mapping Human Inputs to High-Dimensional Robot Actions
Jun 11, 2024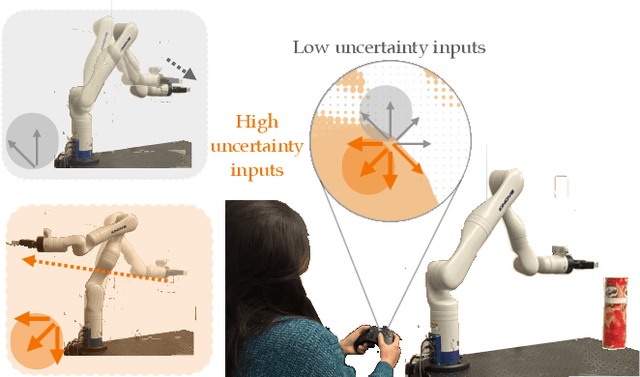
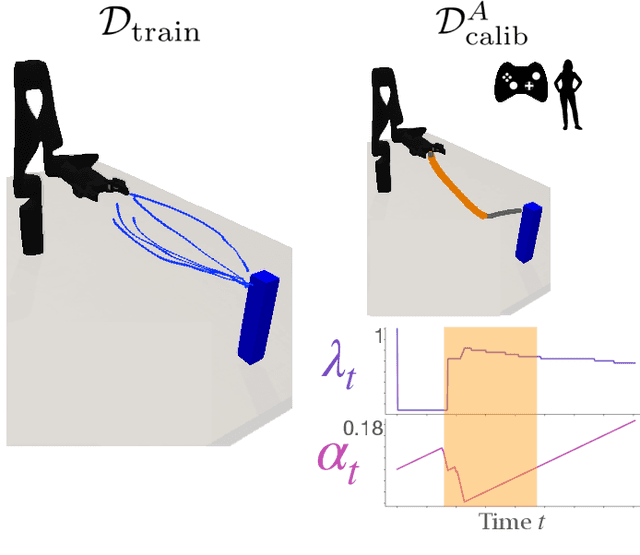
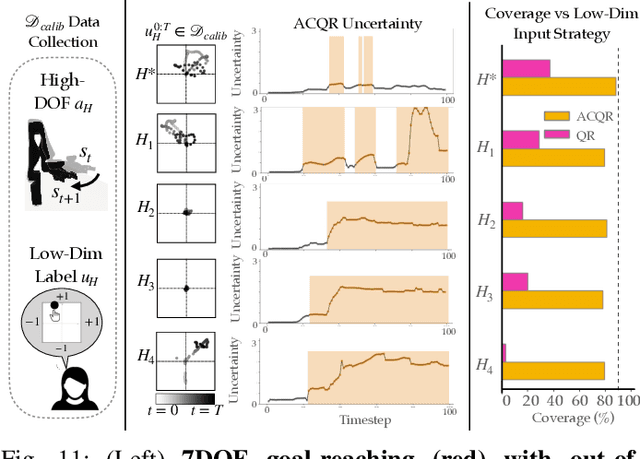
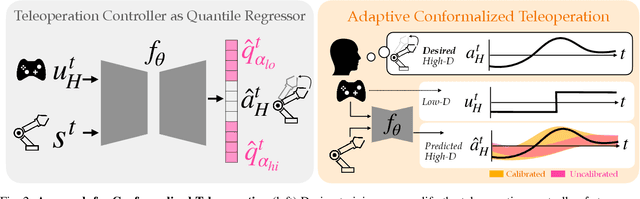
Assistive robotic arms often have more degrees-of-freedom than a human teleoperator can control with a low-dimensional input, like a joystick. To overcome this challenge, existing approaches use data-driven methods to learn a mapping from low-dimensional human inputs to high-dimensional robot actions. However, determining if such a black-box mapping can confidently infer a user's intended high-dimensional action from low-dimensional inputs remains an open problem. Our key idea is to adapt the assistive map at training time to additionally estimate high-dimensional action quantiles, and then calibrate these quantiles via rigorous uncertainty quantification methods. Specifically, we leverage adaptive conformal prediction which adjusts the intervals over time, reducing the uncertainty bounds when the mapping is performant and increasing the bounds when the mapping consistently mis-predicts. Furthermore, we propose an uncertainty-interval-based mechanism for detecting high-uncertainty user inputs and robot states. We evaluate the efficacy of our proposed approach in a 2D assistive navigation task and two 7DOF Kinova Jaco tasks involving assistive cup grasping and goal reaching. Our findings demonstrate that conformalized assistive teleoperation manages to detect (but not differentiate between) high uncertainty induced by diverse preferences and induced by low-precision trajectories in the mapping's training dataset. On the whole, we see this work as a key step towards enabling robots to quantify their own uncertainty and proactively seek intervention when needed.
Multi-Agent Strategy Explanations for Human-Robot Collaboration
Nov 20, 2023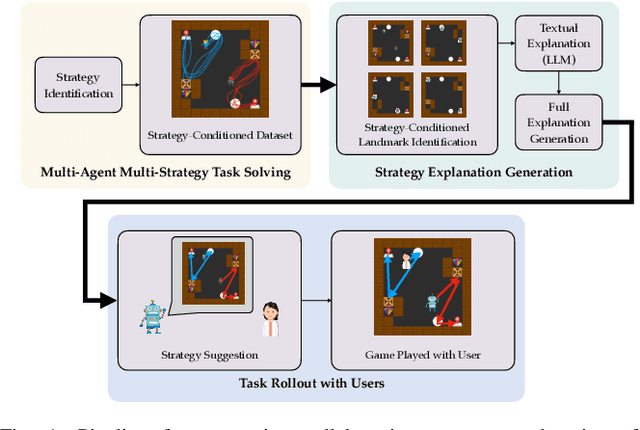
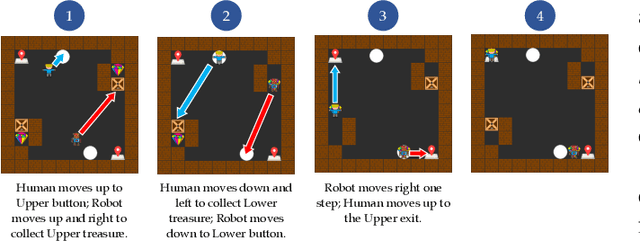
As robots are deployed in human spaces, it's important that they are able to coordinate their actions with the people around them. Part of such coordination involves ensuring that people have a good understanding of how a robot will act in the environment. This can be achieved through explanations of the robot's policy. Much prior work in explainable AI and RL focuses on generating explanations for single-agent policies, but little has been explored in generating explanations for collaborative policies. In this work, we investigate how to generate multi-agent strategy explanations for human-robot collaboration. We formulate the problem using a generic multi-agent planner, show how to generate visual explanations through strategy-conditioned landmark states and generate textual explanations by giving the landmarks to an LLM. Through a user study, we find that when presented with explanations from our proposed framework, users are able to better explore the full space of strategies and collaborate more efficiently with new robot partners.
Coordination with Humans via Strategy Matching
Nov 07, 2022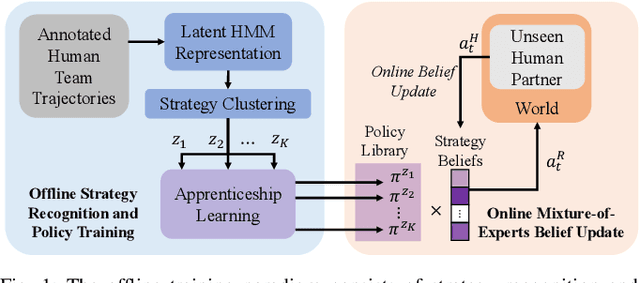
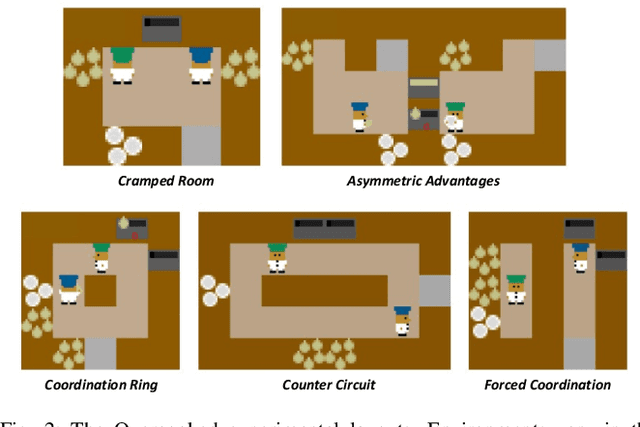
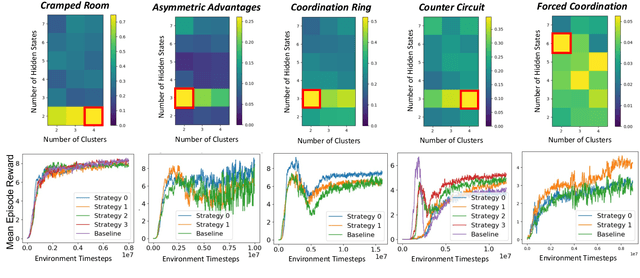
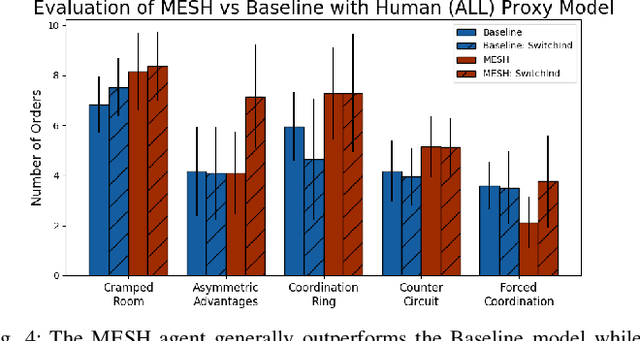
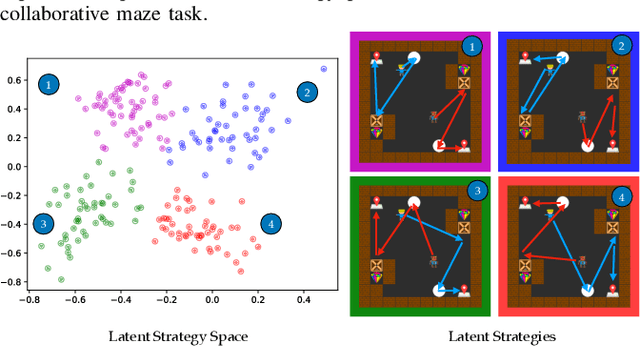
Human and robot partners increasingly need to work together to perform tasks as a team. Robots designed for such collaboration must reason about how their task-completion strategies interplay with the behavior and skills of their human team members as they coordinate on achieving joint goals. Our goal in this work is to develop a computational framework for robot adaptation to human partners in human-robot team collaborations. We first present an algorithm for autonomously recognizing available task-completion strategies by observing human-human teams performing a collaborative task. By transforming team actions into low dimensional representations using hidden Markov models, we can identify strategies without prior knowledge. Robot policies are learned on each of the identified strategies to construct a Mixture-of-Experts model that adapts to the task strategies of unseen human partners. We evaluate our model on a collaborative cooking task using an Overcooked simulator. Results of an online user study with 125 participants demonstrate that our framework improves the task performance and collaborative fluency of human-agent teams, as compared to state of the art reinforcement learning methods.