 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Unified Framework for Robots that Influence Humans over Long-Term Interaction
Mar 18, 2025Robot actions influence the decisions of nearby humans. Here influence refers to intentional change: robots influence humans when they shift the human's behavior in a way that helps the robot complete its task. Imagine an autonomous car trying to merge; by proactively nudging into the human's lane, the robot causes human drivers to yield and provide space. Influence is often necessary for seamless interaction. However, if influence is left unregulated and uncontrolled, robots will negatively impact the humans around them. Prior works have begun to address this problem by creating a variety of control algorithms that seek to influence humans. Although these methods are effective in the short-term, they fail to maintain influence over time as the human adapts to the robot's behaviors. In this paper we therefore present an optimization framework that enables robots to purposely regulate their influence over humans across both short-term and long-term interactions. Here the robot maintains its influence by reasoning over a dynamic human model which captures how the robot's current choices will impact the human's future behavior. Our resulting framework serves to unify current approaches: we demonstrate that state-of-the-art methods are simplifications of our underlying formalism. Our framework also provides a principled way to generate influential policies: in the best case the robot exactly solves our framework to find optimal, influential behavior. But when solving this optimization problem becomes impractical, designers can introduce their own simplifications to reach tractable approximations. We experimentally compare our unified framework to state-of-the-art baselines and ablations, and demonstrate across simulations and user studies that this framework is able to successfully influence humans over repeated interactions. See videos of our experiments here: https://youtu.be/nPekTUfUEbo
Robots that Learn to Safely Influence via Prediction-Informed Reach-Avoid Dynamic Games
Sep 18, 2024



Robots can influence people to accomplish their tasks more efficiently: autonomous cars can inch forward at an intersection to pass through, and tabletop manipulators can go for an object on the table first. However, a robot's ability to influence can also compromise the safety of nearby people if naively executed. In this work, we pose and solve a novel robust reach-avoid dynamic game which enables robots to be maximally influential, but only when a safety backup control exists. On the human side, we model the human's behavior as goal-driven but conditioned on the robot's plan, enabling us to capture influence. On the robot side, we solve the dynamic game in the joint physical and belief space, enabling the robot to reason about how its uncertainty in human behavior will evolve over time. We instantiate our method, called SLIDE (Safely Leveraging Influence in Dynamic Environments), in a high-dimensional (39-D) simulated human-robot collaborative manipulation task solved via offline game-theoretic reinforcement learning. We compare our approach to a robust baseline that treats the human as a worst-case adversary, a safety controller that does not explicitly reason about influence, and an energy-function-based safety shield. We find that SLIDE consistently enables the robot to leverage the influence it has on the human when it is safe to do so, ultimately allowing the robot to be less conservative while still ensuring a high safety rate during task execution.
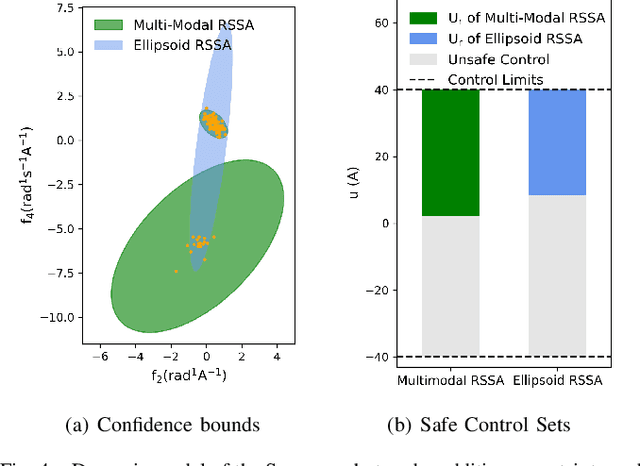
Multimodal Safe Control for Human-Robot Interaction
Nov 20, 2023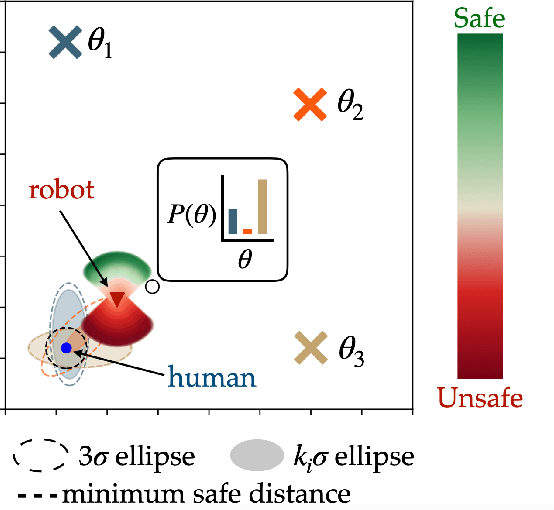
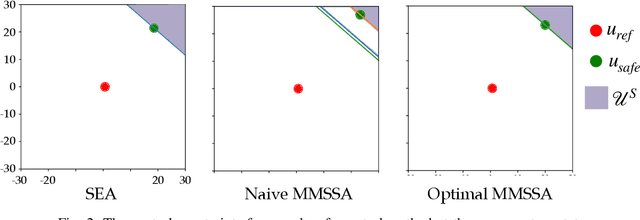
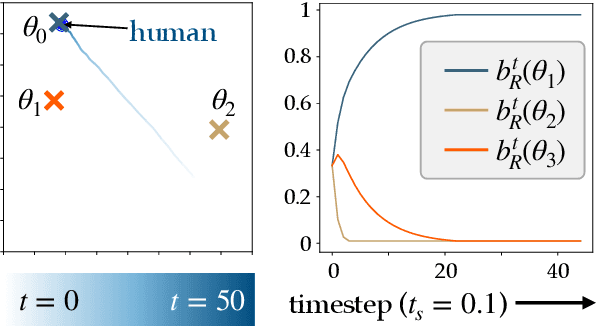
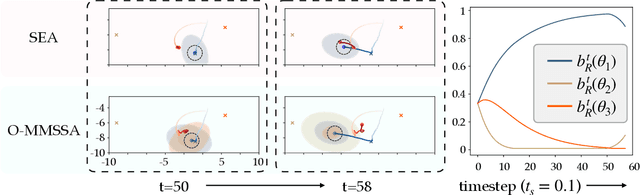
Generating safe behaviors for autonomous systems is important as they continue to be deployed in the real world, especially around people. In this work, we focus on developing a novel safe controller for systems where there are multiple sources of uncertainty. We formulate a novel multimodal safe control method, called the Multimodal Safe Set Algorithm (MMSSA) for the case where the agent has uncertainty over which discrete mode the system is in, and each mode itself contains additional uncertainty. To our knowledge, this is the first energy-function-based safe control method applied to systems with multimodal uncertainty. We apply our controller to a simulated human-robot interaction where the robot is uncertain of the human's true intention and each potential intention has its own additional uncertainty associated with it, since the human is not a perfectly rational actor. We compare our proposed safe controller to existing safe control methods and find that it does not impede the system performance (i.e. efficiency) while also improving the safety of the system.
Towards Proactive Safe Human-Robot Collaborations via Data-Efficient Conditional Behavior Prediction
Nov 20, 2023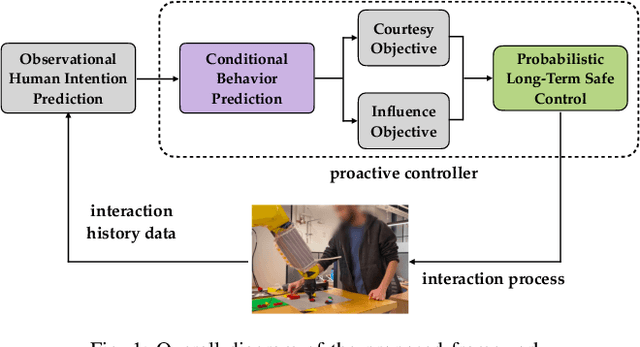
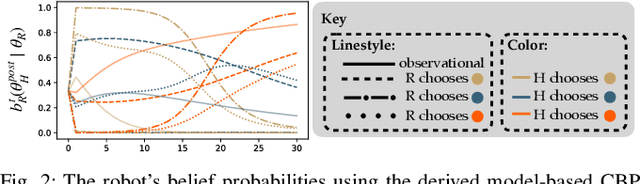
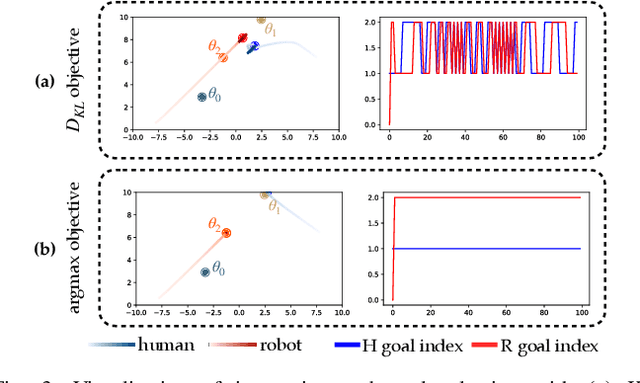
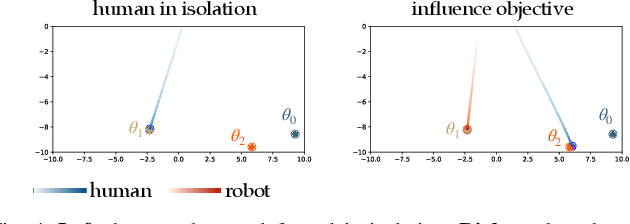
We focus on the problem of how we can enable a robot to collaborate seamlessly with a human partner, specifically in scenarios like collaborative manufacturing where prexisting data is sparse. Much prior work in human-robot collaboration uses observational models of humans (i.e. models that treat the robot purely as an observer) to choose the robot's behavior, but such models do not account for the influence the robot has on the human's actions, which may lead to inefficient interactions. We instead formulate the problem of optimally choosing a collaborative robot's behavior based on a conditional model of the human that depends on the robot's future behavior. First, we propose a novel model-based formulation of conditional behavior prediction that allows the robot to infer the human's intentions based on its future plan in data-sparse environments. We then show how to utilize a conditional model for proactive goal selection and path generation around human collaborators. Finally, we use our proposed proactive controller in a collaborative task with real users to show that it can improve users' interactions with a robot collaborator quantitatively and qualitatively.
Multi-Agent Strategy Explanations for Human-Robot Collaboration
Nov 20, 2023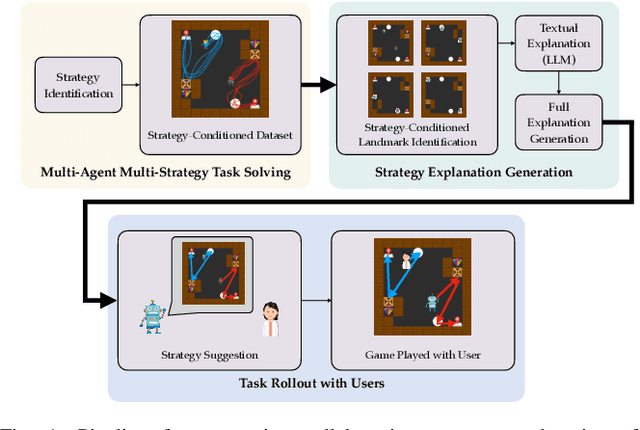
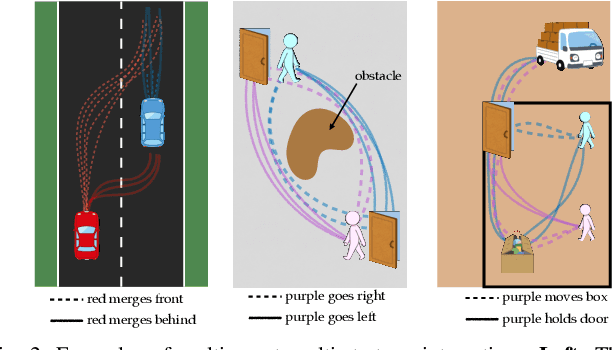
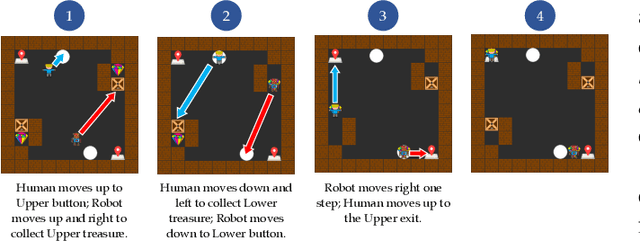
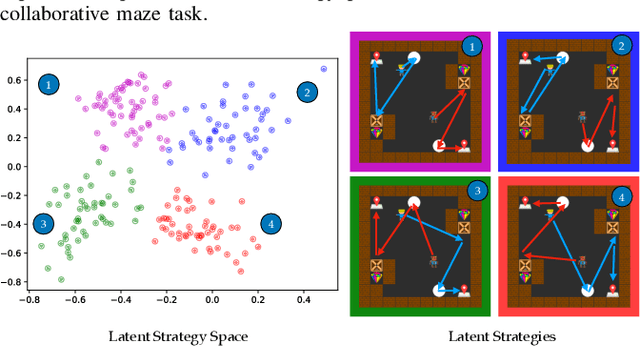
As robots are deployed in human spaces, it's important that they are able to coordinate their actions with the people around them. Part of such coordination involves ensuring that people have a good understanding of how a robot will act in the environment. This can be achieved through explanations of the robot's policy. Much prior work in explainable AI and RL focuses on generating explanations for single-agent policies, but little has been explored in generating explanations for collaborative policies. In this work, we investigate how to generate multi-agent strategy explanations for human-robot collaboration. We formulate the problem using a generic multi-agent planner, show how to generate visual explanations through strategy-conditioned landmark states and generate textual explanations by giving the landmarks to an LLM. Through a user study, we find that when presented with explanations from our proposed framework, users are able to better explore the full space of strategies and collaborate more efficiently with new robot partners.
Robust Safe Control with Multi-Modal Uncertainty
Sep 28, 2023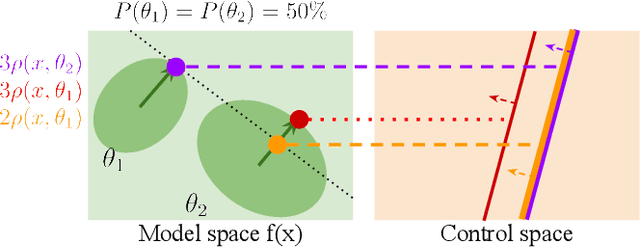
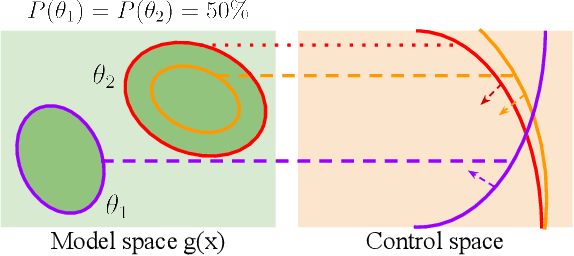
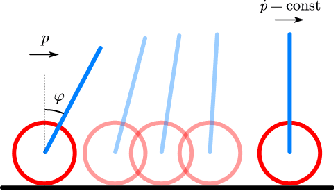
Safety in dynamic systems with prevalent uncertainties is crucial. Current robust safe controllers, designed primarily for uni-modal uncertainties, may be either overly conservative or unsafe when handling multi-modal uncertainties. To address the problem, we introduce a novel framework for robust safe control, tailored to accommodate multi-modal Gaussian dynamics uncertainties and control limits. We first present an innovative method for deriving the least conservative robust safe control under additive multi-modal uncertainties. Next, we propose a strategy to identify a locally least-conservative robust safe control under multiplicative uncertainties. Following these, we introduce a unique safety index synthesis method. This provides the foundation for a robust safe controller that ensures a high probability of realizability under control limits and multi-modal uncertainties. Experiments on a simulated Segway validate our approach, showing consistent realizability and less conservatism than controllers designed using uni-modal uncertainty methods. The framework offers significant potential for enhancing safety and performance in robotic applications.
Safe and Efficient Exploration of Human Models During Human-Robot Interaction
Aug 01, 2022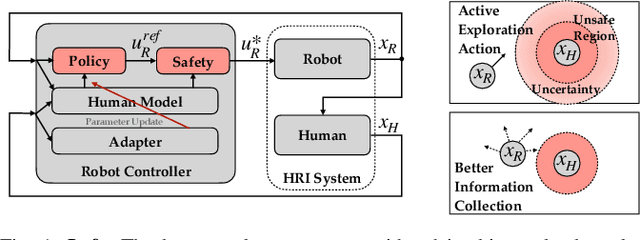
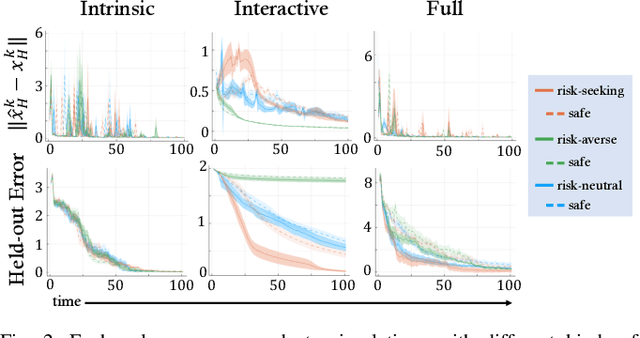
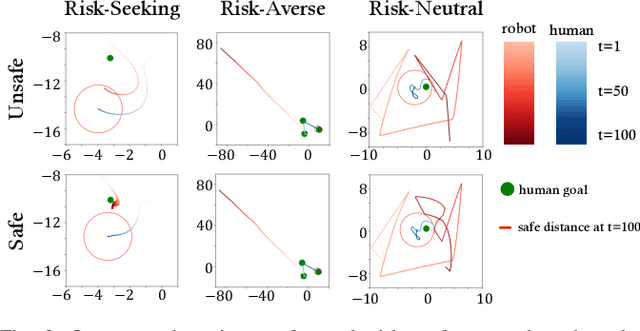
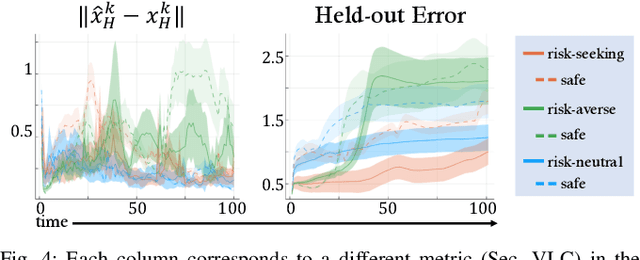
Many collaborative human-robot tasks require the robot to stay safe and work efficiently around humans. Since the robot can only stay safe with respect to its own model of the human, we want the robot to learn a good model of the human in order to act both safely and efficiently. This paper studies methods that enable a robot to safely explore the space of a human-robot system to improve the robot's model of the human, which will consequently allow the robot to access a larger state space and better work with the human. In particular, we introduce active exploration under the framework of energy-function based safe control, investigate the effect of different active exploration strategies, and finally analyze the effect of safe active exploration on both analytical and neural network human models.
Nonverbal Robot Feedback for Human Teachers
Nov 06, 2019
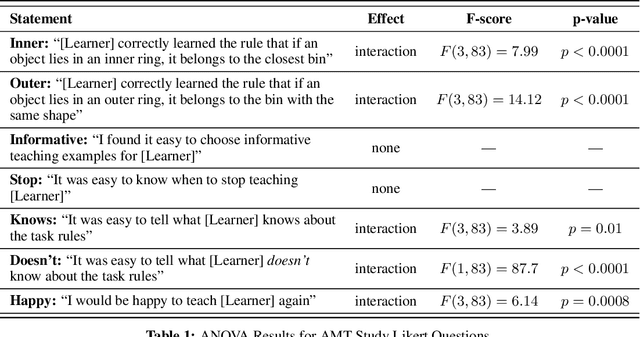
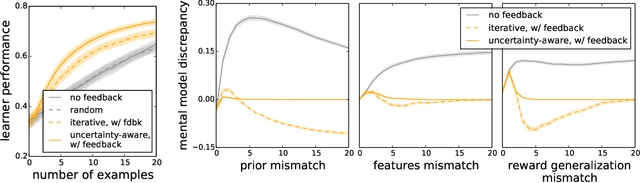
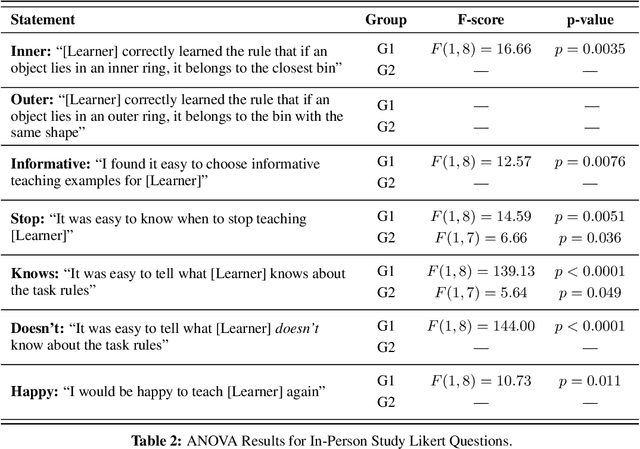
Robots can learn preferences from human demonstrations, but their success depends on how informative these demonstrations are. Being informative is unfortunately very challenging, because during teaching, people typically get no transparency into what the robot already knows or has learned so far. In contrast, human students naturally provide a wealth of nonverbal feedback that reveals their level of understanding and engagement. In this work, we study how a robot can similarly provide feedback that is minimally disruptive, yet gives human teachers a better mental model of the robot learner, and thus enables them to teach more effectively. Our idea is that at any point, the robot can indicate what it thinks the correct next action is, shedding light on its current estimate of the human's preferences. We analyze how useful this feedback is, both in theory and with two user studies---one with a virtual character that tests the feedback itself, and one with a PR2 robot that uses gaze as the feedback mechanism. We find that feedback can be useful for improving both the quality of teaching and teachers' understanding of the robot's capability.
Human-AI Learning Performance in Multi-Armed Bandits
Dec 21, 2018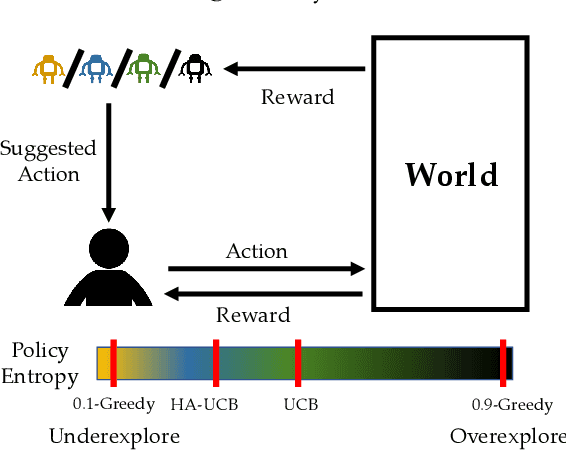
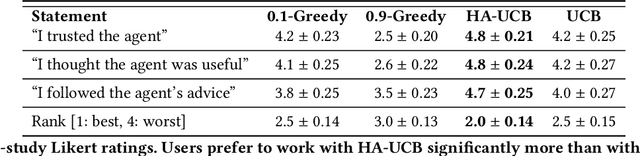
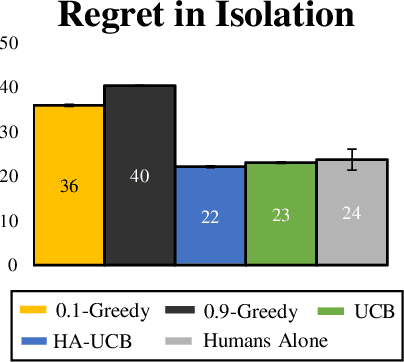
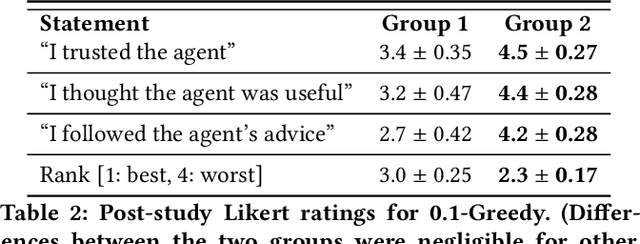
People frequently face challenging decision-making problems in which outcomes are uncertain or unknown. Artificial intelligence (AI) algorithms exist that can outperform humans at learning such tasks. Thus, there is an opportunity for AI agents to assist people in learning these tasks more effectively. In this work, we use a multi-armed bandit as a controlled setting in which to explore this direction. We pair humans with a selection of agents and observe how well each human-agent team performs. We find that team performance can beat both human and agent performance in isolation. Interestingly, we also find that an agent's performance in isolation does not necessarily correlate with the human-agent team's performance. A drop in agent performance can lead to a disproportionately large drop in team performance, or in some settings can even improve team performance. Pairing a human with an agent that performs slightly better than them can make them perform much better, while pairing them with an agent that performs the same can make them them perform much worse. Further, our results suggest that people have different exploration strategies and might perform better with agents that match their strategy. Overall, optimizing human-agent team performance requires going beyond optimizing agent performance, to understanding how the agent's suggestions will influence human decision-making.
Learning Image-Conditioned Dynamics Models for Control of Under-actuated Legged Millirobots
Mar 30, 2018
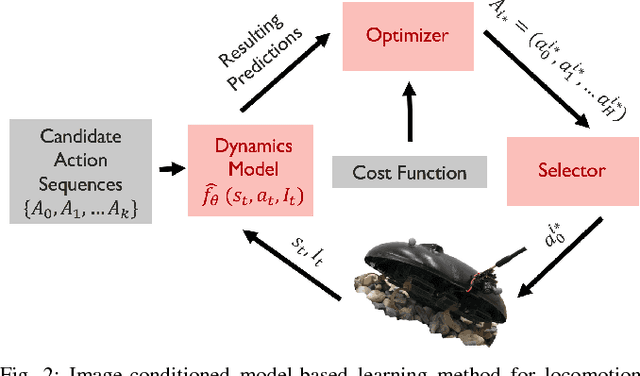


Millirobots are a promising robotic platform for many applications due to their small size and low manufacturing costs. Legged millirobots, in particular, can provide increased mobility in complex environments and improved scaling of obstacles. However, controlling these small, highly dynamic, and underactuated legged systems is difficult. Hand-engineered controllers can sometimes control these legged millirobots, but they have difficulties with dynamic maneuvers and complex terrains. We present an approach for controlling a real-world legged millirobot that is based on learned neural network models. Using less than 17 minutes of data, our method can learn a predictive model of the robot's dynamics that can enable effective gaits to be synthesized on the fly for following user-specified waypoints on a given terrain. Furthermore, by leveraging expressive, high-capacity neural network models, our approach allows for these predictions to be directly conditioned on camera images, endowing the robot with the ability to predict how different terrains might affect its dynamics. This enables sample-efficient and effective learning for locomotion of a dynamic legged millirobot on various terrains, including gravel, turf, carpet, and styrofoam. Experiment videos can be found at https://sites.google.com/view/imageconddyn