 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpInf-LLM: Parametric PDE Solving with LLMs via Operator Inference
Feb 02, 2026Solving diverse partial differential equations (PDEs) is fundamental in science and engineering. Large language models (LLMs) have demonstrated strong capabilities in code generation, symbolic reasoning, and tool use, but reliably solving PDEs across heterogeneous settings remains challenging. Prior work on LLM-based code generation and transformer-based foundation models for PDE learning has shown promising advances. However, a persistent trade-off between execution success rate and numerical accuracy arises, particularly when generalization to unseen parameters and boundary conditions is required. In this work, we propose OpInf-LLM, an LLM parametric PDE solving framework based on operator inference. The proposed framework leverages a small amount of solution data to enable accurate prediction of diverse PDE instances, including unseen parameters and configurations, and provides seamless integration with LLMs for natural language specification of PDE solving tasks. Its low computational demands and unified tool interface further enable a high execution success rate across heterogeneous settings. By combining operator inference with LLM capabilities, OpInf-LLM opens new possibilities for generalizable reduced-order modeling in LLM-based PDE solving.
Polynomial Convergence of Riemannian Diffusion Models
Jan 05, 2026Diffusion models have demonstrated remarkable empirical success in the recent years and are considered one of the state-of-the-art generative models in modern AI. These models consist of a forward process, which gradually diffuses the data distribution to a noise distribution spanning the whole space, and a backward process, which inverts this transformation to recover the data distribution from noise. Most of the existing literature assumes that the underlying space is Euclidean. However, in many practical applications, the data are constrained to lie on a submanifold of Euclidean space. Addressing this setting, De Bortoli et al. (2022) introduced Riemannian diffusion models and proved that using an exponentially small step size yields a small sampling error in the Wasserstein distance, provided the data distribution is smooth and strictly positive, and the score estimate is $L_\infty$-accurate. In this paper, we greatly strengthen this theory by establishing that, under $L_2$-accurate score estimate, a {\em polynomially small stepsize} suffices to guarantee small sampling error in the total variation distance, without requiring smoothness or positivity of the data distribution. Our analysis only requires mild and standard curvature assumptions on the underlying manifold. The main ingredients in our analysis are Li-Yau estimate for the log-gradient of heat kernel, and Minakshisundaram-Pleijel parametrix expansion of the perturbed heat equation. Our approach opens the door to a sharper analysis of diffusion models on non-Euclidean spaces.
Physics-Informed Deep B-Spline Networks for Dynamical Systems
Mar 21, 2025



Physics-informed machine learning provides an approach to combining data and governing physics laws for solving complex partial differential equations (PDEs). However, efficiently solving PDEs with varying parameters and changing initial conditions and boundary conditions (ICBCs) with theoretical guarantees remains an open challenge. We propose a hybrid framework that uses a neural network to learn B-spline control points to approximate solutions to PDEs with varying system and ICBC parameters. The proposed network can be trained efficiently as one can directly specify ICBCs without imposing losses, calculate physics-informed loss functions through analytical formulas, and requires only learning the weights of B-spline functions as opposed to both weights and basis as in traditional neural operator learning methods. We provide theoretical guarantees that the proposed B-spline networks serve as universal approximators for the set of solutions of PDEs with varying ICBCs under mild conditions and establish bounds on the generalization errors in physics-informed learning. We also demonstrate in experiments that the proposed B-spline network can solve problems with discontinuous ICBCs and outperforms existing methods, and is able to learn solutions of 3D dynamics with diverse initial conditions.
Predictive Control and Regret Analysis of Non-Stationary MDP with Look-ahead Information
Sep 13, 2024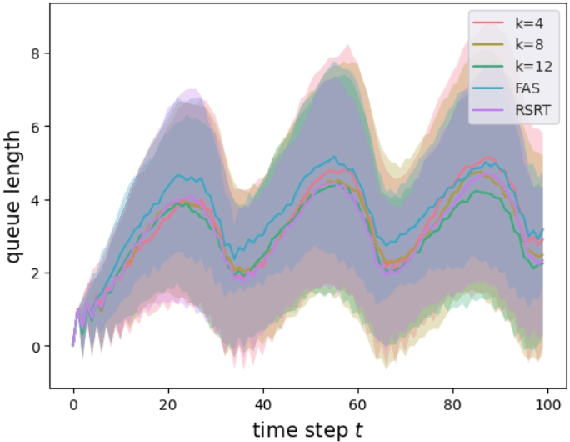
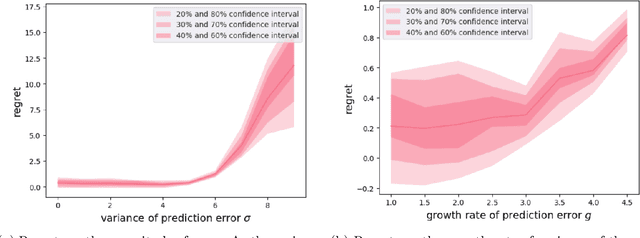
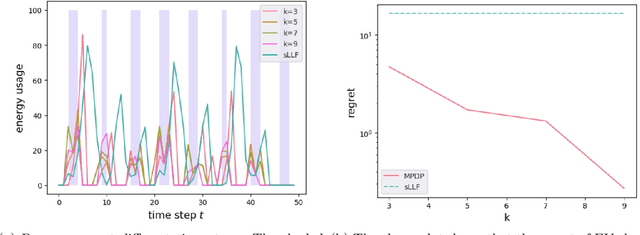
Policy design in non-stationary Markov Decision Processes (MDPs) is inherently challenging due to the complexities introduced by time-varying system transition and reward, which make it difficult for learners to determine the optimal actions for maximizing cumulative future rewards. Fortunately, in many practical applications, such as energy systems, look-ahead predictions are available, including forecasts for renewable energy generation and demand. In this paper, we leverage these look-ahead predictions and propose an algorithm designed to achieve low regret in non-stationary MDPs by incorporating such predictions. Our theoretical analysis demonstrates that, under certain assumptions, the regret decreases exponentially as the look-ahead window expands. When the system prediction is subject to error, the regret does not explode even if the prediction error grows sub-exponentially as a function of the prediction horizon. We validate our approach through simulations, confirming the efficacy of our algorithm in non-stationary environments.
Autonomous Drifting Based on Maximal Safety Probability Learning
Sep 05, 2024This paper proposes a novel learning-based framework for autonomous driving based on the concept of maximal safety probability. Efficient learning requires rewards that are informative of desirable/undesirable states, but such rewards are challenging to design manually due to the difficulty of differentiating better states among many safe states. On the other hand, learning policies that maximize safety probability does not require laborious reward shaping but is numerically challenging because the algorithms must optimize policies based on binary rewards sparse in time. Here, we show that physics-informed reinforcement learning can efficiently learn this form of maximally safe policy. Unlike existing drift control methods, our approach does not require a specific reference trajectory or complex reward shaping, and can learn safe behaviors only from sparse binary rewards. This is enabled by the use of the physics loss that plays an analogous role to reward shaping. The effectiveness of the proposed approach is demonstrated through lane keeping in a normal cornering scenario and safe drifting in a high-speed racing scenario.
Generalizable Physics-informed Learning for Stochastic Safety-critical Systems
Jul 11, 2024



Accurate estimate of long-term risk is critical for safe decision-making, but sampling from rare risk events and long-term trajectories can be prohibitively costly. Risk gradient can be used in many first-order techniques for learning and control methods, but gradient estimate is difficult to obtain using Monte Carlo (MC) methods because the infinitesimal devisor may significantly amplify sampling noise. Motivated by this gap, we propose an efficient method to evaluate long-term risk probabilities and their gradients using short-term samples without sufficient risk events. We first derive that four types of long-term risk probability are solutions of certain partial differential equations (PDEs). Then, we propose a physics-informed learning technique that integrates data and physics information (aforementioned PDEs). The physics information helps propagate information beyond available data and obtain provable generalization beyond available data, which in turn enables long-term risk to be estimated using short-term samples of safe events. Finally, we demonstrate in simulation that the proposed technique has improved sample efficiency, generalizes well to unseen regions, and adapts to changing system parameters.
Learning to Stabilize Unknown LTI Systems on a Single Trajectory under Stochastic Noise
May 31, 2024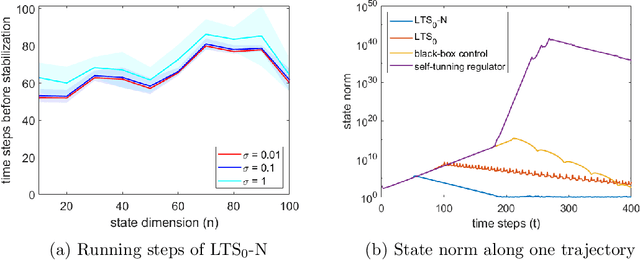


We study the problem of learning to stabilize unknown noisy Linear Time-Invariant (LTI) systems on a single trajectory. It is well known in the literature that the learn-to-stabilize problem suffers from exponential blow-up in which the state norm blows up in the order of $\Theta(2^n)$ where $n$ is the state space dimension. This blow-up is due to the open-loop instability when exploring the $n$-dimensional state space. To address this issue, we develop a novel algorithm that decouples the unstable subspace of the LTI system from the stable subspace, based on which the algorithm only explores and stabilizes the unstable subspace, the dimension of which can be much smaller than $n$. With a new singular-value-decomposition(SVD)-based analytical framework, we prove that the system is stabilized before the state norm reaches $2^{O(k \log n)}$, where $k$ is the dimension of the unstable subspace. Critically, this bound avoids exponential blow-up in state dimension in the order of $\Theta(2^n)$ as in the previous works, and to the best of our knowledge, this is the first paper to avoid exponential blow-up in dimension for stabilizing LTI systems with noise.
Myopically Verifiable Probabilistic Certificates for Safe Control and Learning
Apr 23, 2024This paper addresses the design of safety certificates for stochastic systems, with a focus on ensuring long-term safety through fast real-time control. In stochastic environments, set invariance-based methods that restrict the probability of risk events in infinitesimal time intervals may exhibit significant long-term risks due to cumulative uncertainties/risks. On the other hand, reachability-based approaches that account for the long-term future may require prohibitive computation in real-time decision making. To overcome this challenge involving stringent long-term safety vs. computation tradeoffs, we first introduce a novel technique termed `probabilistic invariance'. This technique characterizes the invariance conditions of the probability of interest. When the target probability is defined using long-term trajectories, this technique can be used to design myopic conditions/controllers with assured long-term safe probability. Then, we integrate this technique into safe control and learning. The proposed control methods efficiently assure long-term safety using neural networks or model predictive controllers with short outlook horizons. The proposed learning methods can be used to guarantee long-term safety during and after training. Finally, we demonstrate the performance of the proposed techniques in numerical simulations.
Physics-informed RL for Maximal Safety Probability Estimation
Mar 25, 2024Accurate risk quantification and reachability analysis are crucial for safe control and learning, but sampling from rare events, risky states, or long-term trajectories can be prohibitively costly. Motivated by this, we study how to estimate the long-term safety probability of maximally safe actions without sufficient coverage of samples from risky states and long-term trajectories. The use of maximal safety probability in control and learning is expected to avoid conservative behaviors due to over-approximation of risk. Here, we first show that long-term safety probability, which is multiplicative in time, can be converted into additive costs and be solved using standard reinforcement learning methods. We then derive this probability as solutions of partial differential equations (PDEs) and propose Physics-Informed Reinforcement Learning (PIRL) algorithm. The proposed method can learn using sparse rewards because the physics constraints help propagate risk information through neighbors. This suggests that, for the purpose of extracting more information for efficient learning, physics constraints can serve as an alternative to reward shaping. The proposed method can also estimate long-term risk using short-term samples and deduce the risk of unsampled states. This feature is in stark contrast with the unconstrained deep RL that demands sufficient data coverage. These merits of the proposed method are demonstrated in numerical simulation.
An Analytic Solution to Covariance Propagation in Neural Networks
Mar 24, 2024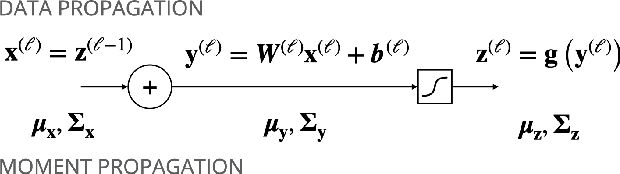

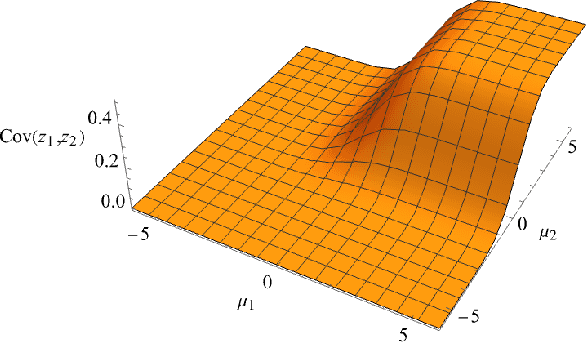
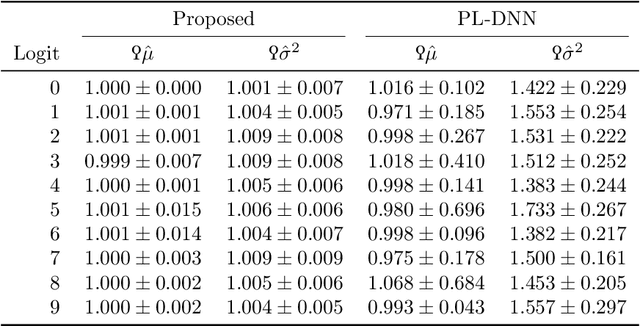
Uncertainty quantification of neural networks is critical to measuring the reliability and robustness of deep learning systems. However, this often involves costly or inaccurate sampling methods and approximations. This paper presents a sample-free moment propagation technique that propagates mean vectors and covariance matrices across a network to accurately characterize the input-output distributions of neural networks. A key enabler of our technique is an analytic solution for the covariance of random variables passed through nonlinear activation functions, such as Heaviside, ReLU, and GELU. The wide applicability and merits of the proposed technique are shown in experiments analyzing the input-output distributions of trained neural networks and training Bayesian neural networks.