 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLA-MPC: Fast Adaptive Control for Autonomous Racing
May 26, 2025We present Look-Back and Look-Ahead Adaptive Model Predictive Control (LLA-MPC), a real-time adaptive control framework for autonomous racing that addresses the challenge of rapidly changing tire-surface interactions. Unlike existing approaches requiring substantial data collection or offline training, LLA-MPC employs a model bank for immediate adaptation without a learning period. It integrates two key mechanisms: a look-back window that evaluates recent vehicle behavior to select the most accurate model and a look-ahead horizon that optimizes trajectory planning based on the identified dynamics. The selected model and estimated friction coefficient are then incorporated into a trajectory planner to optimize reference paths in real-time. Experiments across diverse racing scenarios demonstrate that LLA-MPC outperforms state-of-the-art methods in adaptation speed and handling, even during sudden friction transitions. Its learning-free, computationally efficient design enables rapid adaptation, making it ideal for high-speed autonomous racing in multi-surface environments.
Safety Embedded Adaptive Control Using Barrier States
Apr 21, 2025In this work, we explore the application of barrier states (BaS) in the realm of safe nonlinear adaptive control. Our proposed framework derives barrier states for systems with parametric uncertainty, which are augmented into the uncertain dynamical model. We employ an adaptive nonlinear control strategy based on a control Lyapunov functions approach to design a stabilizing controller for the augmented system. The developed theory shows that the controller ensures safe control actions for the original system while meeting specified performance objectives. We validate the effectiveness of our approach through simulations on diverse systems, including a planar quadrotor subject to unknown drag forces and an adaptive cruise control system, for which we provide comparisons with existing methodologies.
Nearly Optimal Nonlinear Safe Control with BaS-SDRE
Apr 21, 2025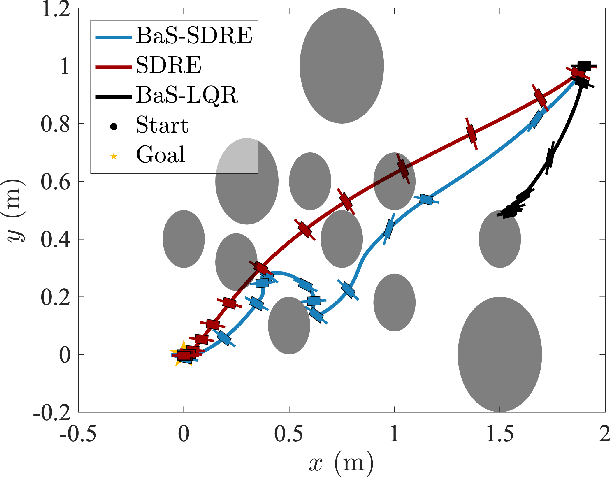
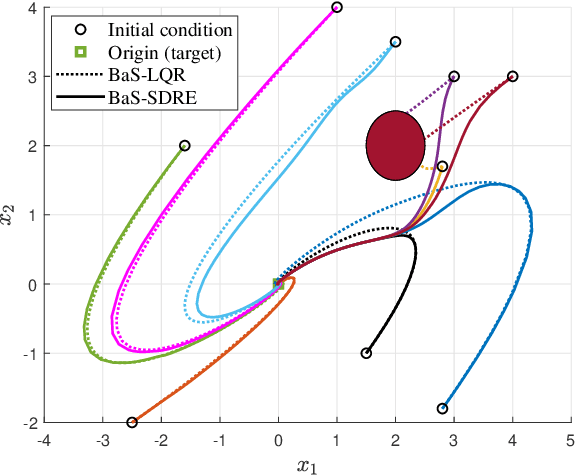
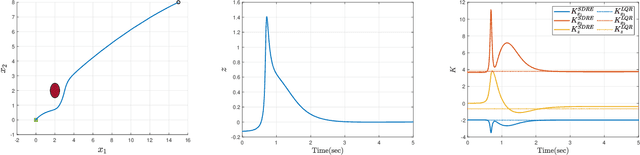
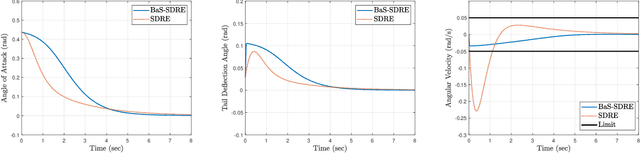
The State-Dependent Riccati Equation (SDRE) approach has emerged as a systematic and effective means of designing nearly optimal nonlinear controllers. The Barrier States (BaS) embedding methodology was developed recently for safe multi-objective controls in which the safety condition is manifested as a state to be controlled along with other states of the system. The overall system, termed the safety embedded system, is highly nonlinear even if the original system is linear. This paper develops a nonlinear nearly optimal safe feedback control technique by combining the two strategies effectively. First, the BaS is derived in an extended linearization formulation to be subsequently used to form an extended safety embedded system. A new optimal control problem is formed thereafter, which is used to construct a safety embedded State-Dependent Riccati Equation, termed BaS-SDRE, whose solution approximates the solution of the optimal control problem's associated Hamilton-Jacobi-Bellman (HJB) equation. The BaS-SDRE is then solved online to synthesize the nearly optimal safe control. The proposed technique's efficacy is demonstrated on an unstable, constrained linear system that shows how the synthesized control reacts to nonlinearities near the unsafe region, a nonlinear flight control system with limited path angular velocity that exists due to structural and dynamic concerns, and a planar quadrotor system that navigates safely in a crowded environment.
Toward a Low-Cost Perception System in Autonomous Vehicles: A Spectrum Learning Approach
Feb 04, 2025



We present a cost-effective new approach for generating denser depth maps for Autonomous Driving (AD) and Autonomous Vehicles (AVs) by integrating the images obtained from deep neural network (DNN) 4D radar detectors with conventional camera RGB images. Our approach introduces a novel pixel positional encoding algorithm inspired by Bartlett's spatial spectrum estimation technique. This algorithm transforms both radar depth maps and RGB images into a unified pixel image subspace called the Spatial Spectrum, facilitating effective learning based on their similarities and differences. Our method effectively leverages high-resolution camera images to train radar depth map generative models, addressing the limitations of conventional radar detectors in complex vehicular environments, thus sharpening the radar output. We develop spectrum estimation algorithms tailored for radar depth maps and RGB images, a comprehensive training framework for data-driven generative models, and a camera-radar deployment scheme for AV operation. Our results demonstrate that our approach also outperforms the state-of-the-art (SOTA) by 27.95% in terms of Unidirectional Chamfer Distance (UCD).
Disturbance Observer-based Control Barrier Functions with Residual Model Learning for Safe Reinforcement Learning
Oct 09, 2024
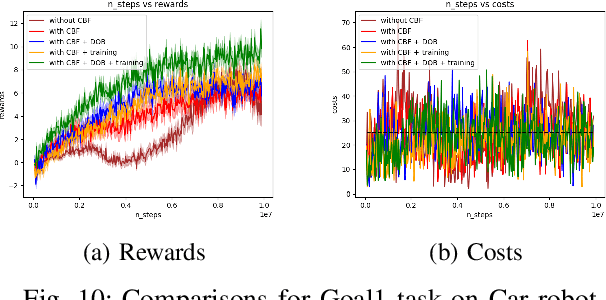
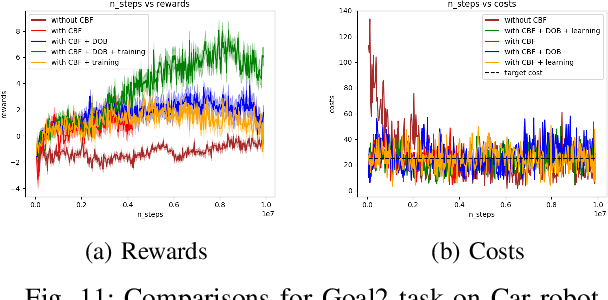

Reinforcement learning (RL) agents need to explore their environment to learn optimal behaviors and achieve maximum rewards. However, exploration can be risky when training RL directly on real systems, while simulation-based training introduces the tricky issue of the sim-to-real gap. Recent approaches have leveraged safety filters, such as control barrier functions (CBFs), to penalize unsafe actions during RL training. However, the strong safety guarantees of CBFs rely on a precise dynamic model. In practice, uncertainties always exist, including internal disturbances from the errors of dynamics and external disturbances such as wind. In this work, we propose a new safe RL framework based on disturbance rejection-guarded learning, which allows for an almost model-free RL with an assumed but not necessarily precise nominal dynamic model. We demonstrate our results on the Safety-gym benchmark for Point and Car robots on all tasks where we can outperform state-of-the-art approaches that use only residual model learning or a disturbance observer (DOB). We further validate the efficacy of our framework using a physical F1/10 racing car. Videos: https://sites.google.com/view/res-dob-cbf-rl
Agile Mobility with Rapid Online Adaptation via Meta-learning and Uncertainty-aware MPPI
Oct 09, 2024Modern non-linear model-based controllers require an accurate physics model and model parameters to be able to control mobile robots at their limits. Also, due to surface slipping at high speeds, the friction parameters may continually change (like tire degradation in autonomous racing), and the controller may need to adapt rapidly. Many works derive a task-specific robot model with a parameter adaptation scheme that works well for the task but requires a lot of effort and tuning for each platform and task. In this work, we design a full model-learning-based controller based on meta pre-training that can very quickly adapt using few-shot dynamics data to any wheel-based robot with any model parameters, while also reasoning about model uncertainty. We demonstrate our results in small-scale numeric simulation, the large-scale Unity simulator, and on a medium-scale hardware platform with a wide range of settings. We show that our results are comparable to domain-specific well-engineered controllers, and have excellent generalization performance across all scenarios.
AnyCar to Anywhere: Learning Universal Dynamics Model for Agile and Adaptive Mobility
Sep 24, 2024Recent works in the robot learning community have successfully introduced generalist models capable of controlling various robot embodiments across a wide range of tasks, such as navigation and locomotion. However, achieving agile control, which pushes the limits of robotic performance, still relies on specialist models that require extensive parameter tuning. To leverage generalist-model adaptability and flexibility while achieving specialist-level agility, we propose AnyCar, a transformer-based generalist dynamics model designed for agile control of various wheeled robots. To collect training data, we unify multiple simulators and leverage different physics backends to simulate vehicles with diverse sizes, scales, and physical properties across various terrains. With robust training and real-world fine-tuning, our model enables precise adaptation to different vehicles, even in the wild and under large state estimation errors. In real-world experiments, AnyCar shows both few-shot and zero-shot generalization across a wide range of vehicles and environments, where our model, combined with a sampling-based MPC, outperforms specialist models by up to 54%. These results represent a key step toward building a foundation model for agile wheeled robot control. We will also open-source our framework to support further research.
Real-Time Whole-Body Control of Legged Robots with Model-Predictive Path Integral Control
Sep 16, 2024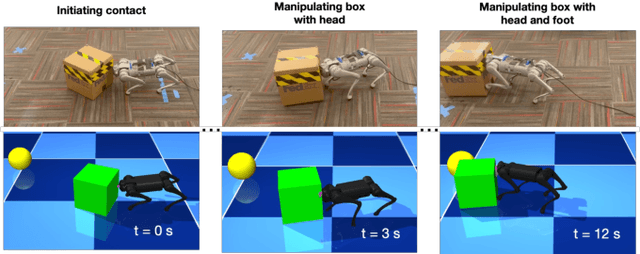



This paper presents a system for enabling real-time synthesis of whole-body locomotion and manipulation policies for real-world legged robots. Motivated by recent advancements in robot simulation, we leverage the efficient parallelization capabilities of the MuJoCo simulator to achieve fast sampling over the robot state and action trajectories. Our results show surprisingly effective real-world locomotion and manipulation capabilities with a very simple control strategy. We demonstrate our approach on several hardware and simulation experiments: robust locomotion over flat and uneven terrains, climbing over a box whose height is comparable to the robot, and pushing a box to a goal position. To our knowledge, this is the first successful deployment of whole-body sampling-based MPC on real-world legged robot hardware. Experiment videos and code can be found at: https://whole-body-mppi.github.io/
Safe Control of Quadruped in Varying Dynamics via Safety Index Adaptation
Sep 15, 2024



Varying dynamics pose a fundamental difficulty when deploying safe control laws in the real world. Safety Index Synthesis (SIS) deeply relies on the system dynamics and once the dynamics change, the previously synthesized safety index becomes invalid. In this work, we show the real-time efficacy of Safety Index Adaptation (SIA) in varying dynamics. SIA enables real-time adaptation to the changing dynamics so that the adapted safe control law can still guarantee 1) forward invariance within a safe region and 2) finite time convergence to that safe region. This work employs SIA on a package-carrying quadruped robot, where the payload weight changes in real-time. SIA updates the safety index when the dynamics change, e.g., a change in payload weight, so that the quadruped can avoid obstacles while achieving its performance objectives. Numerical study provides theoretical guarantees for SIA and a series of hardware experiments demonstrate the effectiveness of SIA in real-world deployment in avoiding obstacles under varying dynamics.
Autonomous Drifting Based on Maximal Safety Probability Learning
Sep 05, 2024This paper proposes a novel learning-based framework for autonomous driving based on the concept of maximal safety probability. Efficient learning requires rewards that are informative of desirable/undesirable states, but such rewards are challenging to design manually due to the difficulty of differentiating better states among many safe states. On the other hand, learning policies that maximize safety probability does not require laborious reward shaping but is numerically challenging because the algorithms must optimize policies based on binary rewards sparse in time. Here, we show that physics-informed reinforcement learning can efficiently learn this form of maximally safe policy. Unlike existing drift control methods, our approach does not require a specific reference trajectory or complex reward shaping, and can learn safe behaviors only from sparse binary rewards. This is enabled by the use of the physics loss that plays an analogous role to reward shaping. The effectiveness of the proposed approach is demonstrated through lane keeping in a normal cornering scenario and safe drifting in a high-speed racing scenario.