 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLA-MPC: Fast Adaptive Control for Autonomous Racing
May 26, 2025We present Look-Back and Look-Ahead Adaptive Model Predictive Control (LLA-MPC), a real-time adaptive control framework for autonomous racing that addresses the challenge of rapidly changing tire-surface interactions. Unlike existing approaches requiring substantial data collection or offline training, LLA-MPC employs a model bank for immediate adaptation without a learning period. It integrates two key mechanisms: a look-back window that evaluates recent vehicle behavior to select the most accurate model and a look-ahead horizon that optimizes trajectory planning based on the identified dynamics. The selected model and estimated friction coefficient are then incorporated into a trajectory planner to optimize reference paths in real-time. Experiments across diverse racing scenarios demonstrate that LLA-MPC outperforms state-of-the-art methods in adaptation speed and handling, even during sudden friction transitions. Its learning-free, computationally efficient design enables rapid adaptation, making it ideal for high-speed autonomous racing in multi-surface environments.
Nearly Optimal Nonlinear Safe Control with BaS-SDRE
Apr 21, 2025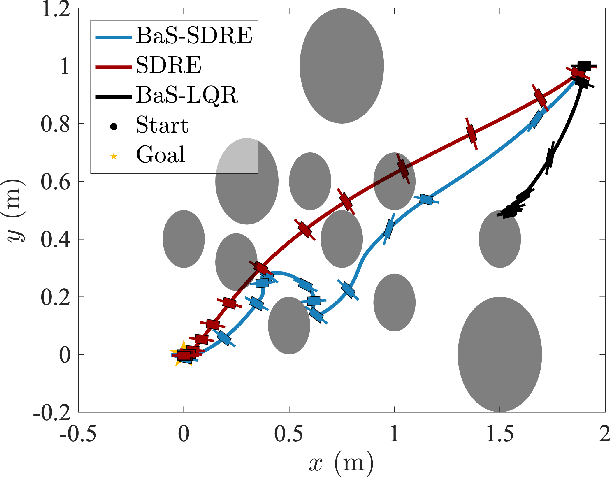
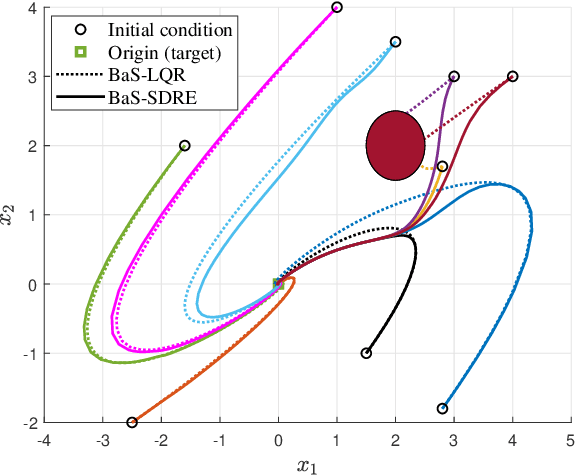
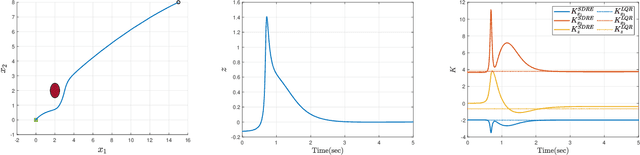
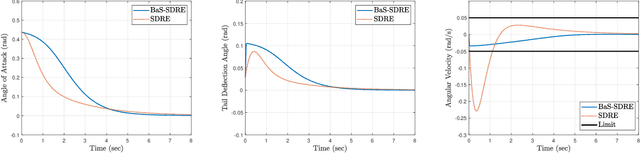
The State-Dependent Riccati Equation (SDRE) approach has emerged as a systematic and effective means of designing nearly optimal nonlinear controllers. The Barrier States (BaS) embedding methodology was developed recently for safe multi-objective controls in which the safety condition is manifested as a state to be controlled along with other states of the system. The overall system, termed the safety embedded system, is highly nonlinear even if the original system is linear. This paper develops a nonlinear nearly optimal safe feedback control technique by combining the two strategies effectively. First, the BaS is derived in an extended linearization formulation to be subsequently used to form an extended safety embedded system. A new optimal control problem is formed thereafter, which is used to construct a safety embedded State-Dependent Riccati Equation, termed BaS-SDRE, whose solution approximates the solution of the optimal control problem's associated Hamilton-Jacobi-Bellman (HJB) equation. The BaS-SDRE is then solved online to synthesize the nearly optimal safe control. The proposed technique's efficacy is demonstrated on an unstable, constrained linear system that shows how the synthesized control reacts to nonlinearities near the unsafe region, a nonlinear flight control system with limited path angular velocity that exists due to structural and dynamic concerns, and a planar quadrotor system that navigates safely in a crowded environment.
Safety Embedded Adaptive Control Using Barrier States
Apr 21, 2025In this work, we explore the application of barrier states (BaS) in the realm of safe nonlinear adaptive control. Our proposed framework derives barrier states for systems with parametric uncertainty, which are augmented into the uncertain dynamical model. We employ an adaptive nonlinear control strategy based on a control Lyapunov functions approach to design a stabilizing controller for the augmented system. The developed theory shows that the controller ensures safe control actions for the original system while meeting specified performance objectives. We validate the effectiveness of our approach through simulations on diverse systems, including a planar quadrotor subject to unknown drag forces and an adaptive cruise control system, for which we provide comparisons with existing methodologies.
Improved Exploration for Safety-Embedded Differential Dynamic Programming Using Tolerant Barrier States
Mar 06, 2023In this paper, we introduce Tolerant Discrete Barrier States (T-DBaS), a novel safety-embedding technique for trajectory optimization with enhanced exploratory capabilities. The proposed approach generalizes the standard discrete barrier state (DBaS) method by accommodating temporary constraint violation during the optimization process while still approximating its safety guarantees. Consequently, the proposed approach eliminates the DBaS's safe nominal trajectories assumption, while enhancing its exploration effectiveness for escaping local minima. Towards applying T-DBaS to safety-critical autonomous robotics, we combine it with Differential Dynamic Programming (DDP), leading to the proposed safe trajectory optimization method T-DBaS-DDP, which inherits the convergence and scalability properties of the solver. The effectiveness of the T-DBaS algorithm is verified on differential drive robot and quadrotor simulations. In addition, we compare against the classical DBaS-DDP as well as Augmented-Lagrangian DDP (AL-DDP) in extensive numerical comparisons that demonstrate the proposed method's competitive advantages. Finally, the applicability of the proposed approach is verified through hardware experiments on the Georgia Tech Robotarium platform.
Gaussian Process Barrier States for Safe Trajectory Optimization and Control
Dec 01, 2022This paper proposes embedded Gaussian Process Barrier States (GP-BaS), a methodology to safely control unmodeled dynamics of nonlinear system using Bayesian learning. Gaussian Processes (GPs) are used to model the dynamics of the safety-critical system, which is subsequently used in the GP-BaS model. We derive the barrier state dynamics utilizing the GP posterior, which is used to construct a safety embedded Gaussian process dynamical model (GPDM). We show that the safety-critical system can be controlled to remain inside the safe region as long as we can design a controller that renders the BaS-GPDM's trajectories bounded (or asymptotically stable). The proposed approach overcomes various limitations in early attempts at combining GPs with barrier functions due to the abstention of restrictive assumptions such as linearity of the system with respect to control, relative degree of the constraints and number or nature of constraints. This work is implemented on various examples for trajectory optimization and control including optimal stabilization of unstable linear system and safe trajectory optimization of a Dubins vehicle navigating through an obstacle course and on a quadrotor in an obstacle avoidance task using GP differentiable dynamic programming (GP-DDP). The proposed framework is capable of maintaining safe optimization and control of unmodeled dynamics and is purely data driven.
Safety Embedded Differential Dynamic Programming using Discrete Barrier States
May 30, 2021
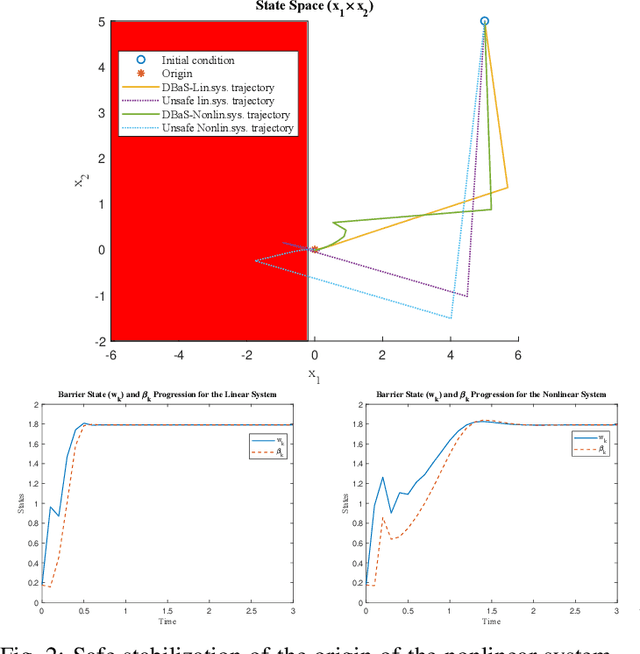
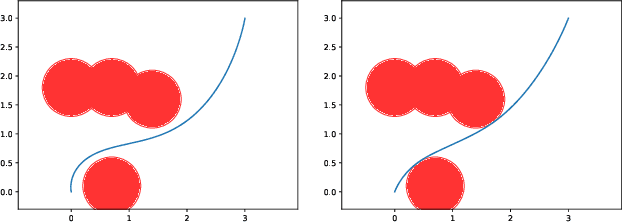
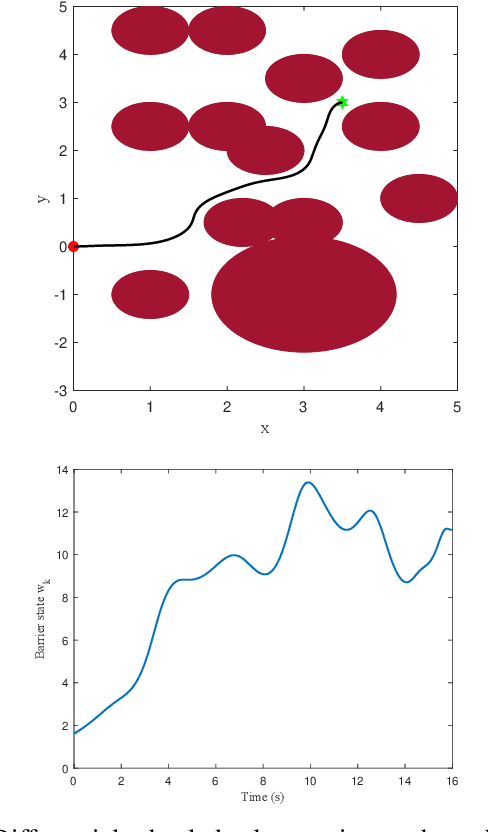
Certified safe control is a growing challenge in robotics, especially when performance and safety objectives are desired to be concurrently achieved. In this work, we extend the barrier state (BaS) concept, recently proposed for stabilization of continuous time systems, to enforce safety for discrete time systems by creating a discrete barrier state (DBaS). The constructed DBaS is embedded into the discrete model of the safety-critical system in order to integrate safety objectives into performance objectives. We subsequently use the proposed technique to implement a safety embedded stabilizing control for nonlinear discrete systems. Furthermore, we employ the DBaS method to develop a safety embedded differential dynamic programming (DDP) technique to plan and execute safe optimal trajectories. The proposed algorithm is leveraged on a differential wheeled robot and on a quadrotor to safely perform several tasks including reaching, tracking and safe multi-quadrotor movement. The DBaS-based DDP (DBaS-DDP) is compared to the penalty method used in constrained DDP problems where it is shown that the DBaS-DDP consistently outperforms the penalty method.