 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPPI-Generic: A CUDA Library for Stochastic Optimization
Sep 11, 2024

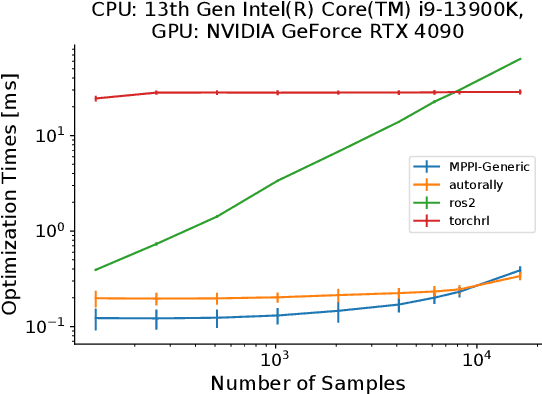
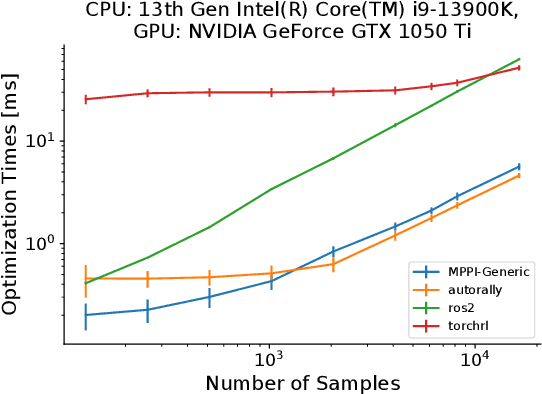
This paper introduces a new C++/CUDA library for GPU-accelerated stochastic optimization called MPPI-Generic. It provides implementations of Model Predictive Path Integral control, Tube-Model Predictive Path Integral Control, and Robust Model Predictive Path Integral Control, and allows for these algorithms to be used across many pre-existing dynamics models and cost functions. Furthermore, researchers can create their own dynamics models or cost functions following our API definitions without needing to change the actual Model Predictive Path Integral Control code. Finally, we compare computational performance to other popular implementations of Model Predictive Path Integral Control over a variety of GPUs to show the real-time capabilities our library can allow for. Library code can be found at: https://acdslab.github.io/mppi-generic-website/ .
Gaussian Process Barrier States for Safe Trajectory Optimization and Control
Dec 01, 2022This paper proposes embedded Gaussian Process Barrier States (GP-BaS), a methodology to safely control unmodeled dynamics of nonlinear system using Bayesian learning. Gaussian Processes (GPs) are used to model the dynamics of the safety-critical system, which is subsequently used in the GP-BaS model. We derive the barrier state dynamics utilizing the GP posterior, which is used to construct a safety embedded Gaussian process dynamical model (GPDM). We show that the safety-critical system can be controlled to remain inside the safe region as long as we can design a controller that renders the BaS-GPDM's trajectories bounded (or asymptotically stable). The proposed approach overcomes various limitations in early attempts at combining GPs with barrier functions due to the abstention of restrictive assumptions such as linearity of the system with respect to control, relative degree of the constraints and number or nature of constraints. This work is implemented on various examples for trajectory optimization and control including optimal stabilization of unstable linear system and safe trajectory optimization of a Dubins vehicle navigating through an obstacle course and on a quadrotor in an obstacle avoidance task using GP differentiable dynamic programming (GP-DDP). The proposed framework is capable of maintaining safe optimization and control of unmodeled dynamics and is purely data driven.
Robustifying Reinforcement Learning Policies with $\mathcal{L}_1$ Adaptive Control
Jun 04, 2021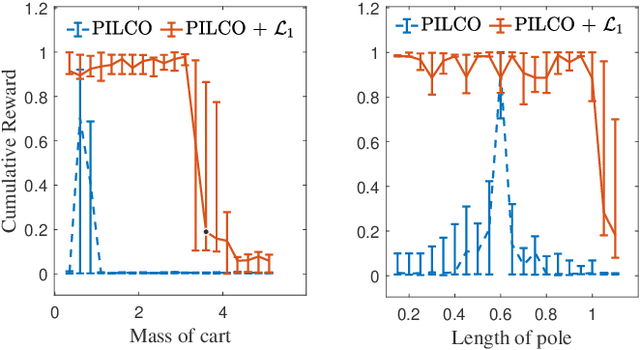
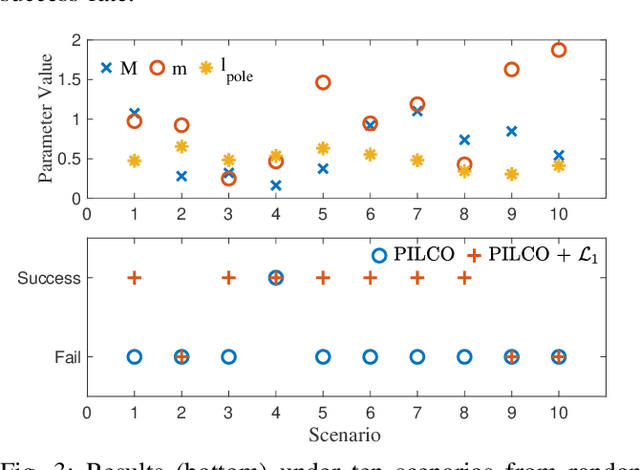
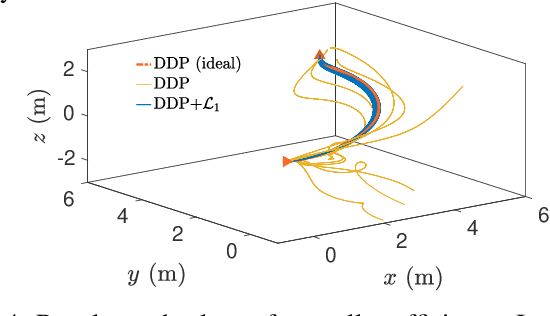
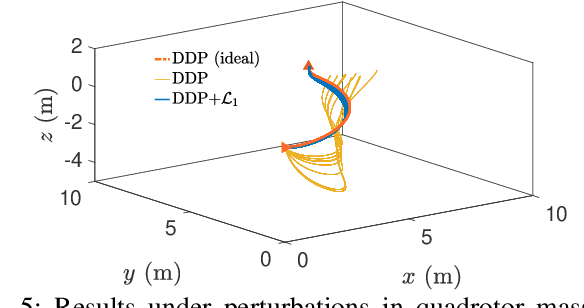
A reinforcement learning (RL) policy trained in a nominal environment could fail in a new/perturbed environment due to the existence of dynamic variations. Existing robust methods try to obtain a fixed policy for all envisioned dynamic variation scenarios through robust or adversarial training. These methods could lead to conservative performance due to emphasis on the worst case, and often involve tedious modifications to the training environment. We propose an approach to robustifying a pre-trained non-robust RL policy with $\mathcal{L}_1$ adaptive control. Leveraging the capability of an $\mathcal{L}_1$ control law in the fast estimation of and active compensation for dynamic variations, our approach can significantly improve the robustness of an RL policy trained in a standard (i.e., non-robust) way, either in a simulator or in the real world. Numerical experiments are provided to validate the efficacy of the proposed approach.
Propagating Uncertainty through the tanh Function with Application to Reservoir Computing
Jun 25, 2018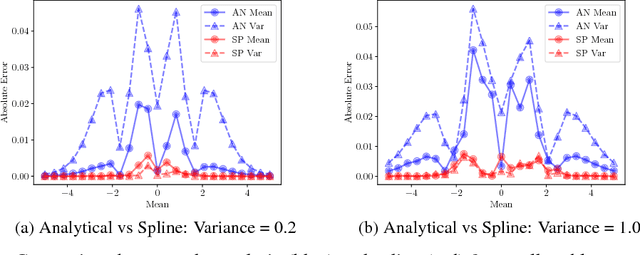
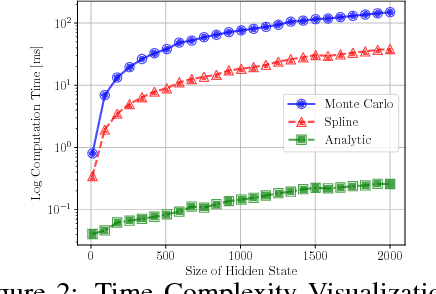
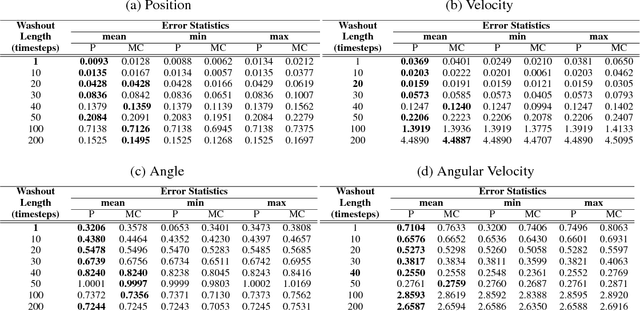
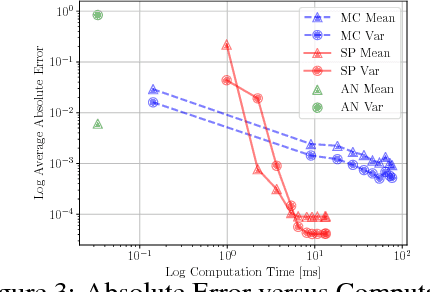
Many neural networks use the tanh activation function, however when given a probability distribution as input, the problem of computing the output distribution in neural networks with tanh activation has not yet been addressed. One important example is the initialization of the echo state network in reservoir computing, where random initialization of the reservoir requires time to wash out the initial conditions, thereby wasting precious data and computational resources. Motivated by this problem, we propose a novel solution utilizing a moment based approach to propagate uncertainty through an Echo State Network to reduce the washout time. In this work, we contribute two new methods to propagate uncertainty through the tanh activation function and propose the Probabilistic Echo State Network (PESN), a method that is shown to have better average performance than deterministic Echo State Networks given the random initialization of reservoir states. Additionally we test single and multi-step uncertainty propagation of our method on two regression tasks and show that we are able to recover similar means and variances as computed by Monte-Carlo simulations.