 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDUGAE: Unified Geometry and Attribute Enhancement via Spatiotemporal Correlations for G-PCC Compressed Dynamic Point Clouds
Mar 27, 2026Existing post-decoding quality enhancement methods for point clouds are designed for static data and typically process each frame independently. As a result, they cannot effectively exploit the spatiotemporal correlations present in point cloud sequences.We propose a unified geometry and attribute enhancement framework (DUGAE) for G-PCC compressed dynamic point clouds that explicitly exploits inter-frame spatiotemporal correlations in both geometry and attributes. First, a dynamic geometry enhancement network (DGE-Net) based on sparse convolution (SPConv) and feature-domain geometry motion compensation (GMC) aligns and aggregates spatiotemporal information. Then, a detail-aware k-nearest neighbors (DA-KNN) recoloring module maps the original attributes onto the enhanced geometry at the encoder side, improving mapping completeness and preserving attribute details. Finally, a dynamic attribute enhancement network (DAE-Net) with dedicated temporal feature extraction and feature-domain attribute motion compensation (AMC) refines attributes by modeling complex spatiotemporal correlations. On seven dynamic point clouds from the 8iVFB v2, Owlii, and MVUB datasets, DUGAE significantly enhanced the performance of the latest G-PCC geometry-based solid content test model (GeS-TM v10). For geometry (D1), it achieved an average BD-PSNR gain of 11.03 dB and a 93.95% BD-bitrate reduction. For the luma component, it achieved a 4.23 dB BD-PSNR gain with a 66.61% BD-bitrate reduction. DUGAE also improved perceptual quality (as measured by PCQM) and outperformed V-PCC. Our source code will be released on GitHub at: https://github.com/yuanhui0325/DUGAE
Point Cloud Feature Coding for Object Detection over an Error-Prone Cloud-Edge Collaborative System
Mar 04, 2026Cloud-edge collaboration enhances machine perception by combining the strengths of edge and cloud computing. Edge devices capture raw data (e.g., 3D point clouds) and extract salient features, which are sent to the cloud for deeper analysis and data fusion. However, efficiently and reliably transmitting features between cloud and edge devices remains a challenging problem. We focus on point cloud-based object detection and propose a task-driven point cloud compression and reliable transmission framework based on source and channel coding. To meet the low-latency and low-power requirements of edge devices, we design a lightweight yet effective feature compaction module that compresses the deepest feature among multi-scale representations by removing task-irrelevant regions and applying channel-wise dimensionality reduction to task-relevant areas. Then, a signal-to-noise ratio (SNR)-adaptive channel encoder dynamically encodes the attribute information of the compacted features, while a Low-Density Parity-Check (LDPC) encoder ensures reliable transmission of geometric information. At the cloud side, an SNR-adaptive channel decoder guides the decoding of attribute information, and the LDPC decoder corrects geometry errors. Finally, a feature decompaction module restores the channel-wise dimensionality, and a diffusion-based feature upsampling module reconstructs shallow-layer features, enabling multi-scale feature reconstruction. On the KITTI dataset, our method achieved a 172-fold reduction in feature size with 3D average precision scores of 93.17%, 86.96%, and 77.25% for easy, moderate, and hard objects, respectively, over a 0 dB SNR wireless channel. Our source code will be released on GitHub at: https://github.com/yuanhui0325/T-PCFC.
UGAE: Unified Geometry and Attribute Enhancement for G-PCC Compressed Point Clouds
Oct 27, 2025Lossy compression of point clouds reduces storage and transmission costs; however, it inevitably leads to irreversible distortion in geometry structure and attribute information. To address these issues, we propose a unified geometry and attribute enhancement (UGAE) framework, which consists of three core components: post-geometry enhancement (PoGE), pre-attribute enhancement (PAE), and post-attribute enhancement (PoAE). In PoGE, a Transformer-based sparse convolutional U-Net is used to reconstruct the geometry structure with high precision by predicting voxel occupancy probabilities. Building on the refined geometry structure, PAE introduces an innovative enhanced geometry-guided recoloring strategy, which uses a detail-aware K-Nearest Neighbors (DA-KNN) method to achieve accurate recoloring and effectively preserve high-frequency details before attribute compression. Finally, at the decoder side, PoAE uses an attribute residual prediction network with a weighted mean squared error (W-MSE) loss to enhance the quality of high-frequency regions while maintaining the fidelity of low-frequency regions. UGAE significantly outperformed existing methods on three benchmark datasets: 8iVFB, Owlii, and MVUB. Compared to the latest G-PCC test model (TMC13v29), UGAE achieved an average BD-PSNR gain of 9.98 dB and 90.98% BD-bitrate savings for geometry under the D1 metric, as well as a 3.67 dB BD-PSNR improvement with 56.88% BD-bitrate savings for attributes on the Y component. Additionally, it improved perceptual quality significantly.
Teacher Motion Priors: Enhancing Robot Locomotion over Challenging Terrain
Apr 14, 2025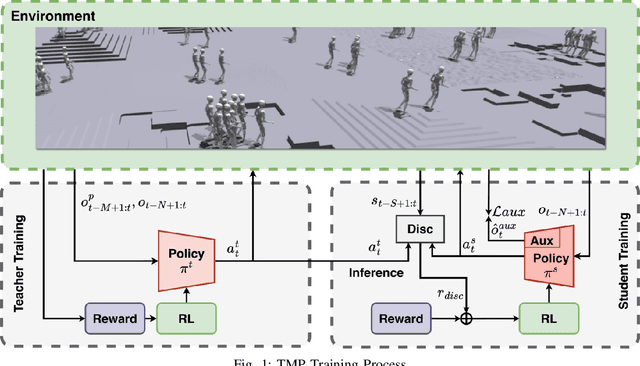
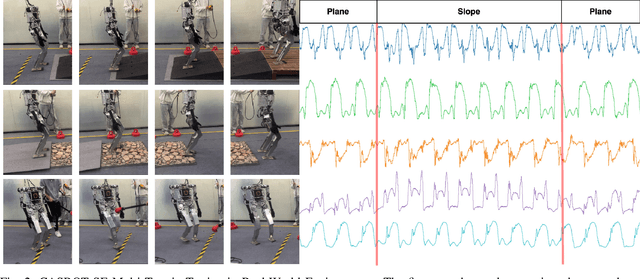
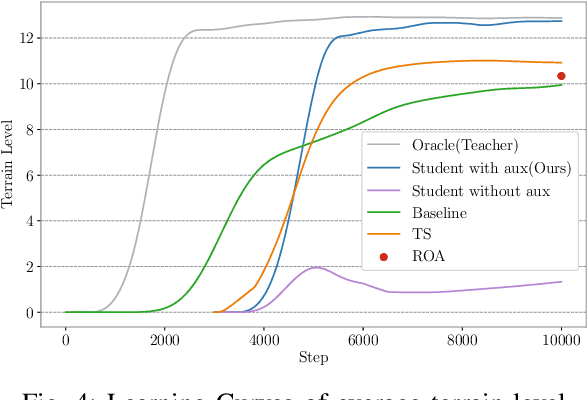
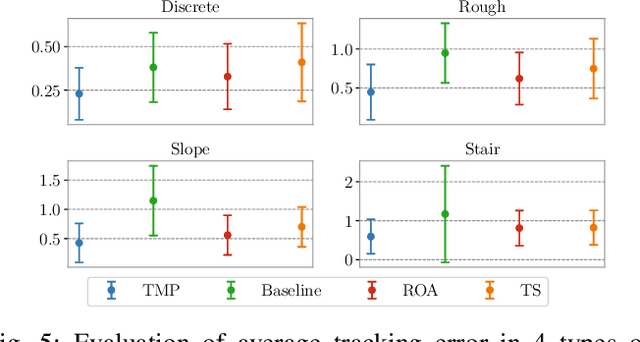
Achieving robust locomotion on complex terrains remains a challenge due to high dimensional control and environmental uncertainties. This paper introduces a teacher prior framework based on the teacher student paradigm, integrating imitation and auxiliary task learning to improve learning efficiency and generalization. Unlike traditional paradigms that strongly rely on encoder-based state embeddings, our framework decouples the network design, simplifying the policy network and deployment. A high performance teacher policy is first trained using privileged information to acquire generalizable motion skills. The teacher's motion distribution is transferred to the student policy, which relies only on noisy proprioceptive data, via a generative adversarial mechanism to mitigate performance degradation caused by distributional shifts. Additionally, auxiliary task learning enhances the student policy's feature representation, speeding up convergence and improving adaptability to varying terrains. The framework is validated on a humanoid robot, showing a great improvement in locomotion stability on dynamic terrains and significant reductions in development costs. This work provides a practical solution for deploying robust locomotion strategies in humanoid robots.
CROPS: A Deployable Crop Management System Over All Possible State Availabilities
Nov 09, 2024



Exploring the optimal management strategy for nitrogen and irrigation has a significant impact on crop yield, economic profit, and the environment. To tackle this optimization challenge, this paper introduces a deployable \textbf{CR}op Management system \textbf{O}ver all \textbf{P}ossible \textbf{S}tate availabilities (CROPS). CROPS employs a language model (LM) as a reinforcement learning (RL) agent to explore optimal management strategies within the Decision Support System for Agrotechnology Transfer (DSSAT) crop simulations. A distinguishing feature of this system is that the states used for decision-making are partially observed through random masking. Consequently, the RL agent is tasked with two primary objectives: optimizing management policies and inferring masked states. This approach significantly enhances the RL agent's robustness and adaptability across various real-world agricultural scenarios. Extensive experiments on maize crops in Florida, USA, and Zaragoza, Spain, validate the effectiveness of CROPS. Not only did CROPS achieve State-of-the-Art (SOTA) results across various evaluation metrics such as production, profit, and sustainability, but the trained management policies are also immediately deployable in over of ten millions of real-world contexts. Furthermore, the pre-trained policies possess a noise resilience property, which enables them to minimize potential sensor biases, ensuring robustness and generalizability. Finally, unlike previous methods, the strength of CROPS lies in its unified and elegant structure, which eliminates the need for pre-defined states or multi-stage training. These advancements highlight the potential of CROPS in revolutionizing agricultural practices.
The New Agronomists: Language Models are Experts in Crop Management
Mar 28, 2024


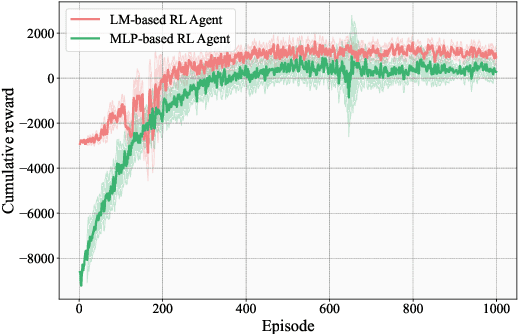
Crop management plays a crucial role in determining crop yield, economic profitability, and environmental sustainability. Despite the availability of management guidelines, optimizing these practices remains a complex and multifaceted challenge. In response, previous studies have explored using reinforcement learning with crop simulators, typically employing simple neural-network-based reinforcement learning (RL) agents. Building on this foundation, this paper introduces a more advanced intelligent crop management system. This system uniquely combines RL, a language model (LM), and crop simulations facilitated by the Decision Support System for Agrotechnology Transfer (DSSAT). We utilize deep RL, specifically a deep Q-network, to train management policies that process numerous state variables from the simulator as observations. A novel aspect of our approach is the conversion of these state variables into more informative language, facilitating the language model's capacity to understand states and explore optimal management practices. The empirical results reveal that the LM exhibits superior learning capabilities. Through simulation experiments with maize crops in Florida (US) and Zaragoza (Spain), the LM not only achieves state-of-the-art performance under various evaluation metrics but also demonstrates a remarkable improvement of over 49\% in economic profit, coupled with reduced environmental impact when compared to baseline methods. Our code is available at \url{https://github.com/jingwu6/LM_AG}.
A Semiparametric Instrumented Difference-in-Differences Approach to Policy Learning
Oct 14, 2023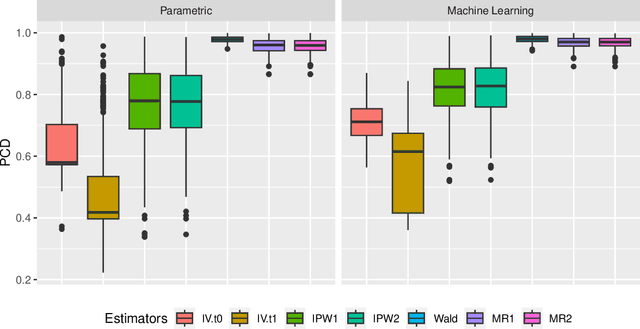
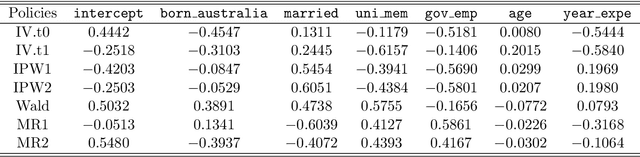
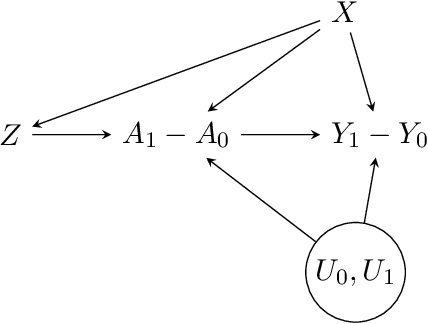
Recently, there has been a surge in methodological development for the difference-in-differences (DiD) approach to evaluate causal effects. Standard methods in the literature rely on the parallel trends assumption to identify the average treatment effect on the treated. However, the parallel trends assumption may be violated in the presence of unmeasured confounding, and the average treatment effect on the treated may not be useful in learning a treatment assignment policy for the entire population. In this article, we propose a general instrumented DiD approach for learning the optimal treatment policy. Specifically, we establish identification results using a binary instrumental variable (IV) when the parallel trends assumption fails to hold. Additionally, we construct a Wald estimator, novel inverse probability weighting (IPW) estimators, and a class of semiparametric efficient and multiply robust estimators, with theoretical guarantees on consistency and asymptotic normality, even when relying on flexible machine learning algorithms for nuisance parameters estimation. Furthermore, we extend the instrumented DiD to the panel data setting. We evaluate our methods in extensive simulations and a real data application.
Positivity-free Policy Learning with Observational Data
Oct 10, 2023

Policy learning utilizing observational data is pivotal across various domains, with the objective of learning the optimal treatment assignment policy while adhering to specific constraints such as fairness, budget, and simplicity. This study introduces a novel positivity-free (stochastic) policy learning framework designed to address the challenges posed by the impracticality of the positivity assumption in real-world scenarios. This framework leverages incremental propensity score policies to adjust propensity score values instead of assigning fixed values to treatments. We characterize these incremental propensity score policies and establish identification conditions, employing semiparametric efficiency theory to propose efficient estimators capable of achieving rapid convergence rates, even when integrated with advanced machine learning algorithms. This paper provides a thorough exploration of the theoretical guarantees associated with policy learning and validates the proposed framework's finite-sample performance through comprehensive numerical experiments, ensuring the identification of causal effects from observational data is both robust and reliable.
$\mathcal{L}_1$Quad: $\mathcal{L}_1$ Adaptive Augmentation of Geometric Control for Agile Quadrotors with Performance Guarantees
Feb 14, 2023
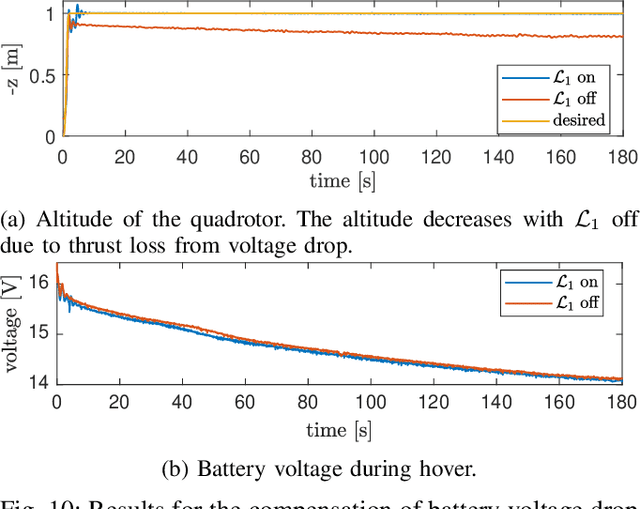

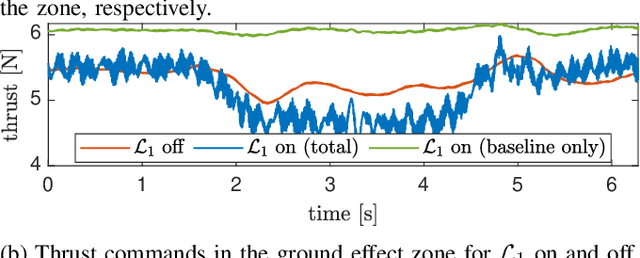
Quadrotors that can operate safely in the presence of imperfect model knowledge and external disturbances are crucial in safety-critical applications. We present L1Quad, a control architecture for quadrotors based on the L1 adaptive control. L1Quad enables safe tubes centered around a desired trajectory that the quadrotor is always guaranteed to remain inside. Our design applies to both the rotational and the translational dynamics of the quadrotor. We lump various types of uncertainties and disturbances as unknown nonlinear (time- and state-dependent) forces and moments. Without assuming or enforcing parametric structures, L1Quad can accurately estimate and compensate for these unknown forces and moments. Extensive experimental results demonstrate that L1Quad is able to significantly outperform baseline controllers under a variety of uncertainties with consistently small tracking errors.
Efficient and robust transfer learning of optimal individualized treatment regimes with right-censored survival data
Jan 13, 2023An individualized treatment regime (ITR) is a decision rule that assigns treatments based on patients' characteristics. The value function of an ITR is the expected outcome in a counterfactual world had this ITR been implemented. Recently, there has been increasing interest in combining heterogeneous data sources, such as leveraging the complementary features of randomized controlled trial (RCT) data and a large observational study (OS). Usually, a covariate shift exists between the source and target population, rendering the source-optimal ITR unnecessarily optimal for the target population. We present an efficient and robust transfer learning framework for estimating the optimal ITR with right-censored survival data that generalizes well to the target population. The value function accommodates a broad class of functionals of survival distributions, including survival probabilities and restrictive mean survival times (RMSTs). We propose a doubly robust estimator of the value function, and the optimal ITR is learned by maximizing the value function within a pre-specified class of ITRs. We establish the $N^{-1/3}$ rate of convergence for the estimated parameter indexing the optimal ITR, and show that the proposed optimal value estimator is consistent and asymptotically normal even with flexible machine learning methods for nuisance parameter estimation. We evaluate the empirical performance of the proposed method by simulation studies and a real data application of sodium bicarbonate therapy for patients with severe metabolic acidaemia in the intensive care unit (ICU), combining a RCT and an observational study with heterogeneity.