 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Crop Management with Reinforcement Learning and Imitation Learning
Sep 20, 2022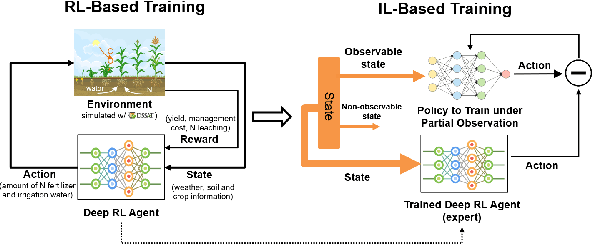
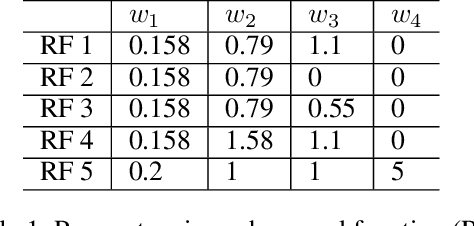
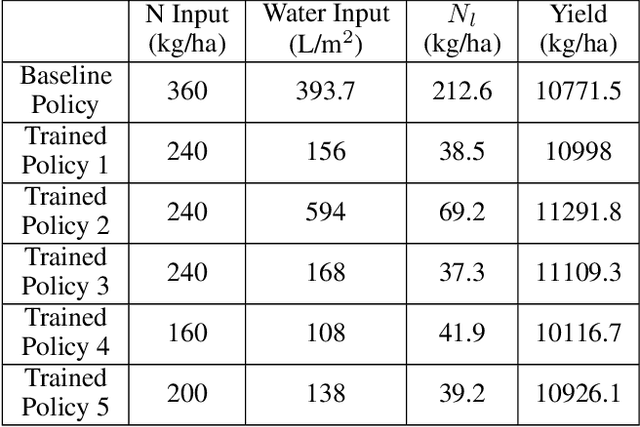
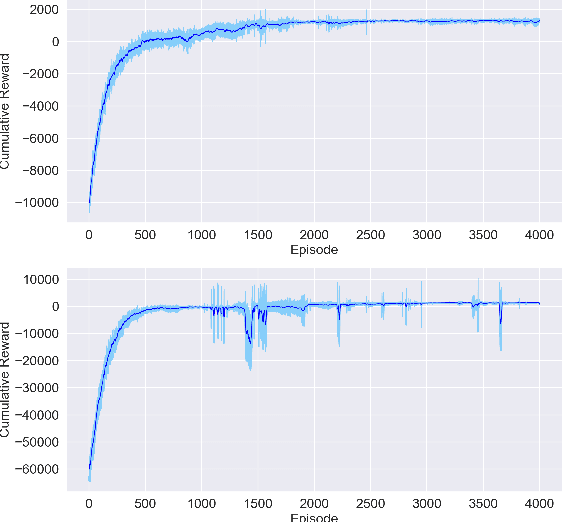
Crop management, including nitrogen (N) fertilization and irrigation management, has a significant impact on the crop yield, economic profit, and the environment. Although management guidelines exist, it is challenging to find the optimal management practices given a specific planting environment and a crop. Previous work used reinforcement learning (RL) and crop simulators to solve the problem, but the trained policies either have limited performance or are not deployable in the real world. In this paper, we present an intelligent crop management system which optimizes the N fertilization and irrigation simultaneously via RL, imitation learning (IL), and crop simulations using the Decision Support System for Agrotechnology Transfer (DSSAT). We first use deep RL, in particular, deep Q-network, to train management policies that require all state information from the simulator as observations (denoted as full observation). We then invoke IL to train management policies that only need a limited amount of state information that can be readily obtained in the real world (denoted as partial observation) by mimicking the actions of the previously RL-trained policies under full observation. We conduct experiments on a case study using maize in Florida and compare trained policies with a maize management guideline in simulations. Our trained policies under both full and partial observations achieve better outcomes, resulting in a higher profit or a similar profit with a smaller environmental impact. Moreover, the partial-observation management policies are directly deployable in the real world as they use readily available information.
Optimizing Nitrogen Management with Deep Reinforcement Learning and Crop Simulations
Apr 21, 2022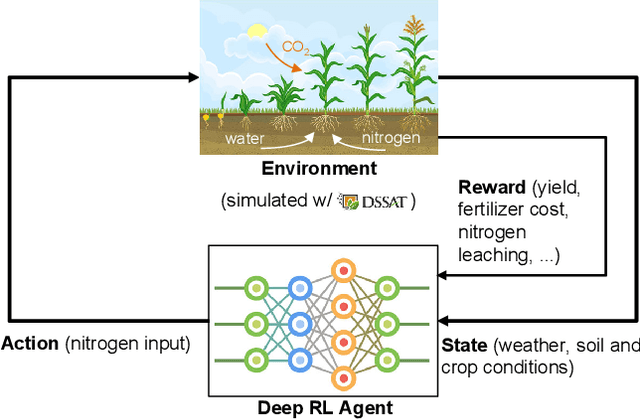

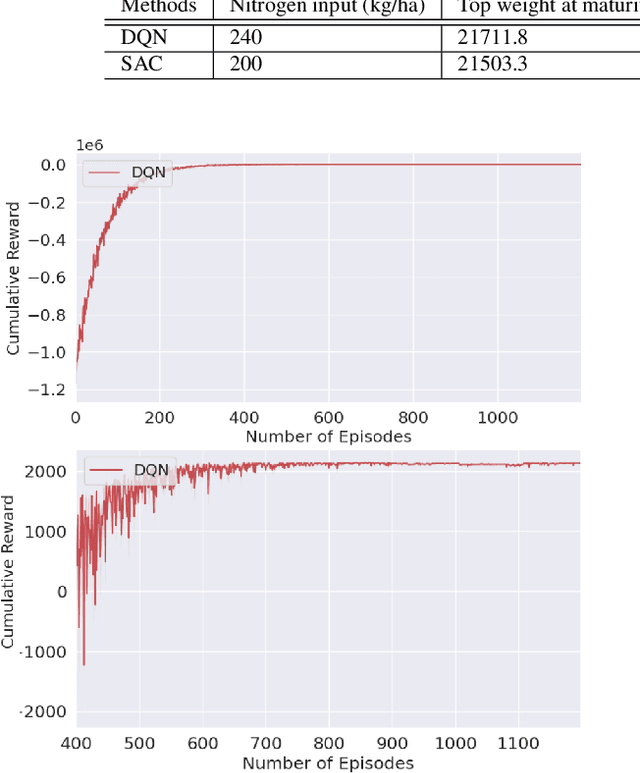

Nitrogen (N) management is critical to sustain soil fertility and crop production while minimizing the negative environmental impact, but is challenging to optimize. This paper proposes an intelligent N management system using deep reinforcement learning (RL) and crop simulations with Decision Support System for Agrotechnology Transfer (DSSAT). We first formulate the N management problem as an RL problem. We then train management policies with deep Q-network and soft actor-critic algorithms, and the Gym-DSSAT interface that allows for daily interactions between the simulated crop environment and RL agents. According to the experiments on the maize crop in both Iowa and Florida in the US, our RL-trained policies outperform previous empirical methods by achieving higher or similar yield while using less fertilizers