 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Crop Management with Reinforcement Learning and Imitation Learning
Sep 20, 2022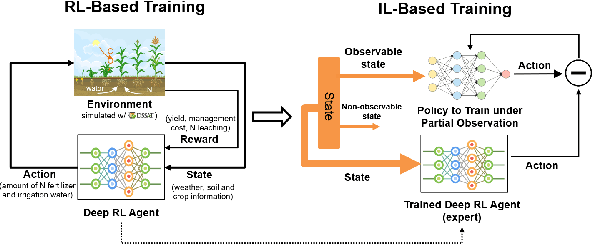
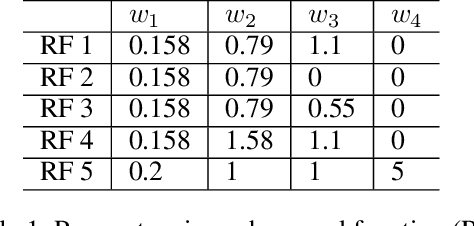
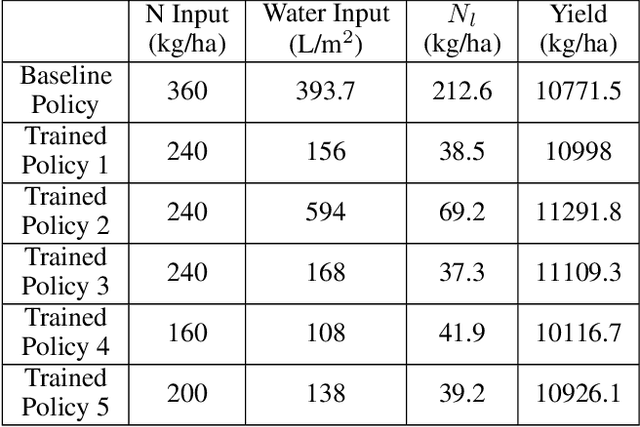
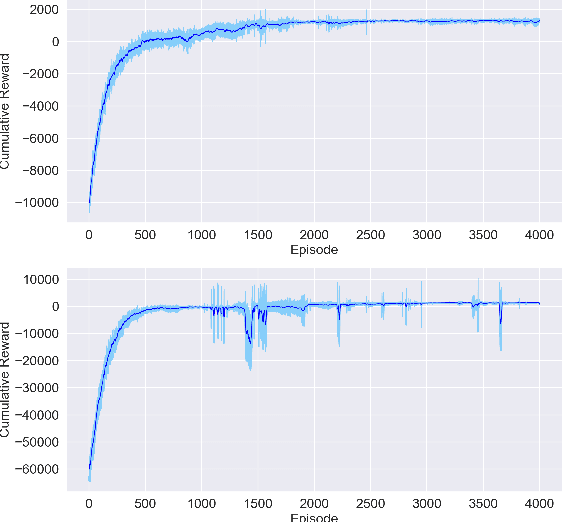
Crop management, including nitrogen (N) fertilization and irrigation management, has a significant impact on the crop yield, economic profit, and the environment. Although management guidelines exist, it is challenging to find the optimal management practices given a specific planting environment and a crop. Previous work used reinforcement learning (RL) and crop simulators to solve the problem, but the trained policies either have limited performance or are not deployable in the real world. In this paper, we present an intelligent crop management system which optimizes the N fertilization and irrigation simultaneously via RL, imitation learning (IL), and crop simulations using the Decision Support System for Agrotechnology Transfer (DSSAT). We first use deep RL, in particular, deep Q-network, to train management policies that require all state information from the simulator as observations (denoted as full observation). We then invoke IL to train management policies that only need a limited amount of state information that can be readily obtained in the real world (denoted as partial observation) by mimicking the actions of the previously RL-trained policies under full observation. We conduct experiments on a case study using maize in Florida and compare trained policies with a maize management guideline in simulations. Our trained policies under both full and partial observations achieve better outcomes, resulting in a higher profit or a similar profit with a smaller environmental impact. Moreover, the partial-observation management policies are directly deployable in the real world as they use readily available information.
The discriminative Kalman filter for nonlinear and non-Gaussian sequential Bayesian filtering
Aug 30, 2016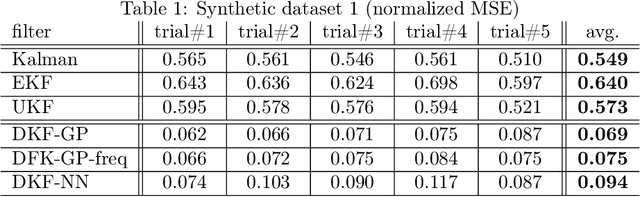
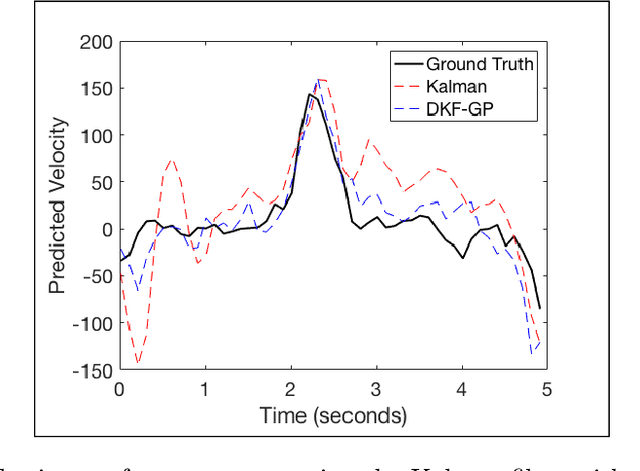
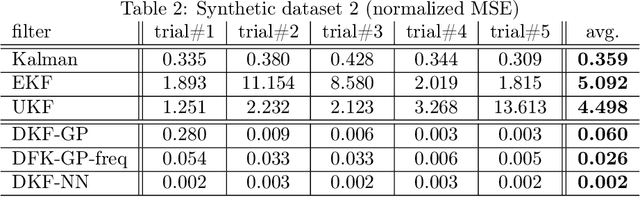
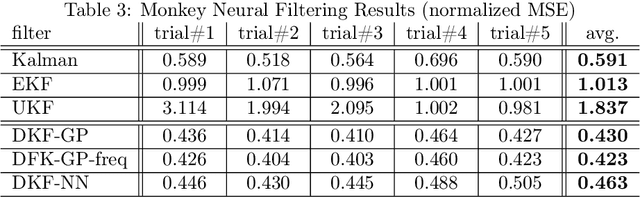
The Kalman filter (KF) is used in a variety of applications for computing the posterior distribution of latent states in a state space model. The model requires a linear relationship between states and observations. Extensions to the Kalman filter have been proposed that incorporate linear approximations to nonlinear models, such as the extended Kalman filter (EKF) and the unscented Kalman filter (UKF). However, we argue that in cases where the dimensionality of observed variables greatly exceeds the dimensionality of state variables, a model for $p(\text{state}|\text{observation})$ proves both easier to learn and more accurate for latent space estimation. We derive and validate what we call the discriminative Kalman filter (DKF): a closed-form discriminative version of Bayesian filtering that readily incorporates off-the-shelf discriminative learning techniques. Further, we demonstrate that given mild assumptions, highly non-linear models for $p(\text{state}|\text{observation})$ can be specified. We motivate and validate on synthetic datasets and in neural decoding from non-human primates, showing substantial increases in decoding performance versus the standard Kalman filter.
Inconsistency of Pitman-Yor process mixtures for the number of components
Aug 30, 2013


In many applications, a finite mixture is a natural model, but it can be difficult to choose an appropriate number of components. To circumvent this choice, investigators are increasingly turning to Dirichlet process mixtures (DPMs), and Pitman-Yor process mixtures (PYMs), more generally. While these models may be well-suited for Bayesian density estimation, many investigators are using them for inferences about the number of components, by considering the posterior on the number of components represented in the observed data. We show that this posterior is not consistent --- that is, on data from a finite mixture, it does not concentrate at the true number of components. This result applies to a large class of nonparametric mixtures, including DPMs and PYMs, over a wide variety of families of component distributions, including essentially all discrete families, as well as continuous exponential families satisfying mild regularity conditions (such as multivariate Gaussians).