 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Variance-reduced Estimation from Generative EHR Models: The SCOPE and REACH Estimators
Feb 03, 2026Generative models trained using self-supervision of tokenized electronic health record (EHR) timelines show promise for clinical outcome prediction. This is typically done using Monte Carlo simulation for future patient trajectories. However, existing approaches suffer from three key limitations: sparse estimate distributions that poorly differentiate patient risk levels, extreme computational costs, and high sampling variance. We propose two new estimators: the Sum of Conditional Outcome Probability Estimator (SCOPE) and Risk Estimation from Anticipated Conditional Hazards (REACH), that leverage next-token probability distributions discarded by standard Monte Carlo. We prove both estimators are unbiased and that REACH guarantees variance reduction over Monte Carlo sampling for any model and outcome. Empirically, on hospital mortality prediction in MIMIC-IV using the ETHOS-ARES framework, SCOPE and REACH match 100-sample Monte Carlo performance using only 10-11 samples (95% CI: [9,11]), representing a ~10x reduction in inference cost without degrading calibration. For ICU admission prediction, efficiency gains are more modest (~1.2x), which we attribute to the outcome's lower "spontaneity," a property we characterize theoretically and empirically. These methods substantially improve the feasibility of deploying generative EHR models in resource-constrained clinical settings.
Quantifying surprise in clinical care: Detecting highly informative events in electronic health records with foundation models
Jul 30, 2025


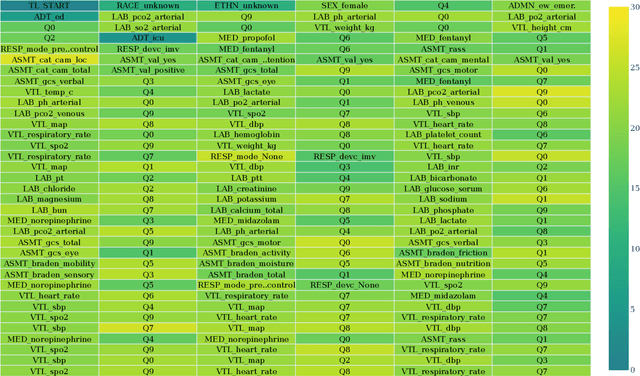
We present a foundation model-derived method to identify highly informative tokens and events in electronic health records. Our approach considers incoming data in the entire context of a patient's hospitalization and so can flag anomalous events that rule-based approaches would consider within a normal range. We demonstrate that the events our model flags are significant for predicting downstream patient outcomes and that a fraction of events identified as carrying little information can safely be dropped. Additionally, we show how informativeness can help interpret the predictions of prognostic models trained on foundation model-derived representations.
ProtoECGNet: Case-Based Interpretable Deep Learning for Multi-Label ECG Classification with Contrastive Learning
Apr 15, 2025Deep learning-based electrocardiogram (ECG) classification has shown impressive performance but clinical adoption has been slowed by the lack of transparent and faithful explanations. Post hoc methods such as saliency maps may fail to reflect a model's true decision process. Prototype-based reasoning offers a more transparent alternative by grounding decisions in similarity to learned representations of real ECG segments, enabling faithful, case-based explanations. We introduce ProtoECGNet, a prototype-based deep learning model for interpretable, multi-label ECG classification. ProtoECGNet employs a structured, multi-branch architecture that reflects clinical interpretation workflows: it integrates a 1D CNN with global prototypes for rhythm classification, a 2D CNN with time-localized prototypes for morphology-based reasoning, and a 2D CNN with global prototypes for diffuse abnormalities. Each branch is trained with a prototype loss designed for multi-label learning, combining clustering, separation, diversity, and a novel contrastive loss that encourages appropriate separation between prototypes of unrelated classes while allowing clustering for frequently co-occurring diagnoses. We evaluate ProtoECGNet on all 71 diagnostic labels from the PTB-XL dataset, demonstrating competitive performance relative to state-of-the-art black-box models while providing structured, case-based explanations. To assess prototype quality, we conduct a structured clinician review of the final model's projected prototypes, finding that they are rated as representative and clear. ProtoECGNet shows that prototype learning can be effectively scaled to complex, multi-label time-series classification, offering a practical path toward transparent and trustworthy deep learning models for clinical decision support.
Foundation models for electronic health records: representation dynamics and transferability
Apr 14, 2025



Foundation models (FMs) trained on electronic health records (EHRs) have shown strong performance on a range of clinical prediction tasks. However, adapting these models to local health systems remains challenging due to limited data availability and resource constraints. In this study, we investigated what these models learn and evaluated the transferability of an FM trained on MIMIC-IV to an institutional EHR dataset at the University of Chicago Medical Center. We assessed their ability to identify outlier patients and examined representation-space patient trajectories in relation to future clinical outcomes. We also evaluated the performance of supervised fine-tuned classifiers on both source and target datasets. Our findings offer insights into the adaptability of FMs across different healthcare systems, highlight considerations for their effective implementation, and provide an empirical analysis of the underlying factors that contribute to their predictive performance.
Deep Low-Density Separation for Semi-Supervised Classification
May 22, 2022Given a small set of labeled data and a large set of unlabeled data, semi-supervised learning (SSL) attempts to leverage the location of the unlabeled datapoints in order to create a better classifier than could be obtained from supervised methods applied to the labeled training set alone. Effective SSL imposes structural assumptions on the data, e.g. that neighbors are more likely to share a classification or that the decision boundary lies in an area of low density. For complex and high-dimensional data, neural networks can learn feature embeddings to which traditional SSL methods can then be applied in what we call hybrid methods. Previously-developed hybrid methods iterate between refining a latent representation and performing graph-based SSL on this representation. In this paper, we introduce a novel hybrid method that instead applies low-density separation to the embedded features. We describe it in detail and discuss why low-density separation may be better suited for SSL on neural network-based embeddings than graph-based algorithms. We validate our method using in-house customer survey data and compare it to other state-of-the-art learning methods. Our approach effectively classifies thousands of unlabeled users from a relatively small number of hand-classified examples.
Neuroevolutionary Feature Representations for Causal Inference
May 21, 2022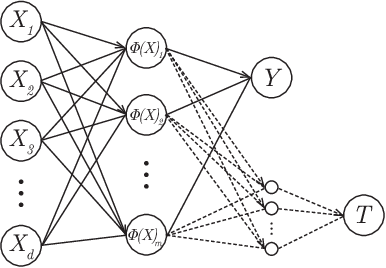
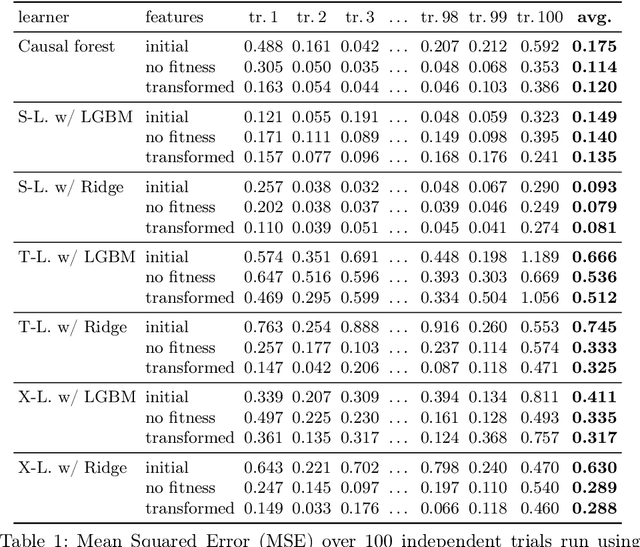
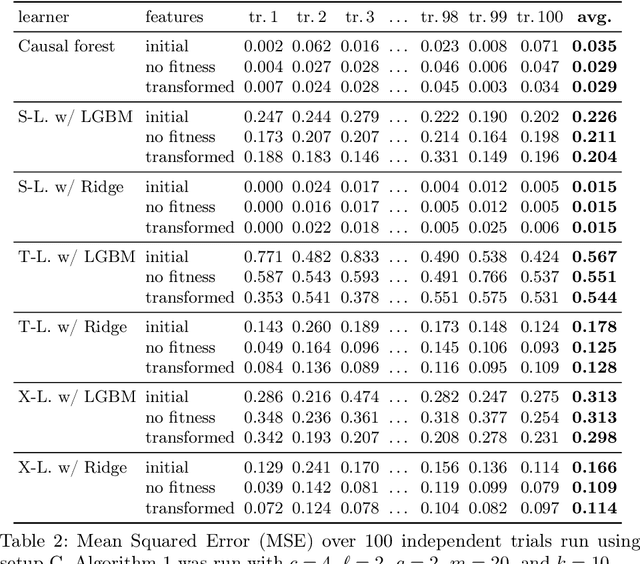
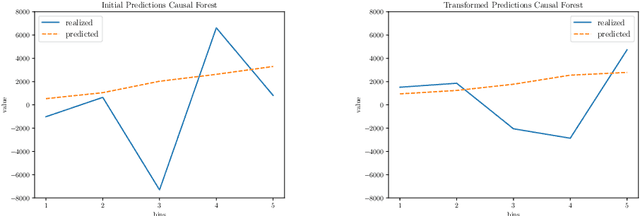
Within the field of causal inference, we consider the problem of estimating heterogeneous treatment effects from data. We propose and validate a novel approach for learning feature representations to aid the estimation of the conditional average treatment effect or CATE. Our method focuses on an intermediate layer in a neural network trained to predict the outcome from the features. In contrast to previous approaches that encourage the distribution of representations to be treatment-invariant, we leverage a genetic algorithm that optimizes over representations useful for predicting the outcome to select those less useful for predicting the treatment. This allows us to retain information within the features useful for predicting outcome even if that information may be related to treatment assignment. We validate our method on synthetic examples and illustrate its use on a real life dataset.
Discriminative Bayesian Filtering Lends Momentum to the Stochastic Newton Method for Minimizing Log-Convex Functions
Apr 27, 2021
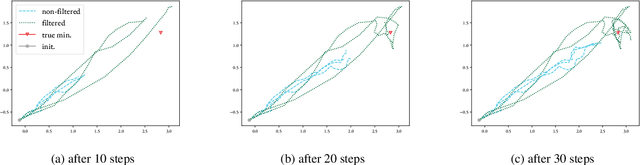
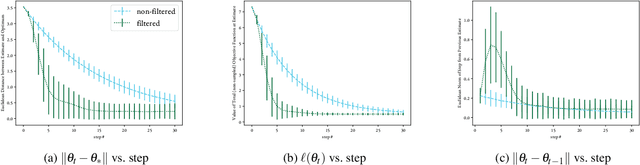
To minimize the average of a set of log-convex functions, the stochastic Newton method iteratively updates its estimate using subsampled versions of the full objective's gradient and Hessian. We contextualize this optimization problem as sequential Bayesian inference on a latent state-space model with a discriminatively-specified observation process. Applying Bayesian filtering then yields a novel optimization algorithm that considers the entire history of gradients and Hessians when forming an update. We establish matrix-based conditions under which the effect of older observations diminishes over time, in a manner analogous to Polyak's heavy ball momentum. We illustrate various aspects of our approach with an example and review other relevant innovations for the stochastic Newton method.
A Discriminative Approach to Bayesian Filtering with Applications to Human Neural Decoding
Jul 17, 2018

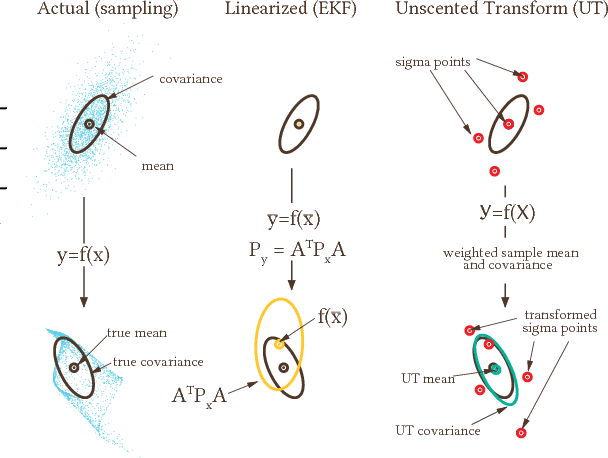

Given a stationary state-space model that relates a sequence of hidden states and corresponding measurements or observations, Bayesian filtering provides a principled statistical framework for inferring the posterior distribution of the current state given all measurements up to the present time. For example, the Apollo lunar module implemented a Kalman filter to infer its location from a sequence of earth-based radar measurements and land safely on the moon. To perform Bayesian filtering, we require a measurement model that describes the conditional distribution of each observation given state. The Kalman filter takes this measurement model to be linear, Gaussian. Here we show how a nonlinear, Gaussian approximation to the distribution of state given observation can be used in conjunction with Bayes' rule to build a nonlinear, non-Gaussian measurement model. The resulting approach, called the Discriminative Kalman Filter (DKF), retains fast closed-form updates for the posterior. We argue there are many cases where the distribution of state given measurement is better-approximated as Gaussian, especially when the dimensionality of measurements far exceeds that of states and the Bernstein-von Mises theorem applies. Online neural decoding for brain-computer interfaces provides a motivating example, where filtering incorporates increasingly detailed measurements of neural activity to provide users control over external devices. Within the BrainGate2 clinical trial, the DKF successfully enabled three volunteers with quadriplegia to control an on-screen cursor in real-time using mental imagery alone. Participant "T9" used the DKF to type out messages on a tablet PC.
The discriminative Kalman filter for nonlinear and non-Gaussian sequential Bayesian filtering
Aug 30, 2016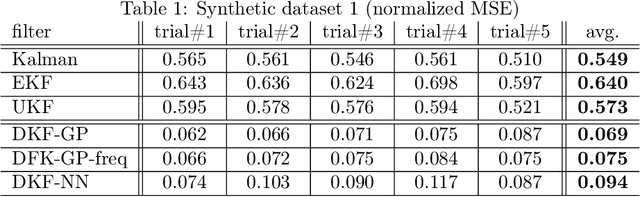
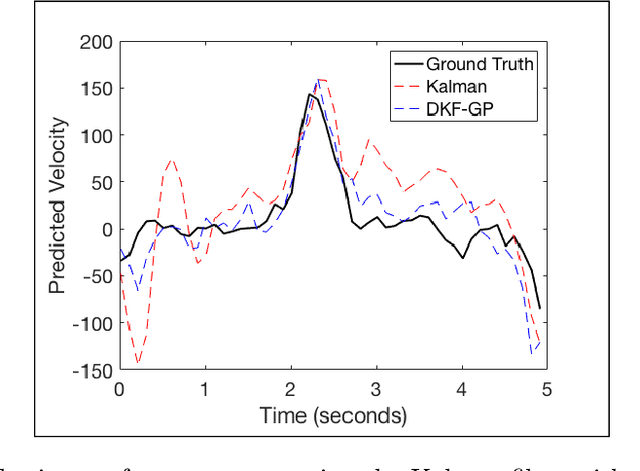
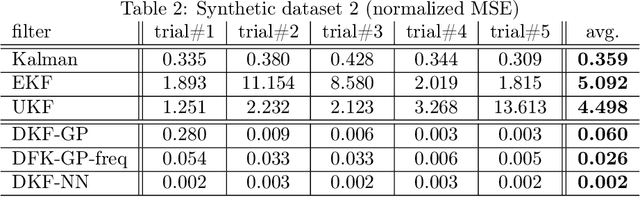
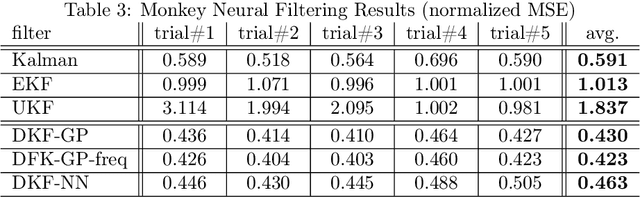
The Kalman filter (KF) is used in a variety of applications for computing the posterior distribution of latent states in a state space model. The model requires a linear relationship between states and observations. Extensions to the Kalman filter have been proposed that incorporate linear approximations to nonlinear models, such as the extended Kalman filter (EKF) and the unscented Kalman filter (UKF). However, we argue that in cases where the dimensionality of observed variables greatly exceeds the dimensionality of state variables, a model for $p(\text{state}|\text{observation})$ proves both easier to learn and more accurate for latent space estimation. We derive and validate what we call the discriminative Kalman filter (DKF): a closed-form discriminative version of Bayesian filtering that readily incorporates off-the-shelf discriminative learning techniques. Further, we demonstrate that given mild assumptions, highly non-linear models for $p(\text{state}|\text{observation})$ can be specified. We motivate and validate on synthetic datasets and in neural decoding from non-human primates, showing substantial increases in decoding performance versus the standard Kalman filter.