 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast nonparametric feature selection with error control using integrated path stability selection
Oct 03, 2024



Feature selection can greatly improve performance and interpretability in machine learning problems. However, existing nonparametric feature selection methods either lack theoretical error control or fail to accurately control errors in practice. Many methods are also slow, especially in high dimensions. In this paper, we introduce a general feature selection method that applies integrated path stability selection to thresholding to control false positives and the false discovery rate. The method also estimates q-values, which are better suited to high-dimensional data than p-values. We focus on two special cases of the general method based on gradient boosting (IPSSGB) and random forests (IPSSRF). Extensive simulations with RNA sequencing data show that IPSSGB and IPSSRF have better error control, detect more true positives, and are faster than existing methods. We also use both methods to detect microRNAs and genes related to ovarian cancer, finding that they make better predictions with fewer features than other methods.
Integrated path stability selection
Mar 23, 2024Stability selection is a widely used method for improving the performance of feature selection algorithms. However, stability selection has been found to be highly conservative, resulting in low sensitivity. Further, the theoretical bound on the expected number of false positives, E(FP), is relatively loose, making it difficult to know how many false positives to expect in practice. In this paper, we introduce a novel method for stability selection based on integrating the stability paths rather than maximizing over them. This yields a tighter bound on E(FP), resulting in a feature selection criterion that has higher sensitivity in practice and is better calibrated in terms of matching the target E(FP). Our proposed method requires the same amount of computation as the original stability selection algorithm, and only requires the user to specify one input parameter, a target value for E(FP). We provide theoretical bounds on performance, and demonstrate the method on simulations and real data from cancer gene expression studies.
Reproducible Parameter Inference Using Bagged Posteriors
Nov 03, 2023Under model misspecification, it is known that Bayesian posteriors often do not properly quantify uncertainty about true or pseudo-true parameters. Even more fundamentally, misspecification leads to a lack of reproducibility in the sense that the same model will yield contradictory posteriors on independent data sets from the true distribution. To define a criterion for reproducible uncertainty quantification under misspecification, we consider the probability that two confidence sets constructed from independent data sets have nonempty overlap, and we establish a lower bound on this overlap probability that holds for any valid confidence sets. We prove that credible sets from the standard posterior can strongly violate this bound, particularly in high-dimensional settings (i.e., with dimension increasing with sample size), indicating that it is not internally coherent under misspecification. To improve reproducibility in an easy-to-use and widely applicable way, we propose to apply bagging to the Bayesian posterior ("BayesBag"'); that is, to use the average of posterior distributions conditioned on bootstrapped datasets. We motivate BayesBag from first principles based on Jeffrey conditionalization and show that the bagged posterior typically satisfies the overlap lower bound. Further, we prove a Bernstein--Von Mises theorem for the bagged posterior, establishing its asymptotic normal distribution. We demonstrate the benefits of BayesBag via simulation experiments and an application to crime rate prediction.
An elementary derivation of the Chinese restaurant process from Sethuraman's stick-breaking process
Oct 15, 2018The Chinese restaurant process (CRP) and the stick-breaking process are the two most commonly used representations of the Dirichlet process. However, the usual proof of the connection between them is indirect, relying on abstract properties of the Dirichlet process that are difficult for nonexperts to verify. This short note provides a direct proof that the stick-breaking process leads to the CRP, without using any measure theory. We also discuss how the stick-breaking representation arises naturally from the CRP.
Fast and accurate approximation of the full conditional for gamma shape parameters
Jul 30, 2018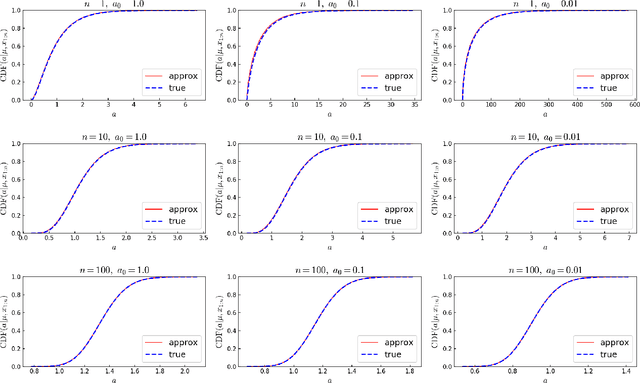


The gamma distribution arises frequently in Bayesian models, but there is not an easy-to-use conjugate prior for the shape parameter of a gamma. This inconvenience is usually dealt with by using either Metropolis-Hastings moves, rejection sampling methods, or numerical integration. However, in models with a large number of shape parameters, these existing methods are slower or more complicated than one would like, making them burdensome in practice. It turns out that the full conditional distribution of the gamma shape parameter is well approximated by a gamma distribution, even for small sample sizes, when the prior on the shape parameter is also a gamma distribution. This article introduces a quick and easy algorithm for finding a gamma distribution that approximates the full conditional distribution of the shape parameter. We empirically demonstrate the speed and accuracy of the approximation across a wide range of conditions. If exactness is required, the approximation can be used as a proposal distribution for Metropolis-Hastings.
Inconsistency of Pitman-Yor process mixtures for the number of components
Aug 30, 2013


In many applications, a finite mixture is a natural model, but it can be difficult to choose an appropriate number of components. To circumvent this choice, investigators are increasingly turning to Dirichlet process mixtures (DPMs), and Pitman-Yor process mixtures (PYMs), more generally. While these models may be well-suited for Bayesian density estimation, many investigators are using them for inferences about the number of components, by considering the posterior on the number of components represented in the observed data. We show that this posterior is not consistent --- that is, on data from a finite mixture, it does not concentrate at the true number of components. This result applies to a large class of nonparametric mixtures, including DPMs and PYMs, over a wide variety of families of component distributions, including essentially all discrete families, as well as continuous exponential families satisfying mild regularity conditions (such as multivariate Gaussians).