 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale empirical tuning and comparison of default optimizers for variational inference
Jun 05, 2026Black-box variational inference (BBVI) is a methodology for posterior approximation that relies on stochastic optimization. In practice, the stochastic optimizers underpinning BBVI generally require extensive problem-specific tuning, which undermines its promise as a truly "black box" inference algorithm. However, over the past decade, many new adaptive stochastic optimization algorithms have been developed that reduce or remove entirely the need for tuning. In this work, we investigate this new collection of adaptive methods in the context of BBVI, with the goal of establishing the current state of the art in tuning-free optimization-based inference. In particular, we present a large-scale empirical evaluation of 56 stochastic gradient-based optimization algorithms applied to 1092 Bayesian inference optimization problems, involving over 550,000 individual optimization runs and 15 core-years of compute. The optimization algorithms we evaluate are chosen to represent a wide spectrum of recent approaches and the benchmark problems are chosen to span a range of difficulty, with posterior target dimension 1-10^4, condition number 1-10^8, and a range of variational families. Our results show that no single method dominates, but running a selection of 5 algorithms suffices to reliably get close to the best-possible observed performance. We thus provide a strong baseline for applications where expert tuning is not possible and for comparison when developing new stochastic optimization algorithms.
Large-scale Uncertainty Quantification for Latent Variable Models Using Subsampling Markov Chain Monte Carlo
May 29, 2026Stochastic gradient Langevin dynamics combined with Gibbs updates (SGLD--Gibbs) provides a highly scalable approach to approximate Bayesian inference in latent variable models. However, it remains unclear how to tune the algorithm's hyperparameters in a principled manner to ensure the uncertainty estimates are statistically meaningful. In this work, we address this gap in tuning guidance by developing a statistical scaling limit theory for SGLD--Gibbs. We derive a joint asymptotic limit for the global parameters and latent variables under appropriate space-time rescaling. We show that global parameters converge to a diffusion-type limit, while each latent variable converges to a jump process, reflecting the use of intermittent Gibbs updates. This joint jump-diffusion structure reveals how latent-variable randomness contributes to the stationary distribution of the global parameters. We leverage our results to propose explicit guidance on hyperparameter tuning for SGLD--Gibbs that ensures meaningful uncertainty quantification. Numerical experiments show that SGLD--Gibbs with our tuning guidance leads to better parameter estimates, uncertainty quantification, and predictive performance than stochastic variational inference.
Accurate Large-sample Uncertainty Quantification using Stochastic Gradient Markov Chain Monte Carlo
May 29, 2026Tuning algorithms such as stochastic gradient descent (SGD) and stochastic gradient Langevin dynamics (SGLD) for approximate sampling and uncertainty quantification remains challenging, particularly in the practically relevant settings when the batch size is large or the model is misspecified. Existing theory that provides tuning guidance relies on continuous-time limits or strong statistical assumptions, which can become quantitatively inaccurate in these regimes. We address these shortcomings by proposing new discrete-time approximations to SG(L)D with and without momentum, which enables accurate predictions of the stationary covariance, iterate average covariance, and integrated autocorrelation time. Moreover, we prove quantitative, non-asymptotic error bounds showing that these estimates are sufficiently accurate for practical tuning and uncertainty quantification. Numerical experiments demonstrate that our theory yields improved tuning guidance across a range of models and data-generating distributions where existing approaches fail, including when using the $β$-divergence rather than log-loss to obtain statistically robust inferences.
Quantitative Error Bounds for Scaling Limits of Stochastic Iterative Algorithms
Jan 21, 2025Stochastic iterative algorithms, including stochastic gradient descent (SGD) and stochastic gradient Langevin dynamics (SGLD), are widely utilized for optimization and sampling in large-scale and high-dimensional problems in machine learning, statistics, and engineering. Numerous works have bounded the parameter error in, and characterized the uncertainty of, these approximations. One common approach has been to use scaling limit analyses to relate the distribution of algorithm sample paths to a continuous-time stochastic process approximation, particularly in asymptotic setups. Focusing on the univariate setting, in this paper, we build on previous work to derive non-asymptotic functional approximation error bounds between the algorithm sample paths and the Ornstein-Uhlenbeck approximation using an infinite-dimensional version of Stein's method of exchangeable pairs. We show that this bound implies weak convergence under modest additional assumptions and leads to a bound on the error of the variance of the iterate averages of the algorithm. Furthermore, we use our main result to construct error bounds in terms of two common metrics: the L\'{e}vy-Prokhorov and bounded Wasserstein distances. Our results provide a foundation for developing similar error bounds for the multivariate setting and for more sophisticated stochastic approximation algorithms.
Tuning-free coreset Markov chain Monte Carlo
Oct 24, 2024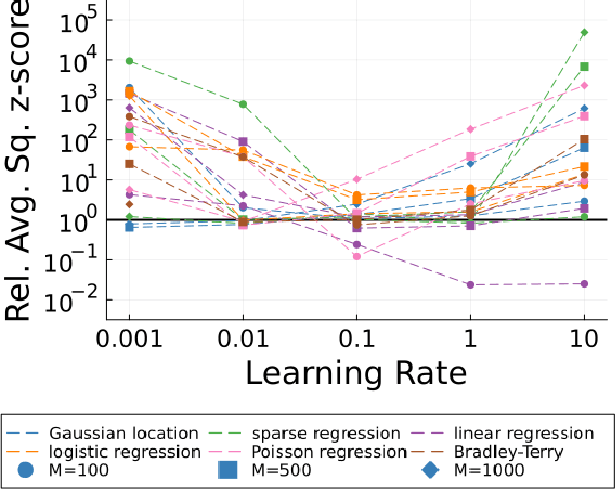


A Bayesian coreset is a small, weighted subset of a data set that replaces the full data during inference to reduce computational cost. The state-of-the-art coreset construction algorithm, Coreset Markov chain Monte Carlo (Coreset MCMC), uses draws from an adaptive Markov chain targeting the coreset posterior to train the coreset weights via stochastic gradient optimization. However, the quality of the constructed coreset, and thus the quality of its posterior approximation, is sensitive to the stochastic optimization learning rate. In this work, we propose a learning-rate-free stochastic gradient optimization procedure, Hot-start Distance over Gradient (Hot DoG), for training coreset weights in Coreset MCMC without user tuning effort. Empirical results demonstrate that Hot DoG provides higher quality posterior approximations than other learning-rate-free stochastic gradient methods, and performs competitively to optimally-tuned ADAM.
Reproducible Parameter Inference Using Bagged Posteriors
Nov 03, 2023Under model misspecification, it is known that Bayesian posteriors often do not properly quantify uncertainty about true or pseudo-true parameters. Even more fundamentally, misspecification leads to a lack of reproducibility in the sense that the same model will yield contradictory posteriors on independent data sets from the true distribution. To define a criterion for reproducible uncertainty quantification under misspecification, we consider the probability that two confidence sets constructed from independent data sets have nonempty overlap, and we establish a lower bound on this overlap probability that holds for any valid confidence sets. We prove that credible sets from the standard posterior can strongly violate this bound, particularly in high-dimensional settings (i.e., with dimension increasing with sample size), indicating that it is not internally coherent under misspecification. To improve reproducibility in an easy-to-use and widely applicable way, we propose to apply bagging to the Bayesian posterior ("BayesBag"'); that is, to use the average of posterior distributions conditioned on bootstrapped datasets. We motivate BayesBag from first principles based on Jeffrey conditionalization and show that the bagged posterior typically satisfies the overlap lower bound. Further, we prove a Bernstein--Von Mises theorem for the bagged posterior, establishing its asymptotic normal distribution. We demonstrate the benefits of BayesBag via simulation experiments and an application to crime rate prediction.
A Targeted Accuracy Diagnostic for Variational Approximations
Feb 24, 2023



Variational Inference (VI) is an attractive alternative to Markov Chain Monte Carlo (MCMC) due to its computational efficiency in the case of large datasets and/or complex models with high-dimensional parameters. However, evaluating the accuracy of variational approximations remains a challenge. Existing methods characterize the quality of the whole variational distribution, which is almost always poor in realistic applications, even if specific posterior functionals such as the component-wise means or variances are accurate. Hence, these diagnostics are of practical value only in limited circumstances. To address this issue, we propose the TArgeted Diagnostic for Distribution Approximation Accuracy (TADDAA), which uses many short parallel MCMC chains to obtain lower bounds on the error of each posterior functional of interest. We also develop a reliability check for TADDAA to determine when the lower bounds should not be trusted. Numerical experiments validate the practical utility and computational efficiency of our approach on a range of synthetic distributions and real-data examples, including sparse logistic regression and Bayesian neural network models.
* Code to reproduce all of our experiments is available at https://github.com/TARPS-group/TADDAA
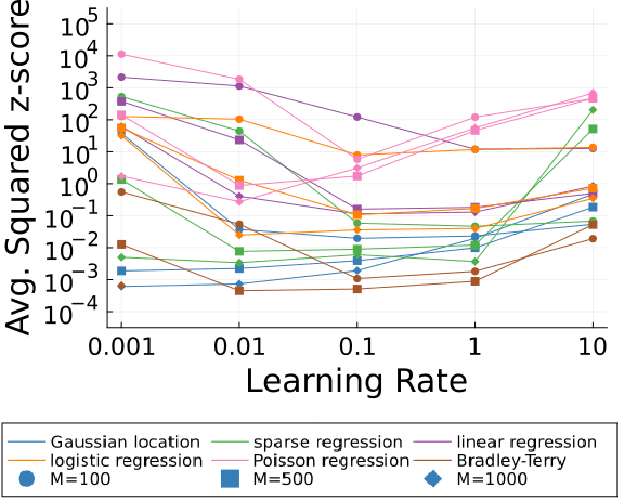
Statistical Inference with Stochastic Gradient Algorithms
Jul 25, 2022
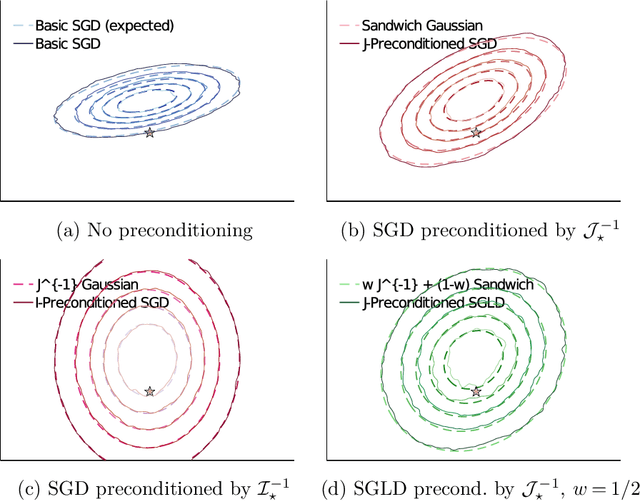
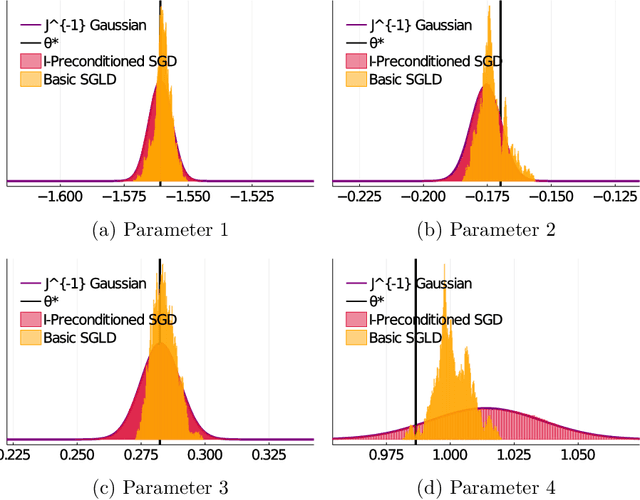
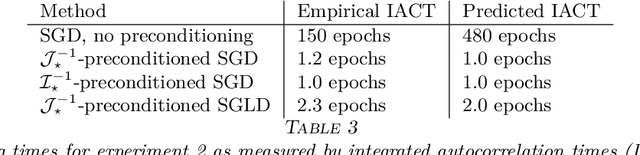
Stochastic gradient algorithms are widely used for both optimization and sampling in large-scale learning and inference problems. However, in practice, tuning these algorithms is typically done using heuristics and trial-and-error rather than rigorous, generalizable theory. To address this gap between theory and practice, we novel insights into the effect of tuning parameters by characterizing the large-sample behavior of iterates of a very general class of preconditioned stochastic gradient algorithms with fixed step size. In the optimization setting, our results show that iterate averaging with a large fixed step size can result in statistically efficient approximation of the (local) M-estimator. In the sampling context, our results show that with appropriate choices of tuning parameters, the limiting stationary covariance can match either the Bernstein--von Mises limit of the posterior, adjustments to the posterior for model misspecification, or the asymptotic distribution of the MLE; and that with a naive tuning the limit corresponds to none of these. Moreover, we argue that an essentially independent sample from the stationary distribution can be obtained after a fixed number of passes over the dataset. We validate our asymptotic results in realistic finite-sample regimes via several experiments using simulated and real data. Overall, we demonstrate that properly tuned stochastic gradient algorithms with constant step size offer a computationally efficient and statistically robust approach to obtaining point estimates or posterior-like samples.
Robust, Automated, and Accurate Black-box Variational Inference
Mar 29, 2022
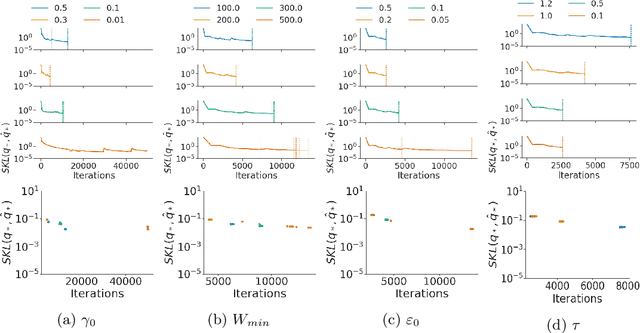
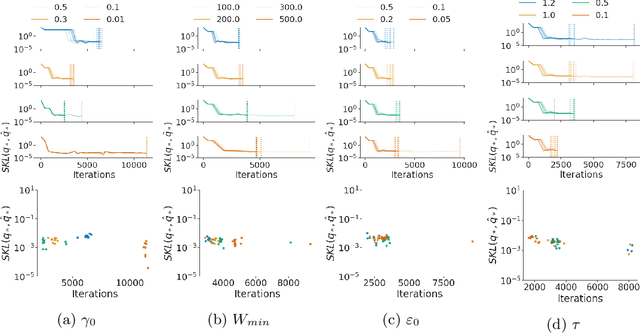
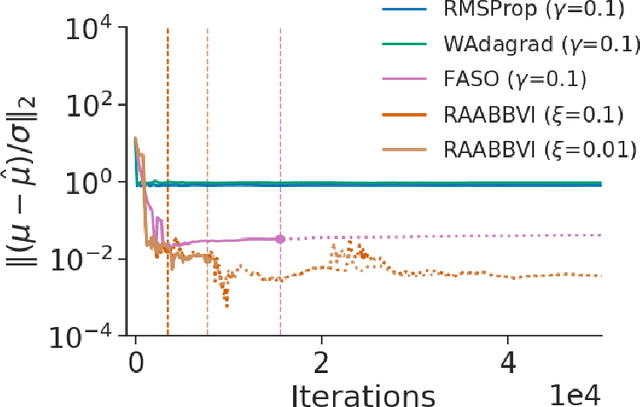
Black-box variational inference (BBVI) now sees widespread use in machine learning and statistics as a fast yet flexible alternative to Markov chain Monte Carlo methods for approximate Bayesian inference. However, stochastic optimization methods for BBVI remain unreliable and require substantial expertise and hand-tuning to apply effectively. In this paper, we propose Robust, Automated, and Accurate BBVI (RAABBVI), a framework for reliable BBVI optimization. RAABBVI is based on rigorously justified automation techniques, includes just a small number of intuitive tuning parameters, and detects inaccurate estimates of the optimal variational approximation. RAABBVI adaptively decreases the learning rate by detecting convergence of the fixed--learning-rate iterates, then estimates the symmetrized Kullback--Leiber (KL) divergence between the current variational approximation and the optimal one. It also employs a novel optimization termination criterion that enables the user to balance desired accuracy against computational cost by comparing (i) the predicted relative decrease in the symmetrized KL divergence if a smaller learning were used and (ii) the predicted computation required to converge with the smaller learning rate. We validate the robustness and accuracy of RAABBVI through carefully designed simulation studies and on a diverse set of real-world model and data examples.
Robust, Accurate Stochastic Optimization for Variational Inference
Sep 03, 2020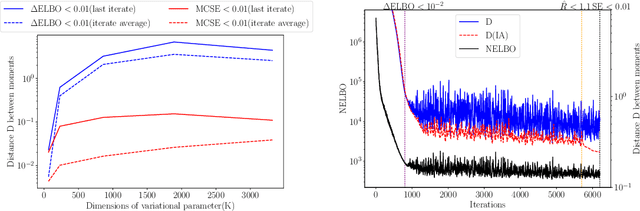
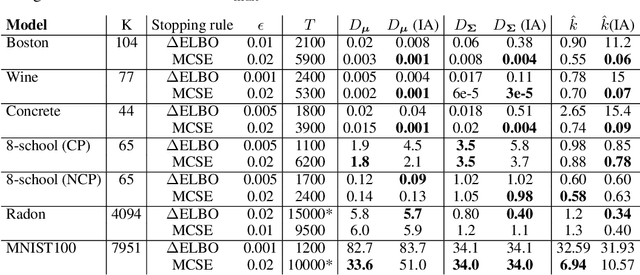
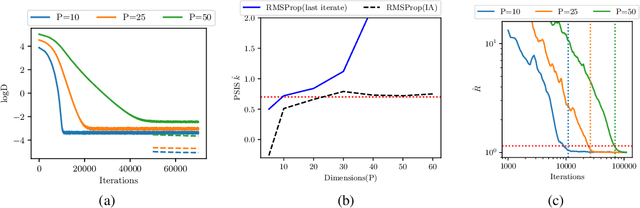
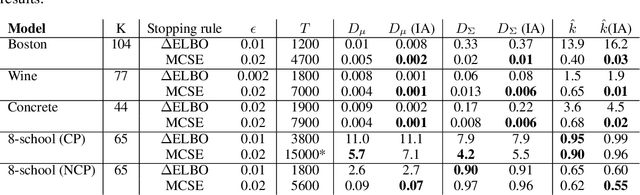
We consider the problem of fitting variational posterior approximations using stochastic optimization methods. The performance of these approximations depends on (1) how well the variational family matches the true posterior distribution,(2) the choice of divergence, and (3) the optimization of the variational objective. We show that even in the best-case scenario when the exact posterior belongs to the assumed variational family, common stochastic optimization methods lead to poor variational approximations if the problem dimension is moderately large. We also demonstrate that these methods are not robust across diverse model types. Motivated by these findings, we develop a more robust and accurate stochastic optimization framework by viewing the underlying optimization algorithm as producing a Markov chain. Our approach is theoretically motivated and includes a diagnostic for convergence and a novel stopping rule, both of which are robust to noisy evaluations of the objective function. We show empirically that the proposed framework works well on a diverse set of models: it can automatically detect stochastic optimization failure or inaccurate variational approximation