 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust, Automated, and Accurate Black-box Variational Inference
Mar 29, 2022
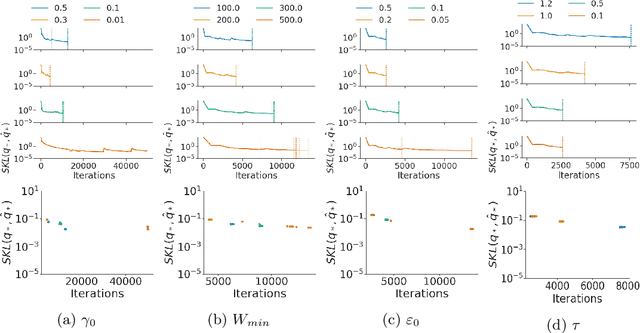
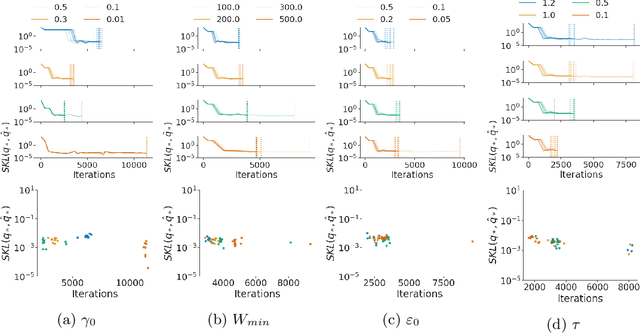
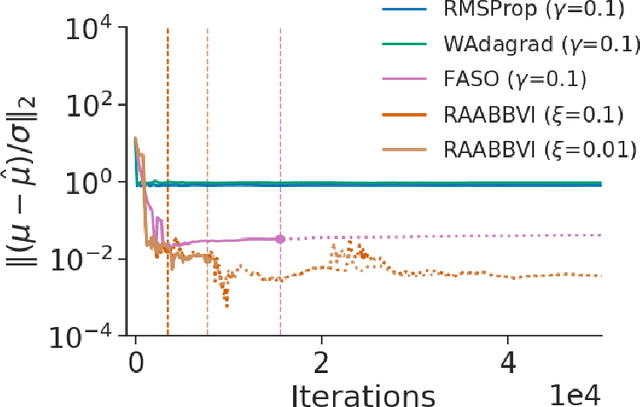
Black-box variational inference (BBVI) now sees widespread use in machine learning and statistics as a fast yet flexible alternative to Markov chain Monte Carlo methods for approximate Bayesian inference. However, stochastic optimization methods for BBVI remain unreliable and require substantial expertise and hand-tuning to apply effectively. In this paper, we propose Robust, Automated, and Accurate BBVI (RAABBVI), a framework for reliable BBVI optimization. RAABBVI is based on rigorously justified automation techniques, includes just a small number of intuitive tuning parameters, and detects inaccurate estimates of the optimal variational approximation. RAABBVI adaptively decreases the learning rate by detecting convergence of the fixed--learning-rate iterates, then estimates the symmetrized Kullback--Leiber (KL) divergence between the current variational approximation and the optimal one. It also employs a novel optimization termination criterion that enables the user to balance desired accuracy against computational cost by comparing (i) the predicted relative decrease in the symmetrized KL divergence if a smaller learning were used and (ii) the predicted computation required to converge with the smaller learning rate. We validate the robustness and accuracy of RAABBVI through carefully designed simulation studies and on a diverse set of real-world model and data examples.
Challenges and Opportunities in High-dimensional Variational Inference
Mar 01, 2021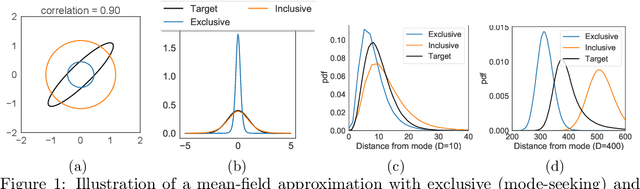
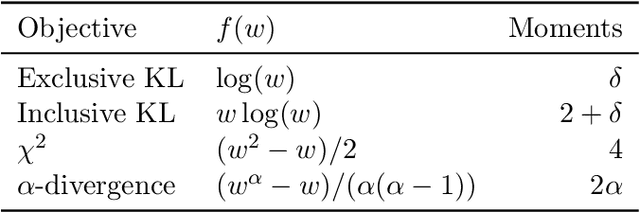
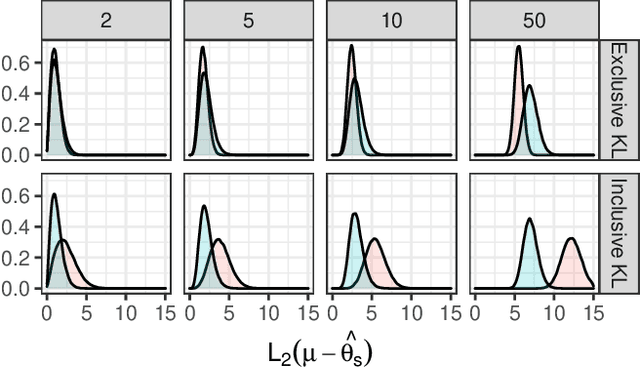
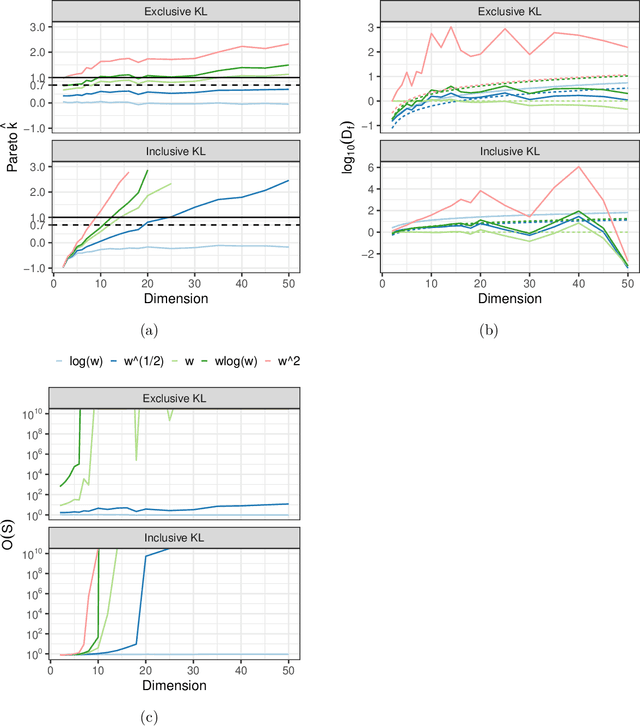
We explore the limitations of and best practices for using black-box variational inference to estimate posterior summaries of the model parameters. By taking an importance sampling perspective, we are able to explain and empirically demonstrate: 1) why the intuitions about the behavior of approximate families and divergences for low-dimensional posteriors fail for higher-dimensional posteriors, 2) how we can diagnose the pre-asymptotic reliability of variational inference in practice by examining the behavior of the density ratios (i.e., importance weights), 3) why the choice of variational objective is not as relevant for higher-dimensional posteriors, and 4) why, although flexible variational families can provide some benefits in higher dimensions, they also introduce additional optimization challenges. Based on these findings, for high-dimensional posteriors we recommend using the exclusive KL divergence that is most stable and easiest to optimize, and then focusing on improving the variational family or using model parameter transformations to make the posterior more similar to the approximating family. Our results also show that in low to moderate dimensions, heavy-tailed variational families and mass-covering divergences can increase the chances that the approximation can be improved by importance sampling.