 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChallenges and Opportunities in High-dimensional Variational Inference
Mar 01, 2021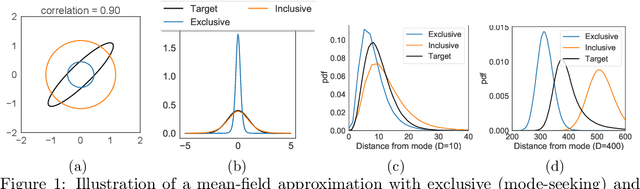
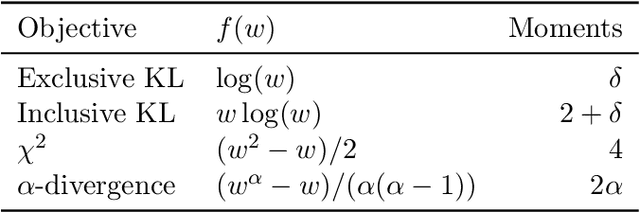
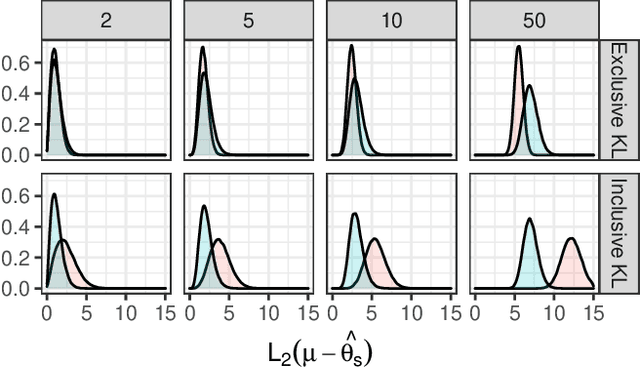
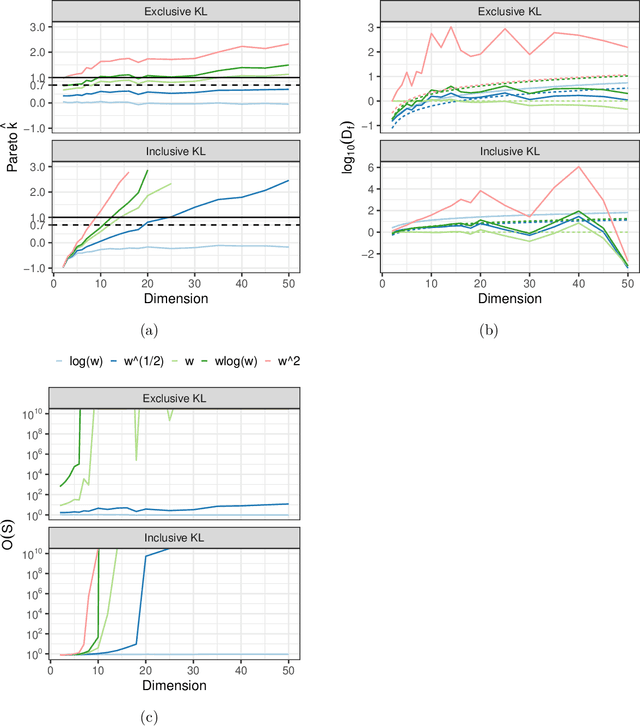
We explore the limitations of and best practices for using black-box variational inference to estimate posterior summaries of the model parameters. By taking an importance sampling perspective, we are able to explain and empirically demonstrate: 1) why the intuitions about the behavior of approximate families and divergences for low-dimensional posteriors fail for higher-dimensional posteriors, 2) how we can diagnose the pre-asymptotic reliability of variational inference in practice by examining the behavior of the density ratios (i.e., importance weights), 3) why the choice of variational objective is not as relevant for higher-dimensional posteriors, and 4) why, although flexible variational families can provide some benefits in higher dimensions, they also introduce additional optimization challenges. Based on these findings, for high-dimensional posteriors we recommend using the exclusive KL divergence that is most stable and easiest to optimize, and then focusing on improving the variational family or using model parameter transformations to make the posterior more similar to the approximating family. Our results also show that in low to moderate dimensions, heavy-tailed variational families and mass-covering divergences can increase the chances that the approximation can be improved by importance sampling.
Robust, Accurate Stochastic Optimization for Variational Inference
Sep 03, 2020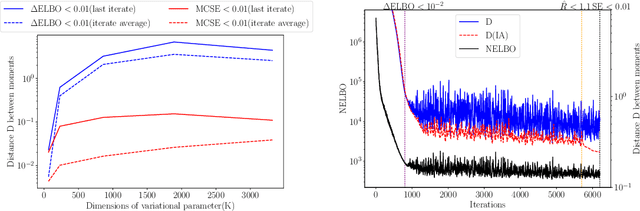
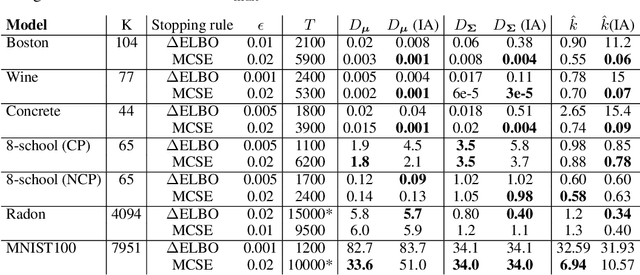
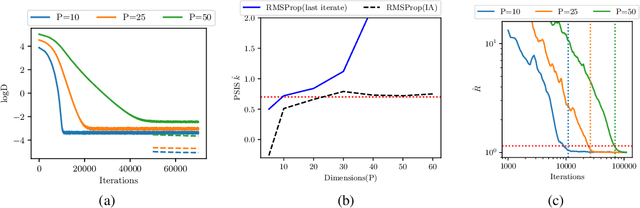
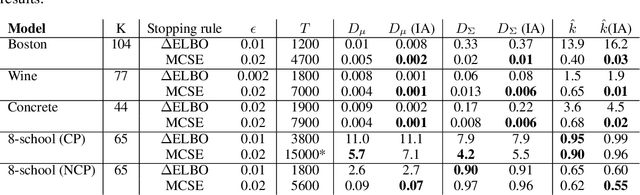
We consider the problem of fitting variational posterior approximations using stochastic optimization methods. The performance of these approximations depends on (1) how well the variational family matches the true posterior distribution,(2) the choice of divergence, and (3) the optimization of the variational objective. We show that even in the best-case scenario when the exact posterior belongs to the assumed variational family, common stochastic optimization methods lead to poor variational approximations if the problem dimension is moderately large. We also demonstrate that these methods are not robust across diverse model types. Motivated by these findings, we develop a more robust and accurate stochastic optimization framework by viewing the underlying optimization algorithm as producing a Markov chain. Our approach is theoretically motivated and includes a diagnostic for convergence and a novel stopping rule, both of which are robust to noisy evaluations of the objective function. We show empirically that the proposed framework works well on a diverse set of models: it can automatically detect stochastic optimization failure or inaccurate variational approximation
Preferential Batch Bayesian Optimization
Mar 25, 2020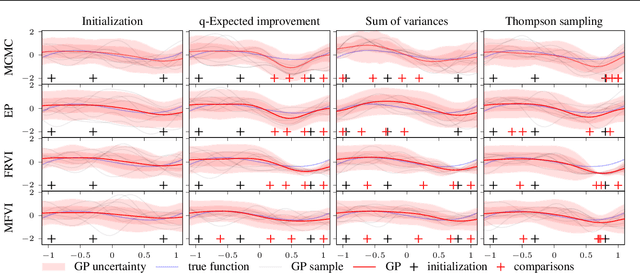
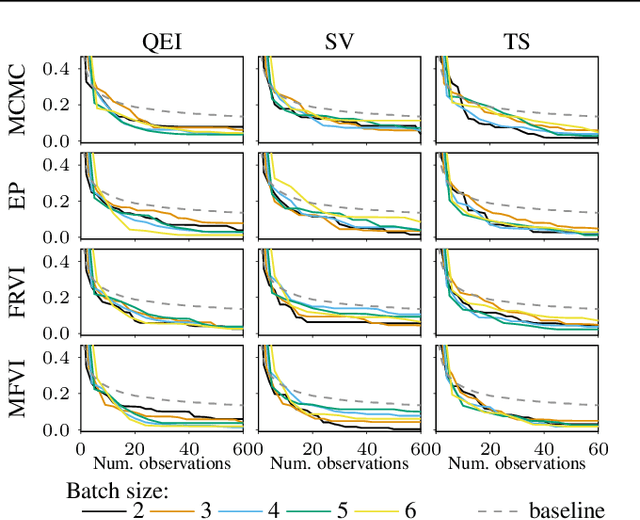
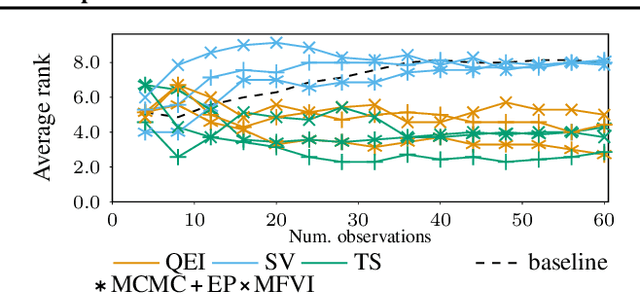
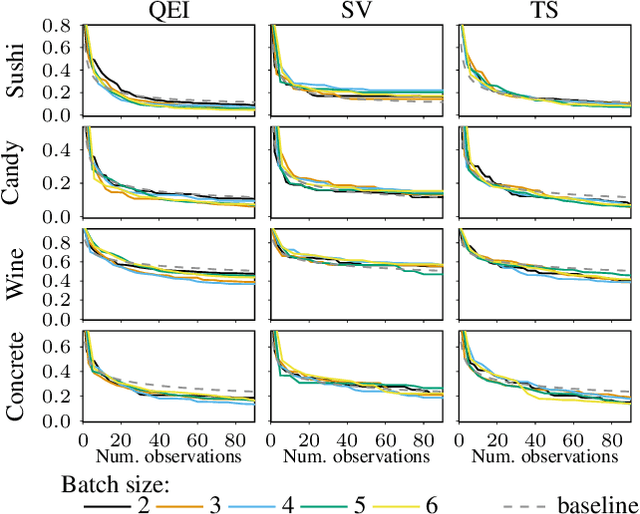
Most research in Bayesian optimization (BO) has focused on direct feedback scenarios, where one has access to exact, or perturbed, values of some expensive-to-evaluate objective. This direction has been mainly driven by the use of BO in machine learning hyper-parameter configuration problems. However, in domains such as modelling human preferences, A/B tests or recommender systems, there is a need of methods that are able to replace direct feedback with preferential feedback, obtained via rankings or pairwise comparisons. In this work, we present Preferential Batch Bayesian Optimization (PBBO), a new framework that allows to find the optimum of a latent function of interest, given any type of parallel preferential feedback for a group of two or more points. We do so by using a Gaussian process model with a likelihood specially designed to enable parallel and efficient data collection mechanisms, which are key in modern machine learning. We show how the acquisitions developed under this framework generalize and augment previous approaches in Bayesian optimization, expanding the use of these techniques to a wider range of domains. An extensive simulation study shows the benefits of this approach, both with simulated functions and four real data sets.
Semi-supervised Learning with Sparse Autoencoders in Phone Classification
Oct 03, 2016



We propose the application of a semi-supervised learning method to improve the performance of acoustic modelling for automatic speech recognition based on deep neural net- works. As opposed to unsupervised initialisation followed by supervised fine tuning, our method takes advantage of both unlabelled and labelled data simultaneously through mini- batch stochastic gradient descent. We tested the method with varying proportions of labelled vs unlabelled observations in frame-based phoneme classification on the TIMIT database. Our experiments show that the method outperforms standard supervised training for an equal amount of labelled data and provides competitive error rates compared to state-of-the-art graph-based semi-supervised learning techniques.
Optimising The Input Window Alignment in CD-DNN Based Phoneme Recognition for Low Latency Processing
Jun 29, 2016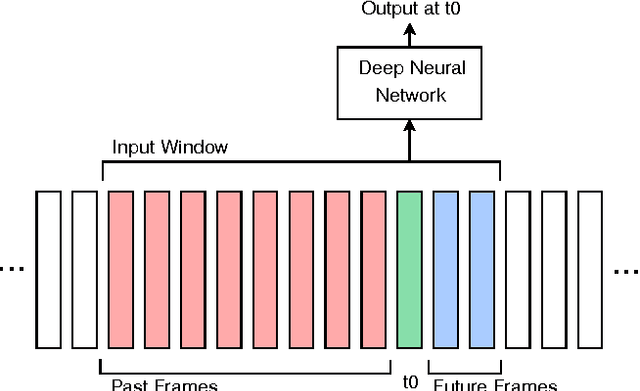



We present a systematic analysis on the performance of a phonetic recogniser when the window of input features is not symmetric with respect to the current frame. The recogniser is based on Context Dependent Deep Neural Networks (CD-DNNs) and Hidden Markov Models (HMMs). The objective is to reduce the latency of the system by reducing the number of future feature frames required to estimate the current output. Our tests performed on the TIMIT database show that the performance does not degrade when the input window is shifted up to 5 frames in the past compared to common practice (no future frame). This corresponds to improving the latency by 50 ms in our settings. Our tests also show that the best results are not obtained with the symmetric window commonly employed, but with an asymmetric window with eight past and two future context frames, although this observation should be confirmed on other data sets. The reduction in latency suggested by our results is critical for specific applications such as real-time lip synchronisation for tele-presence, but may also be beneficial in general applications to improve the lag in human-machine spoken interaction.