 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction-powered estimators for finite population statistics in highly imbalanced textual data: Public hate crime estimation
May 05, 2025Estimating population parameters in finite populations of text documents can be challenging when obtaining the labels for the target variable requires manual annotation. To address this problem, we combine predictions from a transformer encoder neural network with well-established survey sampling estimators using the model predictions as an auxiliary variable. The applicability is demonstrated in Swedish hate crime statistics based on Swedish police reports. Estimates of the yearly number of hate crimes and the police's under-reporting are derived using the Hansen-Hurwitz estimator, difference estimation, and stratified random sampling estimation. We conclude that if labeled training data is available, the proposed method can provide very efficient estimates with reduced time spent on manual annotation.
An Image is Worth $K$ Topics: A Visual Structural Topic Model with Pretrained Image Embeddings
Apr 14, 2025Political scientists are increasingly interested in analyzing visual content at scale. However, the existing computational toolbox is still in need of methods and models attuned to the specific challenges and goals of social and political inquiry. In this article, we introduce a visual Structural Topic Model (vSTM) that combines pretrained image embeddings with a structural topic model. This has important advantages compared to existing approaches. First, pretrained embeddings allow the model to capture the semantic complexity of images relevant to political contexts. Second, the structural topic model provides the ability to analyze how topics and covariates are related, while maintaining a nuanced representation of images as a mixture of multiple topics. In our empirical application, we show that the vSTM is able to identify topics that are interpretable, coherent, and substantively relevant to the study of online political communication.
The Cambridge Law Corpus: A Corpus for Legal AI Research
Sep 22, 2023



We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
Probabilistic Embeddings with Laplacian Graph Priors
Mar 25, 2022

We introduce probabilistic embeddings using Laplacian priors (PELP). The proposed model enables incorporating graph side-information into static word embeddings. We theoretically show that the model unifies several previously proposed embedding methods under one umbrella. PELP generalises graph-enhanced, group, dynamic, and cross-lingual static word embeddings. PELP also enables any combination of these previous models in a straightforward fashion. Furthermore, we empirically show that our model matches the performance of previous models as special cases. In addition, we demonstrate its flexibility by applying it to the comparison of political sociolects over time. Finally, we provide code as a TensorFlow implementation enabling flexible estimation in different settings.
Robust, Accurate Stochastic Optimization for Variational Inference
Sep 03, 2020
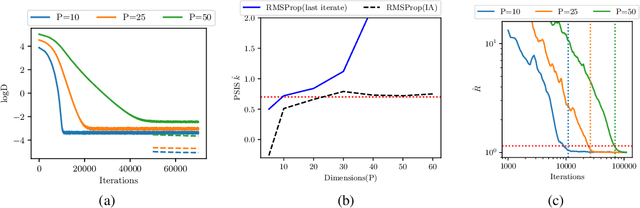
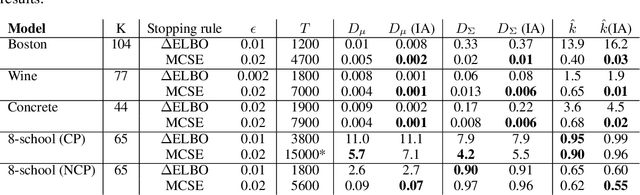
We consider the problem of fitting variational posterior approximations using stochastic optimization methods. The performance of these approximations depends on (1) how well the variational family matches the true posterior distribution,(2) the choice of divergence, and (3) the optimization of the variational objective. We show that even in the best-case scenario when the exact posterior belongs to the assumed variational family, common stochastic optimization methods lead to poor variational approximations if the problem dimension is moderately large. We also demonstrate that these methods are not robust across diverse model types. Motivated by these findings, we develop a more robust and accurate stochastic optimization framework by viewing the underlying optimization algorithm as producing a Markov chain. Our approach is theoretically motivated and includes a diagnostic for convergence and a novel stopping rule, both of which are robust to noisy evaluations of the objective function. We show empirically that the proposed framework works well on a diverse set of models: it can automatically detect stochastic optimization failure or inaccurate variational approximation
Interpretable Word Embeddings via Informative Priors
Sep 03, 2019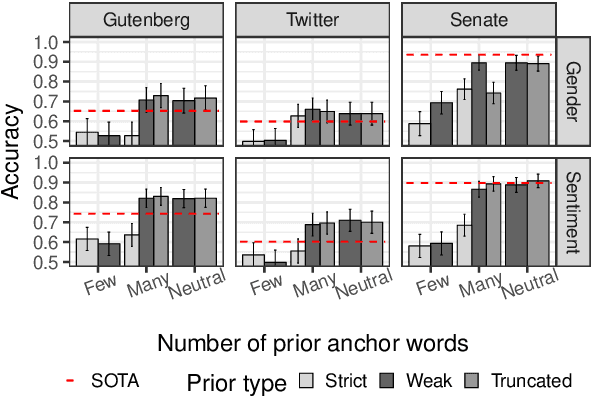
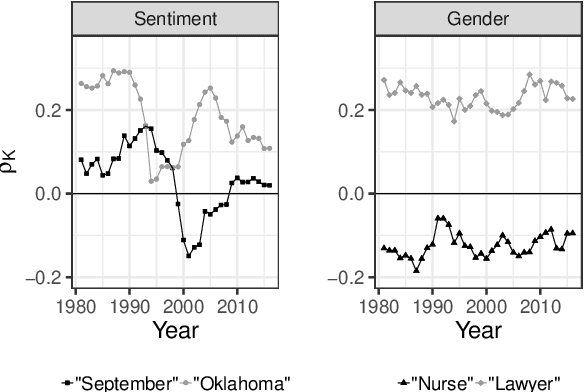
Word embeddings have demonstrated strong performance on NLP tasks. However, lack of interpretability and the unsupervised nature of word embeddings have limited their use within computational social science and digital humanities. We propose the use of informative priors to create interpretable and domain-informed dimensions for probabilistic word embeddings. Experimental results show that sensible priors can capture latent semantic concepts better than or on-par with the current state of the art, while retaining the simplicity and generalizability of using priors.
Sparse Parallel Training of Hierarchical Dirichlet Process Topic Models
Jun 06, 2019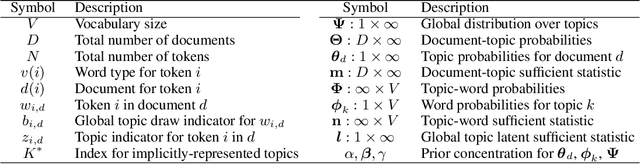
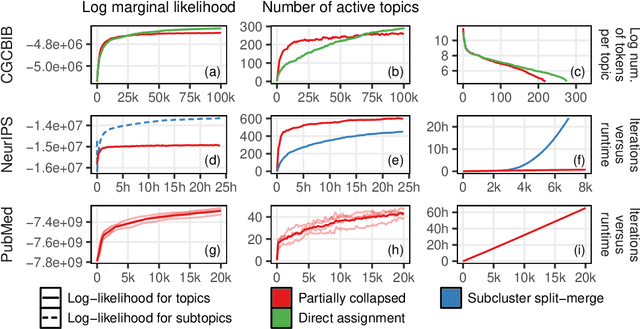

Nonparametric extensions of topic models such as Latent Dirichlet Allocation, including Hierarchical Dirichlet Process (HDP), are often studied in natural language processing. Training these models generally requires use of serial algorithms, which limits scalability to large data sets and complicates acceleration via use of parallel and distributed systems. Most current approaches to scalable training of such models either don't converge to the correct target, or are not data-parallel. Moreover, these approaches generally do not utilize all available sources of sparsity found in natural language - an important way to make computation efficient. Based upon a representation of certain conditional distributions within an HDP, we propose a doubly sparse data-parallel sampler for the HDP topic model that addresses these issues. We benchmark our method on a well-known corpora (PubMed) with 8m documents and 768m tokens, using a single multi-core machine in under three days.
Bayesian leave-one-out cross-validation for large data
Apr 24, 2019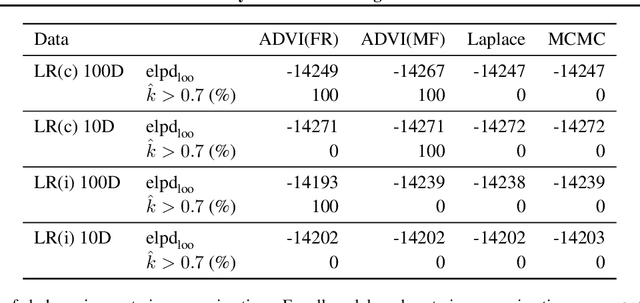
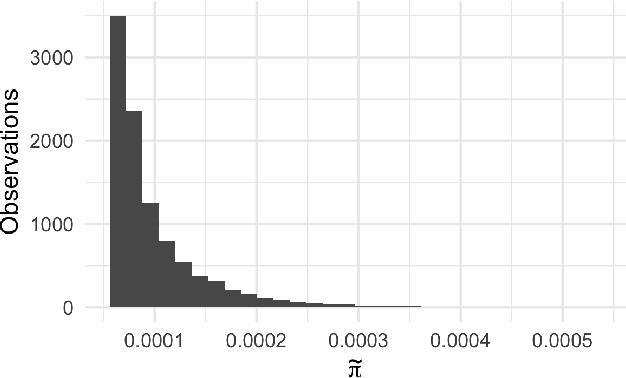
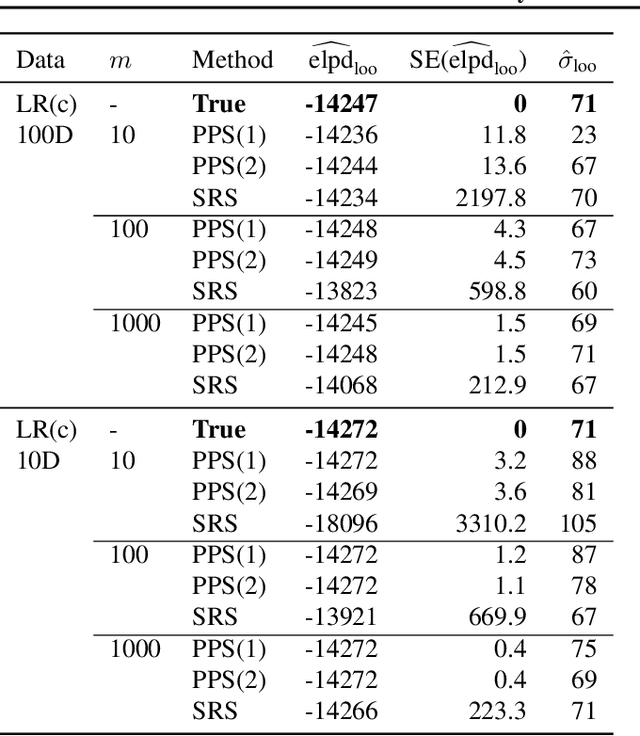
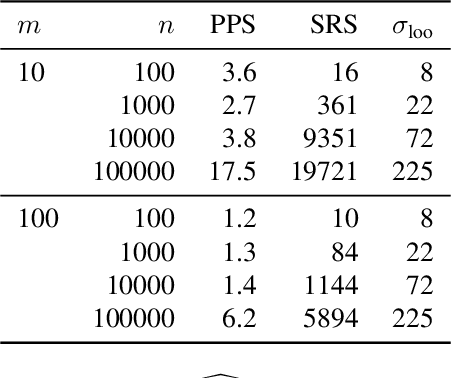
Model inference, such as model comparison, model checking, and model selection, is an important part of model development. Leave-one-out cross-validation (LOO) is a general approach for assessing the generalizability of a model, but unfortunately, LOO does not scale well to large datasets. We propose a combination of using approximate inference techniques and probability-proportional-to-size-sampling (PPS) for fast LOO model evaluation for large datasets. We provide both theoretical and empirical results showing good properties for large data.
Polya Urn Latent Dirichlet Allocation: a doubly sparse massively parallel sampler
Aug 03, 2018

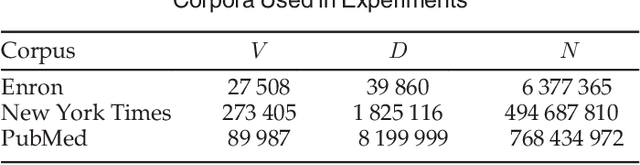

Latent Dirichlet Allocation (LDA) is a topic model widely used in natural language processing and machine learning. Most approaches to training the model rely on iterative algorithms, which makes it difficult to run LDA on big corpora that are best analyzed in parallel and distributed computational environments. Indeed, current approaches to parallel inference either don't converge to the correct posterior or require storage of large dense matrices in memory. We present a novel sampler that overcomes both problems, and we show that this sampler is faster, both empirically and theoretically, than previous Gibbs samplers for LDA. We do so by employing a novel P\'olya-urn-based approximation in the sparse partially collapsed sampler for LDA. We prove that the approximation error vanishes with data size, making our algorithm asymptotically exact, a property of importance for large-scale topic models. In addition, we show, via an explicit example, that -- contrary to popular belief in the topic modeling literature -- partially collapsed samplers can be more efficient than fully collapsed samplers. We conclude by comparing the performance of our algorithm with that of other approaches on well-known corpora.
Sparse Partially Collapsed MCMC for Parallel Inference in Topic Models
Aug 15, 2017
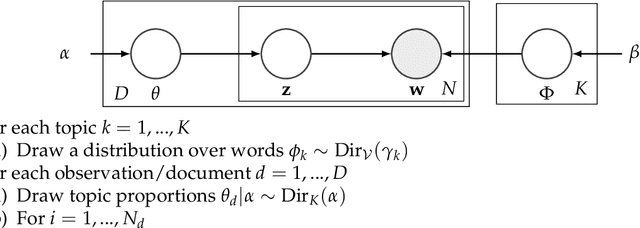
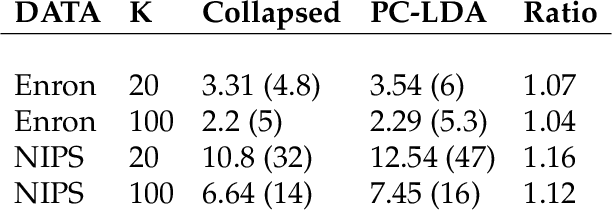
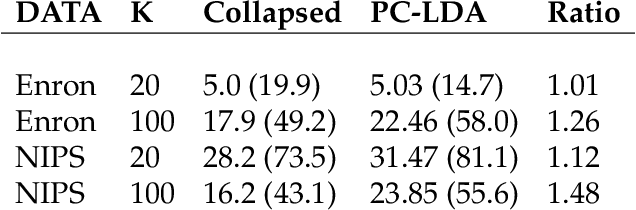
Topic models, and more specifically the class of Latent Dirichlet Allocation (LDA), are widely used for probabilistic modeling of text. MCMC sampling from the posterior distribution is typically performed using a collapsed Gibbs sampler. We propose a parallel sparse partially collapsed Gibbs sampler and compare its speed and efficiency to state-of-the-art samplers for topic models on five well-known text corpora of differing sizes and properties. In particular, we propose and compare two different strategies for sampling the parameter block with latent topic indicators. The experiments show that the increase in statistical inefficiency from only partial collapsing is smaller than commonly assumed, and can be more than compensated by the speedup from parallelization and sparsity on larger corpora. We also prove that the partially collapsed samplers scale well with the size of the corpus. The proposed algorithm is fast, efficient, exact, and can be used in more modeling situations than the ordinary collapsed sampler.