 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTelecom AI Native Systems in the Age of Generative AI -- An Engineering Perspective
Oct 18, 2023
The rapid advancements in Artificial Intelligence (AI), particularly in generative AI and foundational models (FMs), have ushered in transformative changes across various industries. Large language models (LLMs), a type of FM, have demonstrated their prowess in natural language processing tasks and content generation, revolutionizing how we interact with software products and services. This article explores the integration of FMs in the telecommunications industry, shedding light on the concept of AI native telco, where AI is seamlessly woven into the fabric of telecom products. It delves into the engineering considerations and unique challenges associated with implementing FMs into the software life cycle, emphasizing the need for AI native-first approaches. Despite the enormous potential of FMs, ethical, regulatory, and operational challenges require careful consideration, especially in mission-critical telecom contexts. As the telecom industry seeks to harness the power of AI, a comprehensive understanding of these challenges is vital to thrive in a fiercely competitive market.
The Cambridge Law Corpus: A Corpus for Legal AI Research
Sep 22, 2023



We introduce the Cambridge Law Corpus (CLC), a corpus for legal AI research. It consists of over 250 000 court cases from the UK. Most cases are from the 21st century, but the corpus includes cases as old as the 16th century. This paper presents the first release of the corpus, containing the raw text and meta-data. Together with the corpus, we provide annotations on case outcomes for 638 cases, done by legal experts. Using our annotated data, we have trained and evaluated case outcome extraction with GPT-3, GPT-4 and RoBERTa models to provide benchmarks. We include an extensive legal and ethical discussion to address the potentially sensitive nature of this material. As a consequence, the corpus will only be released for research purposes under certain restrictions.
Sparse Parallel Training of Hierarchical Dirichlet Process Topic Models
Jun 06, 2019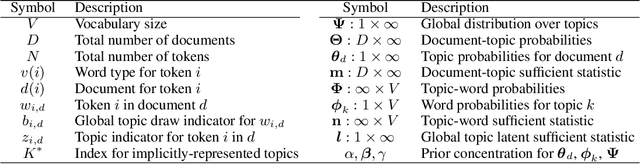
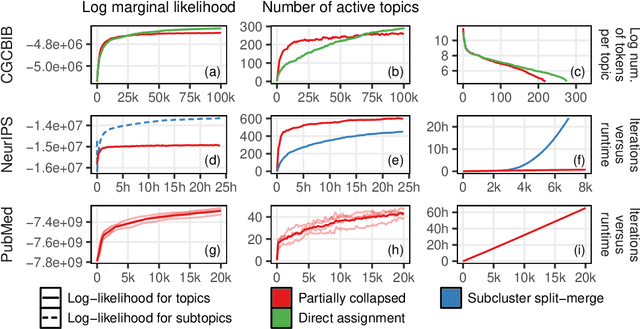

Nonparametric extensions of topic models such as Latent Dirichlet Allocation, including Hierarchical Dirichlet Process (HDP), are often studied in natural language processing. Training these models generally requires use of serial algorithms, which limits scalability to large data sets and complicates acceleration via use of parallel and distributed systems. Most current approaches to scalable training of such models either don't converge to the correct target, or are not data-parallel. Moreover, these approaches generally do not utilize all available sources of sparsity found in natural language - an important way to make computation efficient. Based upon a representation of certain conditional distributions within an HDP, we propose a doubly sparse data-parallel sampler for the HDP topic model that addresses these issues. We benchmark our method on a well-known corpora (PubMed) with 8m documents and 768m tokens, using a single multi-core machine in under three days.
Polya Urn Latent Dirichlet Allocation: a doubly sparse massively parallel sampler
Aug 03, 2018

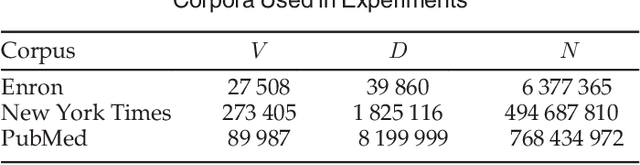

Latent Dirichlet Allocation (LDA) is a topic model widely used in natural language processing and machine learning. Most approaches to training the model rely on iterative algorithms, which makes it difficult to run LDA on big corpora that are best analyzed in parallel and distributed computational environments. Indeed, current approaches to parallel inference either don't converge to the correct posterior or require storage of large dense matrices in memory. We present a novel sampler that overcomes both problems, and we show that this sampler is faster, both empirically and theoretically, than previous Gibbs samplers for LDA. We do so by employing a novel P\'olya-urn-based approximation in the sparse partially collapsed sampler for LDA. We prove that the approximation error vanishes with data size, making our algorithm asymptotically exact, a property of importance for large-scale topic models. In addition, we show, via an explicit example, that -- contrary to popular belief in the topic modeling literature -- partially collapsed samplers can be more efficient than fully collapsed samplers. We conclude by comparing the performance of our algorithm with that of other approaches on well-known corpora.
Sparse Partially Collapsed MCMC for Parallel Inference in Topic Models
Aug 15, 2017
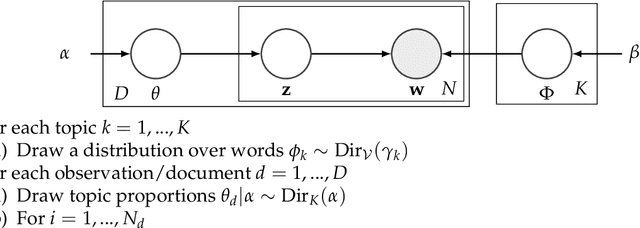
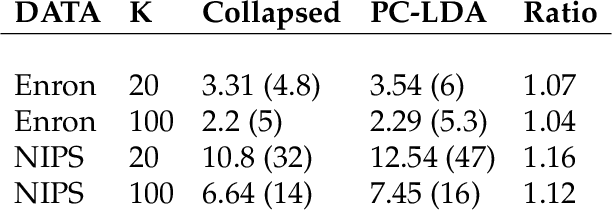
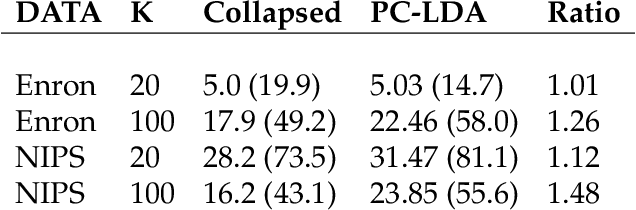
Topic models, and more specifically the class of Latent Dirichlet Allocation (LDA), are widely used for probabilistic modeling of text. MCMC sampling from the posterior distribution is typically performed using a collapsed Gibbs sampler. We propose a parallel sparse partially collapsed Gibbs sampler and compare its speed and efficiency to state-of-the-art samplers for topic models on five well-known text corpora of differing sizes and properties. In particular, we propose and compare two different strategies for sampling the parameter block with latent topic indicators. The experiments show that the increase in statistical inefficiency from only partial collapsing is smaller than commonly assumed, and can be more than compensated by the speedup from parallelization and sparsity on larger corpora. We also prove that the partially collapsed samplers scale well with the size of the corpus. The proposed algorithm is fast, efficient, exact, and can be used in more modeling situations than the ordinary collapsed sampler.
DOLDA - a regularized supervised topic model for high-dimensional multi-class regression
Oct 20, 2016

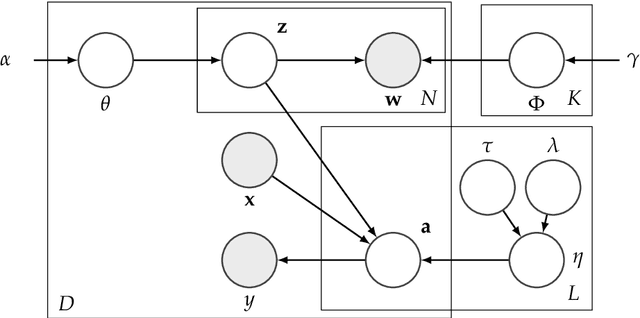

Generating user interpretable multi-class predictions in data rich environments with many classes and explanatory covariates is a daunting task. We introduce Diagonal Orthant Latent Dirichlet Allocation (DOLDA), a supervised topic model for multi-class classification that can handle both many classes as well as many covariates. To handle many classes we use the recently proposed Diagonal Orthant (DO) probit model (Johndrow et al., 2013) together with an efficient Horseshoe prior for variable selection/shrinkage (Carvalho et al., 2010). We propose a computationally efficient parallel Gibbs sampler for the new model. An important advantage of DOLDA is that learned topics are directly connected to individual classes without the need for a reference class. We evaluate the model's predictive accuracy on two datasets and demonstrate DOLDA's advantage in interpreting the generated predictions.