 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatic Program Analysis Guided LLM Based Unit Test Generation
Mar 07, 2025



We describe a novel approach to automating unit test generation for Java methods using large language models (LLMs). Existing LLM-based approaches rely on sample usage(s) of the method to test (focal method) and/or provide the entire class of the focal method as input prompt and context. The former approach is often not viable due to the lack of sample usages, especially for newly written focal methods. The latter approach does not scale well enough; the bigger the complexity of the focal method and larger associated class, the harder it is to produce adequate test code (due to factors such as exceeding the prompt and context lengths of the underlying LLM). We show that augmenting prompts with \emph{concise} and \emph{precise} context information obtained by program analysis %of the focal method increases the effectiveness of generating unit test code through LLMs. We validate our approach on a large commercial Java project and a popular open-source Java project.
Icing on the Cake: Automatic Code Summarization at Ericsson
Aug 19, 2024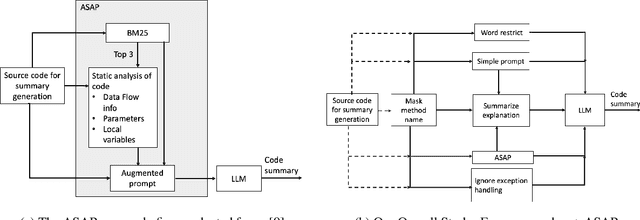
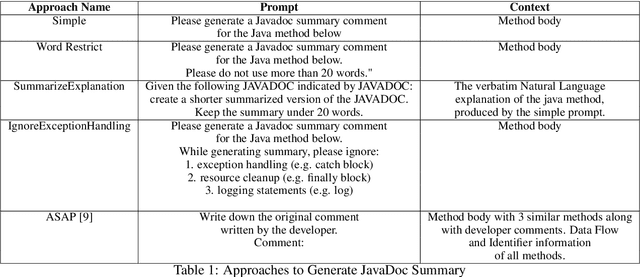
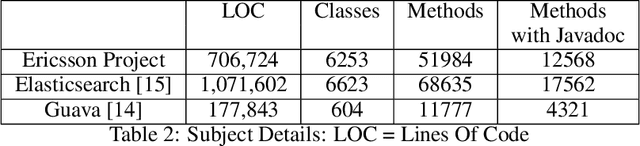
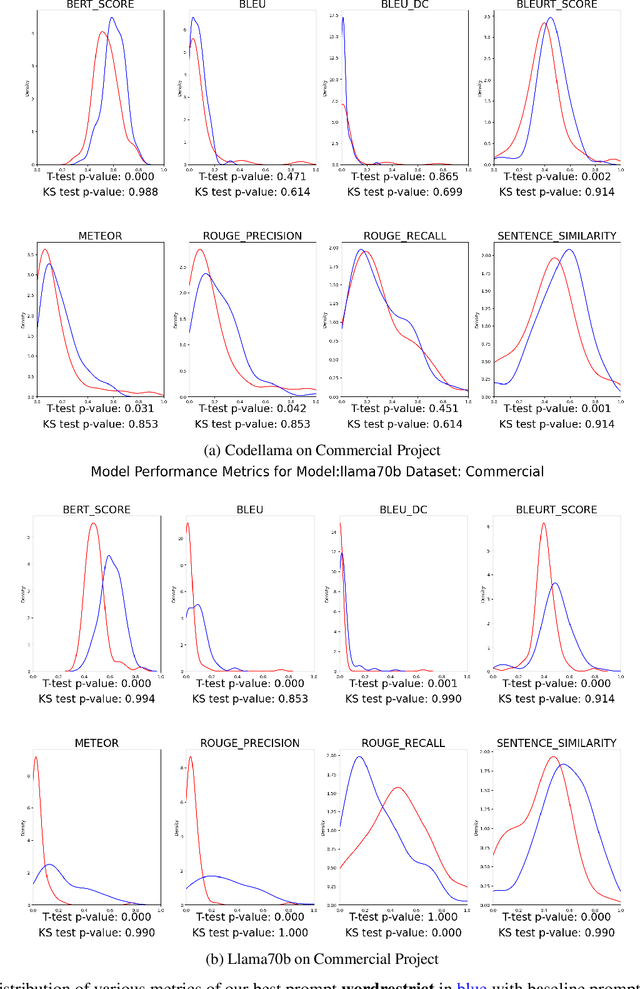
This paper presents our findings on the automatic summarization of Java methods within Ericsson, a global telecommunications company. We evaluate the performance of an approach called Automatic Semantic Augmentation of Prompts (ASAP), which uses a Large Language Model (LLM) to generate leading summary comments for Java methods. ASAP enhances the $LLM's$ prompt context by integrating static program analysis and information retrieval techniques to identify similar exemplar methods along with their developer-written Javadocs, and serves as the baseline in our study. In contrast, we explore and compare the performance of four simpler approaches that do not require static program analysis, information retrieval, or the presence of exemplars as in the ASAP method. Our methods rely solely on the Java method body as input, making them lightweight and more suitable for rapid deployment in commercial software development environments. We conducted experiments on an Ericsson software project and replicated the study using two widely-used open-source Java projects, Guava and Elasticsearch, to ensure the reliability of our results. Performance was measured across eight metrics that capture various aspects of similarity. Notably, one of our simpler approaches performed as well as or better than the ASAP method on both the Ericsson project and the open-source projects. Additionally, we performed an ablation study to examine the impact of method names on Javadoc summary generation across our four proposed approaches and the ASAP method. By masking the method names and observing the generated summaries, we found that our approaches were statistically significantly less influenced by the absence of method names compared to the baseline. This suggests that our methods are more robust to variations in method names and may derive summaries more comprehensively from the method body than the ASAP approach.
Telecom AI Native Systems in the Age of Generative AI -- An Engineering Perspective
Oct 18, 2023The rapid advancements in Artificial Intelligence (AI), particularly in generative AI and foundational models (FMs), have ushered in transformative changes across various industries. Large language models (LLMs), a type of FM, have demonstrated their prowess in natural language processing tasks and content generation, revolutionizing how we interact with software products and services. This article explores the integration of FMs in the telecommunications industry, shedding light on the concept of AI native telco, where AI is seamlessly woven into the fabric of telecom products. It delves into the engineering considerations and unique challenges associated with implementing FMs into the software life cycle, emphasizing the need for AI native-first approaches. Despite the enormous potential of FMs, ethical, regulatory, and operational challenges require careful consideration, especially in mission-critical telecom contexts. As the telecom industry seeks to harness the power of AI, a comprehensive understanding of these challenges is vital to thrive in a fiercely competitive market.
Tag that issue: Applying API-domain labels in issue tracking systems
Apr 06, 2023Labeling issues with the skills required to complete them can help contributors to choose tasks in Open Source Software projects. However, manually labeling issues is time-consuming and error-prone, and current automated approaches are mostly limited to classifying issues as bugs/non-bugs. We investigate the feasibility and relevance of automatically labeling issues with what we call "API-domains," which are high-level categories of APIs. Therefore, we posit that the APIs used in the source code affected by an issue can be a proxy for the type of skills (e.g., DB, security, UI) needed to work on the issue. We ran a user study (n=74) to assess API-domain labels' relevancy to potential contributors, leveraged the issues' descriptions and the project history to build prediction models, and validated the predictions with contributors (n=20) of the projects. Our results show that (i) newcomers to the project consider API-domain labels useful in choosing tasks, (ii) labels can be predicted with a precision of 84% and a recall of 78.6% on average, (iii) the results of the predictions reached up to 71.3% in precision and 52.5% in recall when training with a project and testing in another (transfer learning), and (iv) project contributors consider most of the predictions helpful in identifying needed skills. These findings suggest our approach can be applied in practice to automatically label issues, assisting developers in finding tasks that better match their skills.
Using Machine Intelligence to Prioritise Code Review Requests
Feb 11, 2021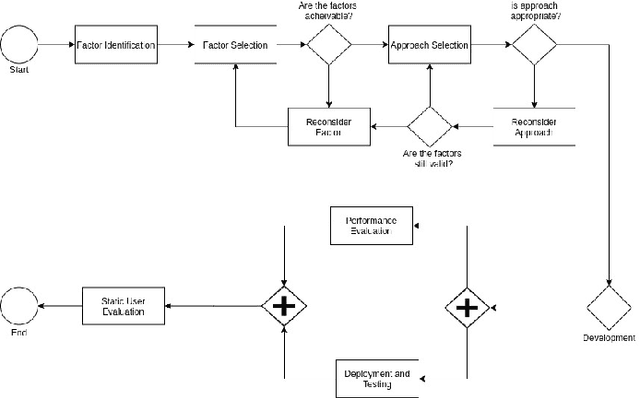
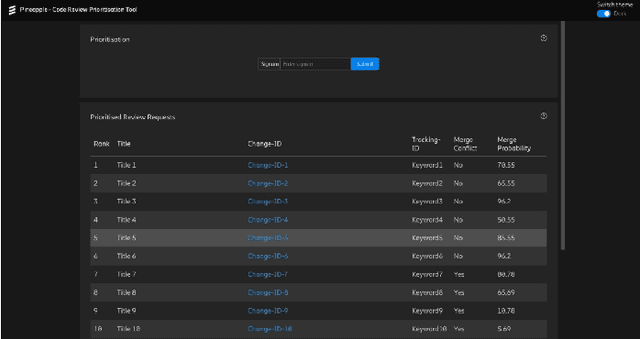
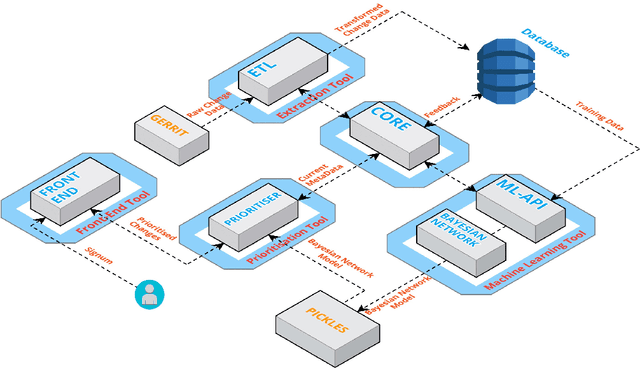
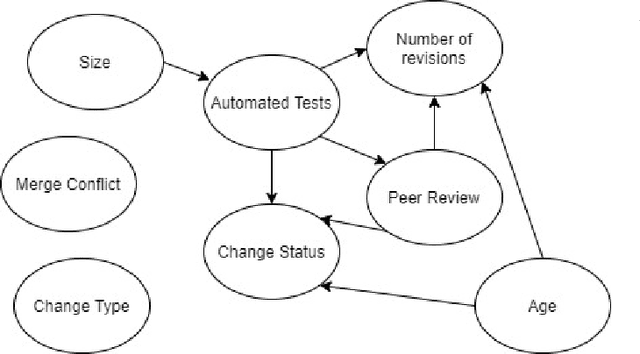
Modern Code Review (MCR) is the process of reviewing new code changes that need to be merged with an existing codebase. As a developer, one may receive many code review requests every day, i.e., the review requests need to be prioritised. Manually prioritising review requests is a challenging and time-consuming process. To address the above problem, we conducted an industrial case study at Ericsson aiming at developing a tool called Pineapple, which uses a Bayesian Network to prioritise code review requests. To validate our approach/tool, we deployed it in a live software development project at Ericsson, wherein more than 150 developers develop a telecommunication product. We focused on evaluating the predictive performance, feasibility, and usefulness of our approach. The results indicate that Pineapple has competent predictive performance (RMSE = 0.21 and MAE = 0.15). Furthermore, around 82.6% of Pineapple's users believe the tool can support code review request prioritisation by providing reliable results, and around 56.5% of the users believe it helps reducing code review lead time. As future work, we plan to evaluate Pineapple's predictive performance, usefulness, and feasibility through a longitudinal investigation.
BULNER: BUg Localization with word embeddings and NEtwork Regularization
Aug 26, 2019

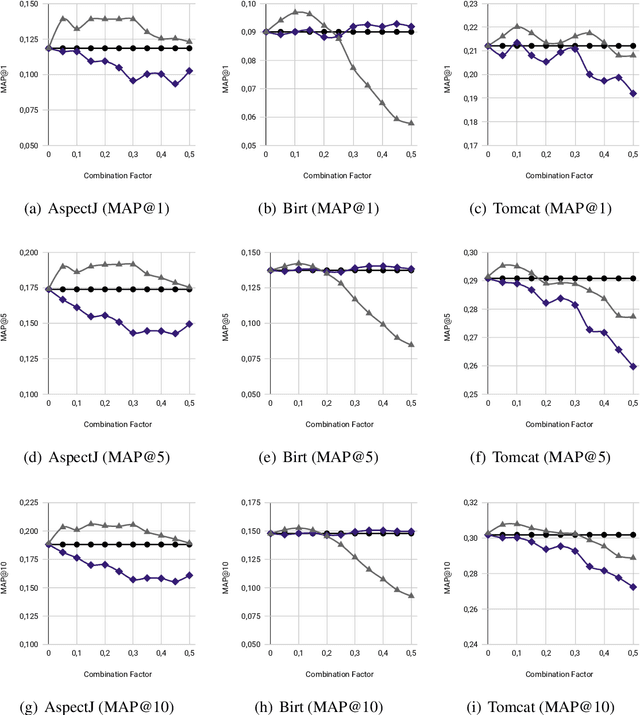
Bug localization (BL) from the bug report is the strategic activity of the software maintaining process. Because BL is a costly and tedious activity, BL techniques information retrieval-based and machine learning-based could aid software engineers. We propose a method for BUg Localization with word embeddings and Network Regularization (BULNER). The preliminary results suggest that BULNER has better performance than two state-of-the-art methods.