 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIcing on the Cake: Automatic Code Summarization at Ericsson
Aug 19, 2024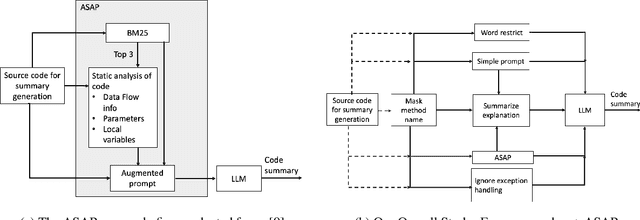
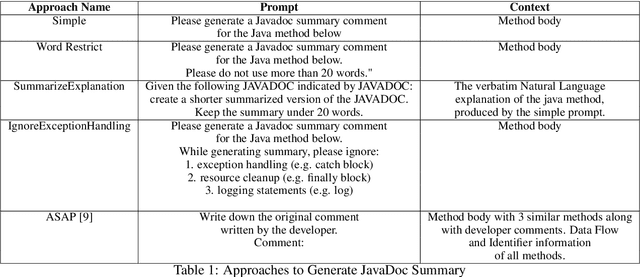
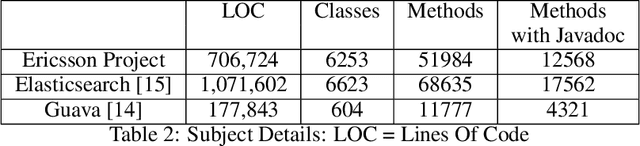
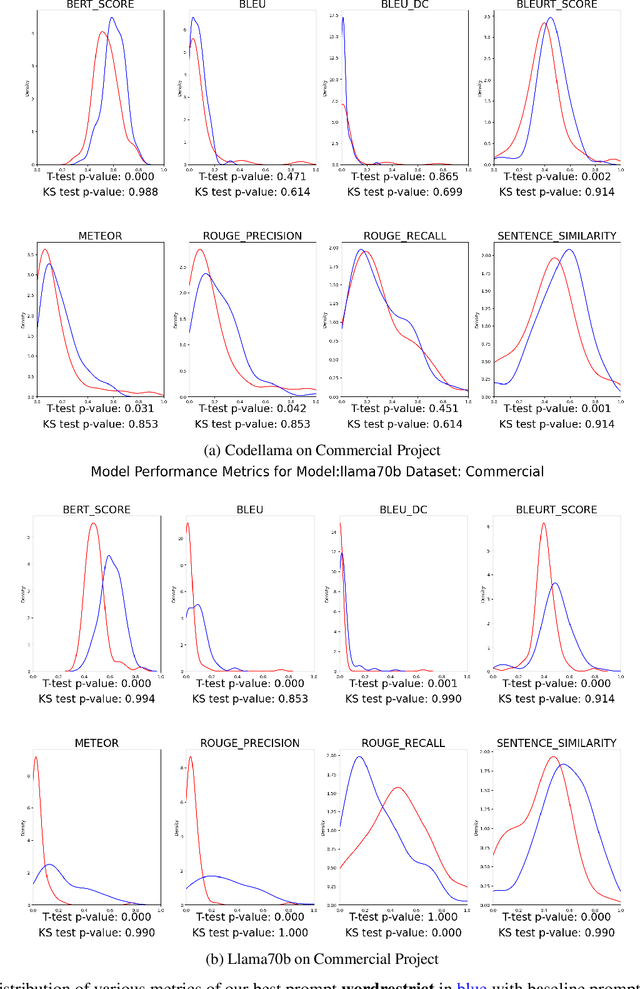
This paper presents our findings on the automatic summarization of Java methods within Ericsson, a global telecommunications company. We evaluate the performance of an approach called Automatic Semantic Augmentation of Prompts (ASAP), which uses a Large Language Model (LLM) to generate leading summary comments for Java methods. ASAP enhances the $LLM's$ prompt context by integrating static program analysis and information retrieval techniques to identify similar exemplar methods along with their developer-written Javadocs, and serves as the baseline in our study. In contrast, we explore and compare the performance of four simpler approaches that do not require static program analysis, information retrieval, or the presence of exemplars as in the ASAP method. Our methods rely solely on the Java method body as input, making them lightweight and more suitable for rapid deployment in commercial software development environments. We conducted experiments on an Ericsson software project and replicated the study using two widely-used open-source Java projects, Guava and Elasticsearch, to ensure the reliability of our results. Performance was measured across eight metrics that capture various aspects of similarity. Notably, one of our simpler approaches performed as well as or better than the ASAP method on both the Ericsson project and the open-source projects. Additionally, we performed an ablation study to examine the impact of method names on Javadoc summary generation across our four proposed approaches and the ASAP method. By masking the method names and observing the generated summaries, we found that our approaches were statistically significantly less influenced by the absence of method names compared to the baseline. This suggests that our methods are more robust to variations in method names and may derive summaries more comprehensively from the method body than the ASAP approach.
Observations on LLMs for Telecom Domain: Capabilities and Limitations
May 22, 2023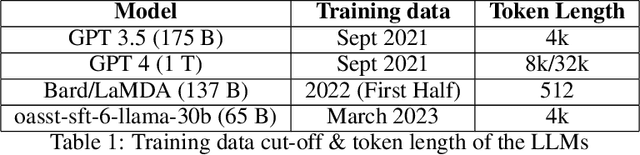
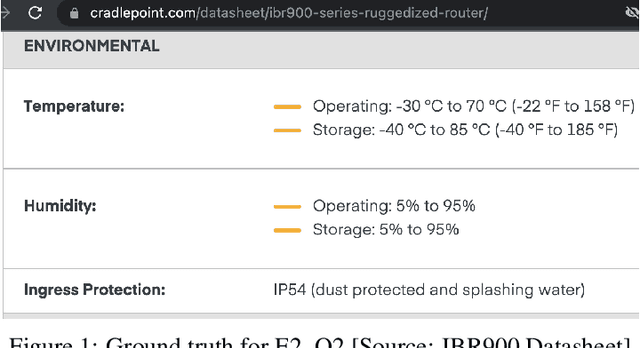


The landscape for building conversational interfaces (chatbots) has witnessed a paradigm shift with recent developments in generative Artificial Intelligence (AI) based Large Language Models (LLMs), such as ChatGPT by OpenAI (GPT3.5 and GPT4), Google's Bard, Large Language Model Meta AI (LLaMA), among others. In this paper, we analyze capabilities and limitations of incorporating such models in conversational interfaces for the telecommunication domain, specifically for enterprise wireless products and services. Using Cradlepoint's publicly available data for our experiments, we present a comparative analysis of the responses from such models for multiple use-cases including domain adaptation for terminology and product taxonomy, context continuity, robustness to input perturbations and errors. We believe this evaluation would provide useful insights to data scientists engaged in building customized conversational interfaces for domain-specific requirements.