 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation of Domain-adapted LLMs for Question-Answering in Telecom
Apr 28, 2025



Knowledge Distillation (KD) is one of the approaches to reduce the size of Large Language Models (LLMs). A LLM with smaller number of model parameters (student) is trained to mimic the performance of a LLM of a larger size (teacher model) on a specific task. For domain-specific tasks, it is not clear if teacher or student model, or both, must be considered for domain adaptation. In this work, we study this problem from perspective of telecom domain Question-Answering (QA) task. We systematically experiment with Supervised Fine-tuning (SFT) of teacher only, SFT of student only and SFT of both prior to KD. We design experiments to study the impact of vocabulary (same and different) and KD algorithms (vanilla KD and Dual Space KD, DSKD) on the distilled model. Multi-faceted evaluation of the distillation using 14 different metrics (N-gram, embedding and LLM-based metrics) is considered. Experimental results show that SFT of teacher improves performance of distilled model when both models have same vocabulary, irrespective of algorithm and metrics. Overall, SFT of both teacher and student results in better performance across all metrics, although the statistical significance of the same depends on the vocabulary of the teacher models.
Evaluation of Table Representations to Answer Questions from Tables in Documents : A Case Study using 3GPP Specifications
Aug 30, 2024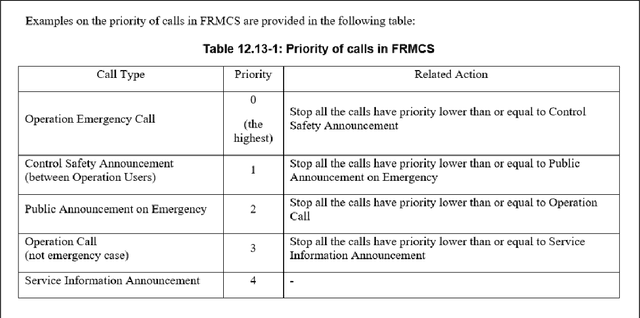
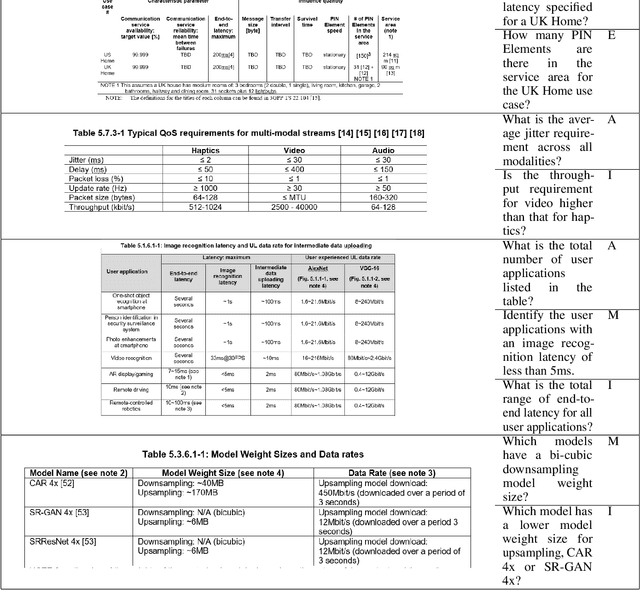
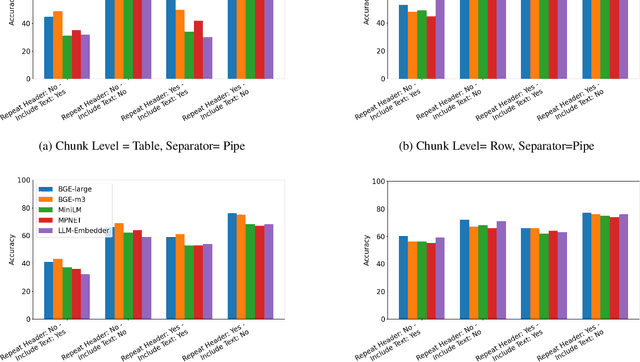
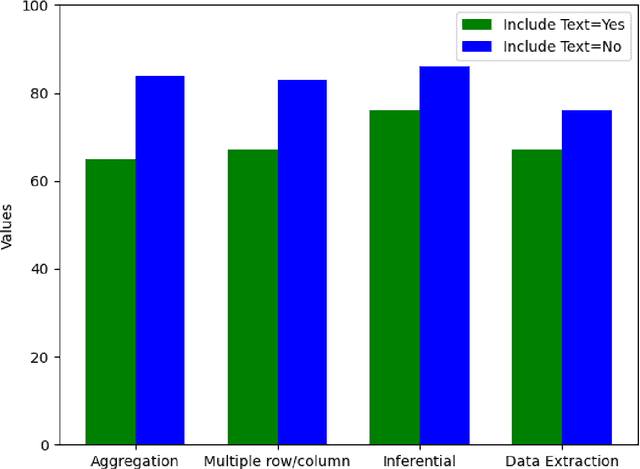
With the ubiquitous use of document corpora for question answering, one important aspect which is especially relevant for technical documents is the ability to extract information from tables which are interspersed with text. The major challenge in this is that unlike free-flow text or isolated set of tables, the representation of a table in terms of what is a relevant chunk is not obvious. We conduct a series of experiments examining various representations of tabular data interspersed with text to understand the relative benefits of different representations. We choose a corpus of $3^{rd}$ Generation Partnership Project (3GPP) documents since they are heavily interspersed with tables. We create expert curated dataset of question answers to evaluate our approach. We conclude that row level representations with corresponding table header information being included in every cell improves the performance of the retrieval, thus leveraging the structural information present in the tabular data.
Icing on the Cake: Automatic Code Summarization at Ericsson
Aug 19, 2024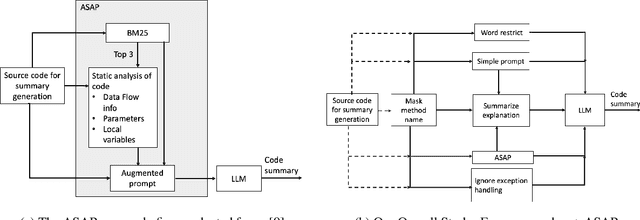
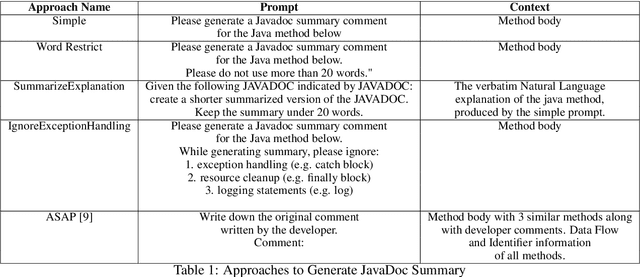
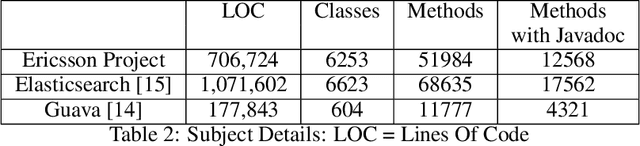
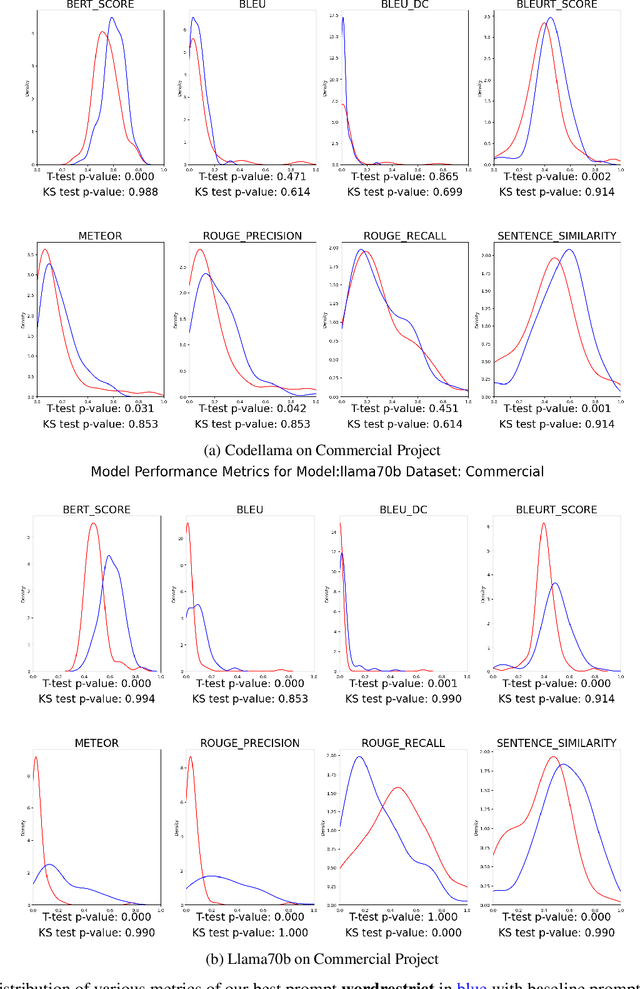
This paper presents our findings on the automatic summarization of Java methods within Ericsson, a global telecommunications company. We evaluate the performance of an approach called Automatic Semantic Augmentation of Prompts (ASAP), which uses a Large Language Model (LLM) to generate leading summary comments for Java methods. ASAP enhances the $LLM's$ prompt context by integrating static program analysis and information retrieval techniques to identify similar exemplar methods along with their developer-written Javadocs, and serves as the baseline in our study. In contrast, we explore and compare the performance of four simpler approaches that do not require static program analysis, information retrieval, or the presence of exemplars as in the ASAP method. Our methods rely solely on the Java method body as input, making them lightweight and more suitable for rapid deployment in commercial software development environments. We conducted experiments on an Ericsson software project and replicated the study using two widely-used open-source Java projects, Guava and Elasticsearch, to ensure the reliability of our results. Performance was measured across eight metrics that capture various aspects of similarity. Notably, one of our simpler approaches performed as well as or better than the ASAP method on both the Ericsson project and the open-source projects. Additionally, we performed an ablation study to examine the impact of method names on Javadoc summary generation across our four proposed approaches and the ASAP method. By masking the method names and observing the generated summaries, we found that our approaches were statistically significantly less influenced by the absence of method names compared to the baseline. This suggests that our methods are more robust to variations in method names and may derive summaries more comprehensively from the method body than the ASAP approach.
Evaluation of RAG Metrics for Question Answering in the Telecom Domain
Jul 15, 2024



Retrieval Augmented Generation (RAG) is widely used to enable Large Language Models (LLMs) perform Question Answering (QA) tasks in various domains. However, RAG based on open-source LLM for specialized domains has challenges of evaluating generated responses. A popular framework in the literature is the RAG Assessment (RAGAS), a publicly available library which uses LLMs for evaluation. One disadvantage of RAGAS is the lack of details of derivation of numerical value of the evaluation metrics. One of the outcomes of this work is a modified version of this package for few metrics (faithfulness, context relevance, answer relevance, answer correctness, answer similarity and factual correctness) through which we provide the intermediate outputs of the prompts by using any LLMs. Next, we analyse the expert evaluations of the output of the modified RAGAS package and observe the challenges of using it in the telecom domain. We also study the effect of the metrics under correct vs. wrong retrieval and observe that few of the metrics have higher values for correct retrieval. We also study for differences in metrics between base embeddings and those domain adapted via pre-training and fine-tuning. Finally, we comment on the suitability and challenges of using these metrics for in-the-wild telecom QA task.
A Compass for Navigating the World of Sentence Embeddings for the Telecom Domain
Jun 18, 2024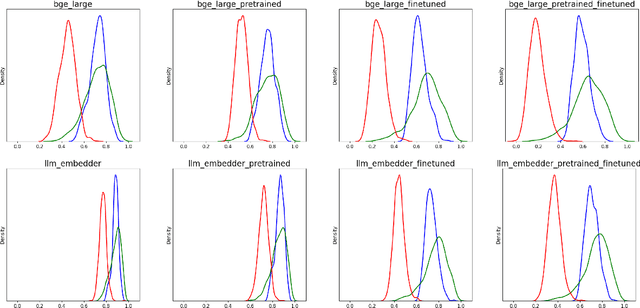
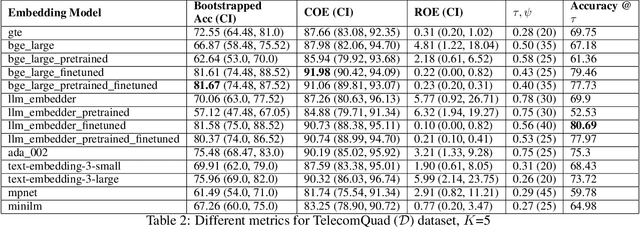
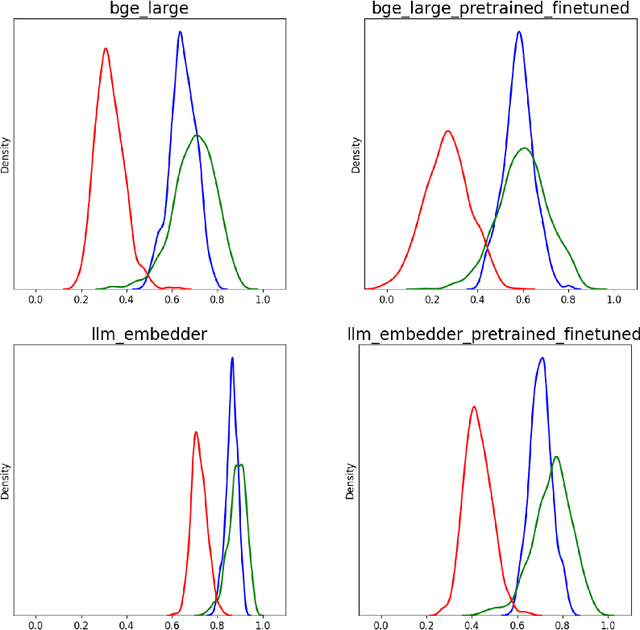
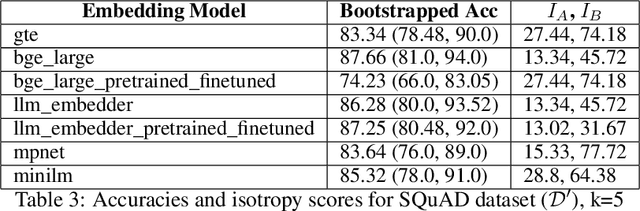
A plethora of sentence embedding models makes it challenging to choose one, especially for domains such as telecom, rich with specialized vocabulary. We evaluate multiple embeddings obtained from publicly available models and their domain-adapted variants, on both point retrieval accuracies as well as their (95\%) confidence intervals. We establish a systematic method to obtain thresholds for similarity scores for different embeddings. We observe that fine-tuning improves mean bootstrapped accuracies as well as tightens confidence intervals. The pre-training combined with fine-tuning makes confidence intervals even tighter. To understand these variations, we analyse and report significant correlations between the distributional overlap between top-$K$, correct and random sentence similarities with retrieval accuracies and similarity thresholds. Following current literature, we analyze if retrieval accuracy variations can be attributed to isotropy of embeddings. Our conclusions are that isotropy of embeddings (as measured by two independent state-of-the-art isotropy metric definitions) cannot be attributed to better retrieval performance. However, domain adaptation which improves retrieval accuracies also improves isotropy. We establish that domain adaptation moves domain specific embeddings further away from general domain embeddings.
Observations on Building RAG Systems for Technical Documents
Mar 31, 2024



Retrieval augmented generation (RAG) for technical documents creates challenges as embeddings do not often capture domain information. We review prior art for important factors affecting RAG and perform experiments to highlight best practices and potential challenges to build RAG systems for technical documents.
Observations on LLMs for Telecom Domain: Capabilities and Limitations
May 22, 2023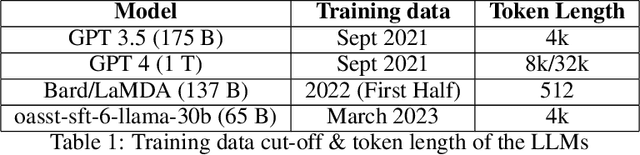
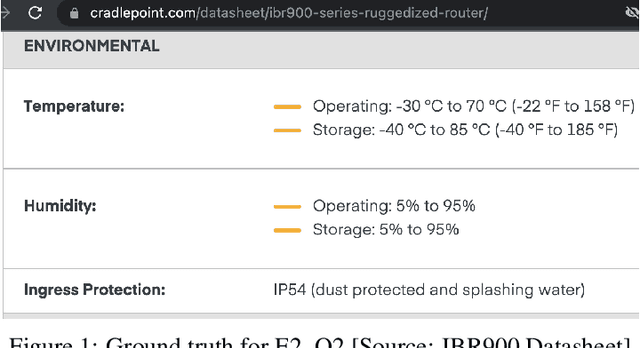


The landscape for building conversational interfaces (chatbots) has witnessed a paradigm shift with recent developments in generative Artificial Intelligence (AI) based Large Language Models (LLMs), such as ChatGPT by OpenAI (GPT3.5 and GPT4), Google's Bard, Large Language Model Meta AI (LLaMA), among others. In this paper, we analyze capabilities and limitations of incorporating such models in conversational interfaces for the telecommunication domain, specifically for enterprise wireless products and services. Using Cradlepoint's publicly available data for our experiments, we present a comparative analysis of the responses from such models for multiple use-cases including domain adaptation for terminology and product taxonomy, context continuity, robustness to input perturbations and errors. We believe this evaluation would provide useful insights to data scientists engaged in building customized conversational interfaces for domain-specific requirements.
Twin Augmented Architectures for Robust Classification of COVID-19 Chest X-Ray Images
Feb 16, 2021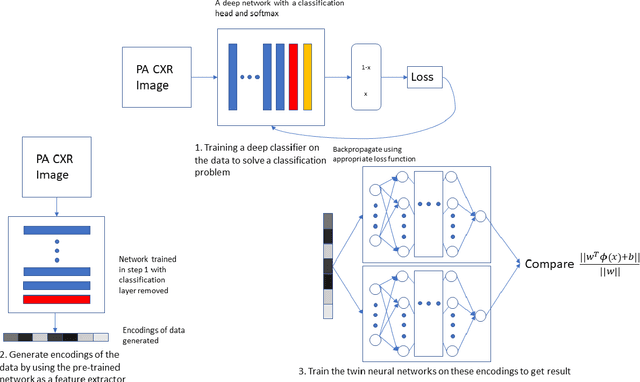
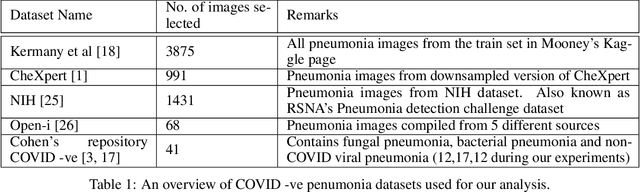
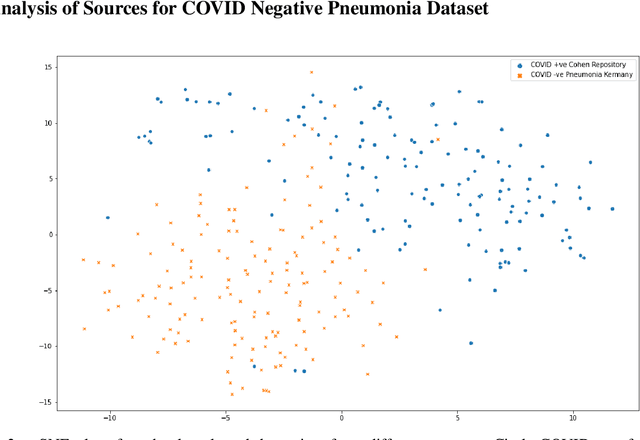
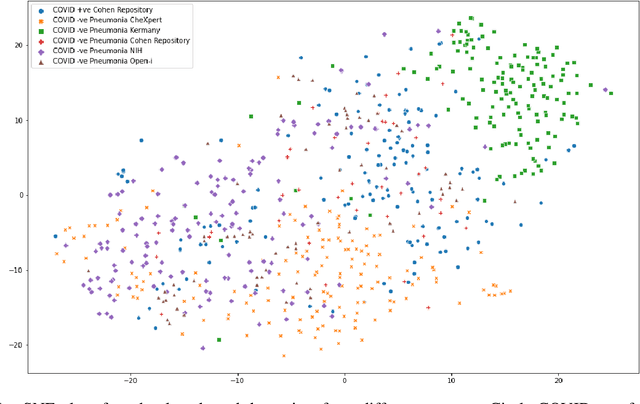
The gold standard for COVID-19 is RT-PCR, testing facilities for which are limited and not always optimally distributed. Test results are delayed, which impacts treatment. Expert radiologists, one of whom is a co-author, are able to diagnose COVID-19 positivity from Chest X-Rays (CXR) and CT scans, that can facilitate timely treatment. Such diagnosis is particularly valuable in locations lacking radiologists with sufficient expertise and familiarity with COVID-19 patients. This paper has two contributions. One, we analyse literature on CXR based COVID-19 diagnosis. We show that popular choices of dataset selection suffer from data homogeneity, leading to misleading results. We compile and analyse a viable benchmark dataset from multiple existing heterogeneous sources. Such a benchmark is important for realistically testing models. Our second contribution relates to learning from imbalanced data. Datasets for COVID X-Ray classification face severe class imbalance, since most subjects are COVID -ve. Twin Support Vector Machines (Twin SVM) and Twin Neural Networks (Twin NN) have, in recent years, emerged as effective ways of handling skewed data. We introduce a state-of-the-art technique, termed as Twin Augmentation, for modifying popular pre-trained deep learning models. Twin Augmentation boosts the performance of a pre-trained deep neural network without requiring re-training. Experiments show, that across a multitude of classifiers, Twin Augmentation is very effective in boosting the performance of given pre-trained model for classification in imbalanced settings.
Complexity Controlled Generative Adversarial Networks
Nov 20, 2020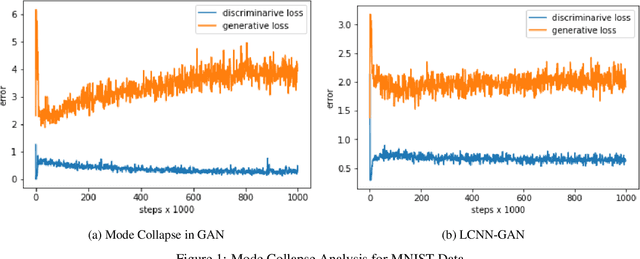
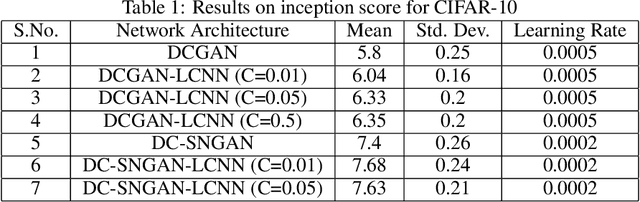


One of the issues faced in training Generative Adversarial Nets (GANs) and their variants is the problem of mode collapse, wherein the training stability in terms of the generative loss increases as more training data is used. In this paper, we propose an alternative architecture via the Low-Complexity Neural Network (LCNN), which attempts to learn models with low complexity. The motivation is that controlling model complexity leads to models that do not overfit the training data. We incorporate the LCNN loss function for GANs, Deep Convolutional GANs (DCGANs) and Spectral Normalized GANs (SNGANs), in order to develop hybrid architectures called the LCNN-GAN, LCNN-DCGAN and LCNN-SNGAN respectively. On various large benchmark image datasets, we show that the use of our proposed models results in stable training while avoiding the problem of mode collapse, resulting in better training stability. We also show how the learning behavior can be controlled by a hyperparameter in the LCNN functional, which also provides an improved inception score.
An Online Learning Approach for Dengue Fever Classification
Apr 17, 2019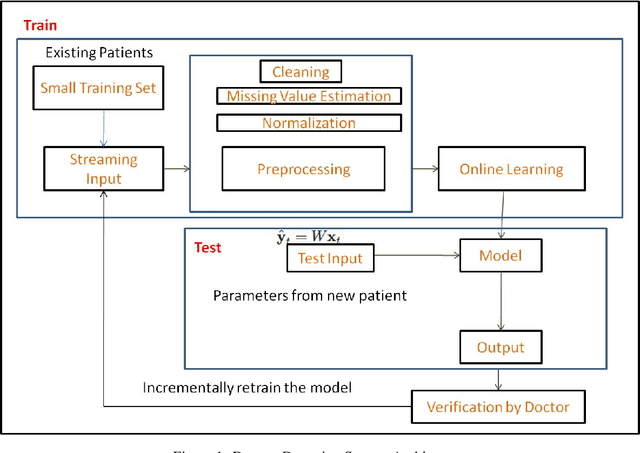
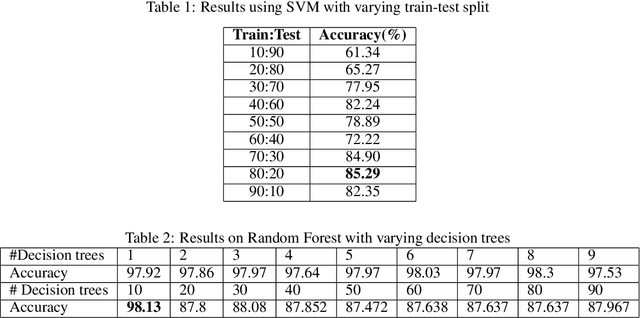
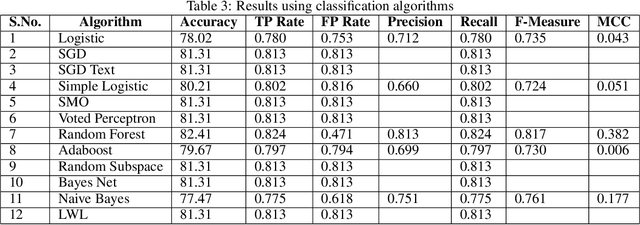
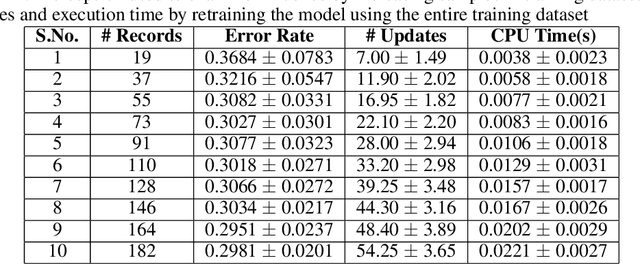
This paper introduces a novel approach for dengue fever classification based on online learning paradigms. The proposed approach is suitable for practical implementation as it enables learning using only a few training samples. With time, the proposed approach is capable of learning incrementally from the data collected without need for retraining the model or redeployment of the prediction engine. Additionally, we also provide a comprehensive evaluation of machine learning methods for prediction of dengue fever. The input to the proposed pipeline comprises of recorded patient symptoms and diagnostic investigations. Offline classifier models have been employed to obtain baseline scores to establish that the feature set is optimal for classification of dengue. The primary benefit of the online detection model presented in the paper is that it has been established to effectively identify patients with high likelihood of dengue disease, and experiments on scalability in terms of number of training and test samples validate the use of the proposed model.