 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Table Representations to Answer Questions from Tables in Documents : A Case Study using 3GPP Specifications
Paper and Code
Aug 30, 2024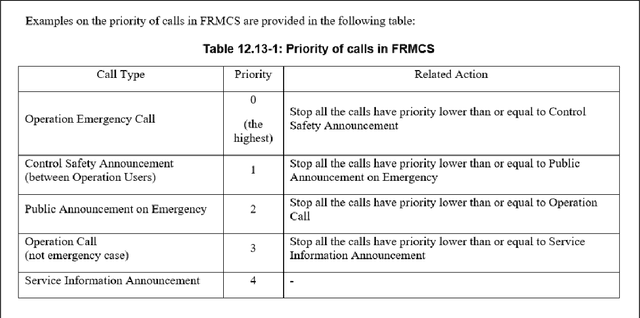
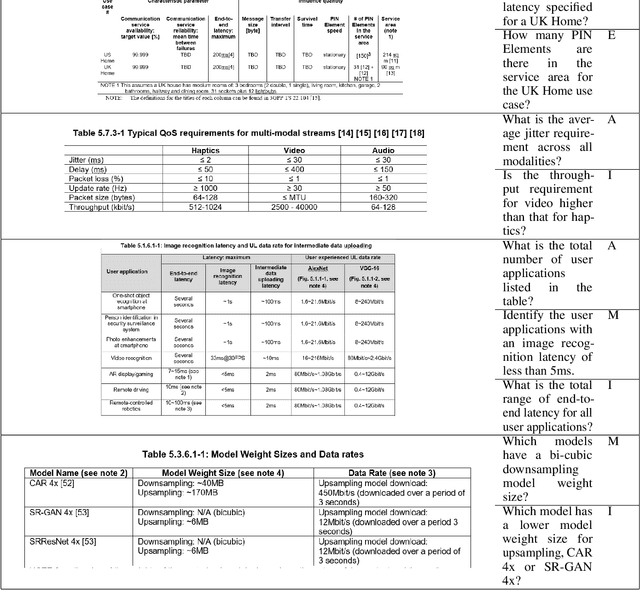
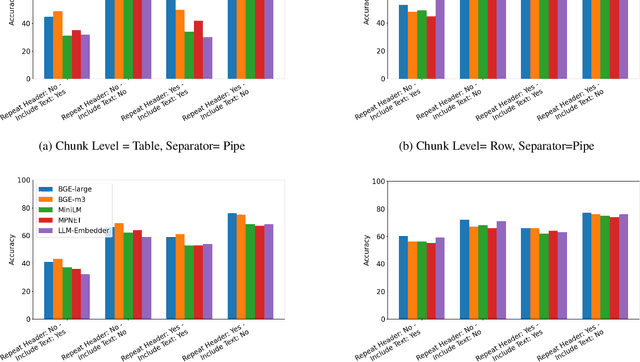
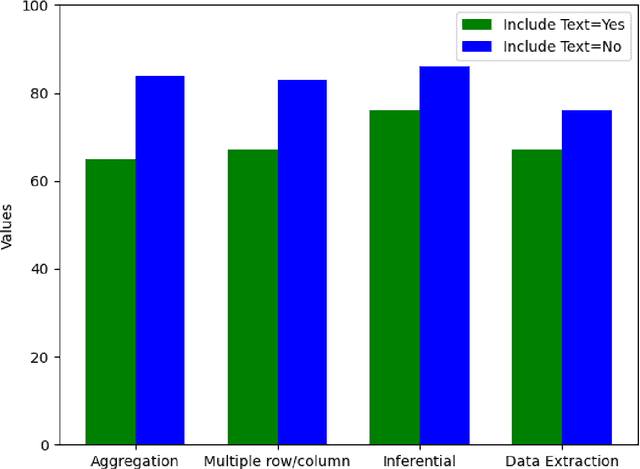
With the ubiquitous use of document corpora for question answering, one important aspect which is especially relevant for technical documents is the ability to extract information from tables which are interspersed with text. The major challenge in this is that unlike free-flow text or isolated set of tables, the representation of a table in terms of what is a relevant chunk is not obvious. We conduct a series of experiments examining various representations of tabular data interspersed with text to understand the relative benefits of different representations. We choose a corpus of $3^{rd}$ Generation Partnership Project (3GPP) documents since they are heavily interspersed with tables. We create expert curated dataset of question answers to evaluate our approach. We conclude that row level representations with corresponding table header information being included in every cell improves the performance of the retrieval, thus leveraging the structural information present in the tabular data.