 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of RAG Metrics for Question Answering in the Telecom Domain
Jul 15, 2024



Retrieval Augmented Generation (RAG) is widely used to enable Large Language Models (LLMs) perform Question Answering (QA) tasks in various domains. However, RAG based on open-source LLM for specialized domains has challenges of evaluating generated responses. A popular framework in the literature is the RAG Assessment (RAGAS), a publicly available library which uses LLMs for evaluation. One disadvantage of RAGAS is the lack of details of derivation of numerical value of the evaluation metrics. One of the outcomes of this work is a modified version of this package for few metrics (faithfulness, context relevance, answer relevance, answer correctness, answer similarity and factual correctness) through which we provide the intermediate outputs of the prompts by using any LLMs. Next, we analyse the expert evaluations of the output of the modified RAGAS package and observe the challenges of using it in the telecom domain. We also study the effect of the metrics under correct vs. wrong retrieval and observe that few of the metrics have higher values for correct retrieval. We also study for differences in metrics between base embeddings and those domain adapted via pre-training and fine-tuning. Finally, we comment on the suitability and challenges of using these metrics for in-the-wild telecom QA task.
A Compass for Navigating the World of Sentence Embeddings for the Telecom Domain
Jun 18, 2024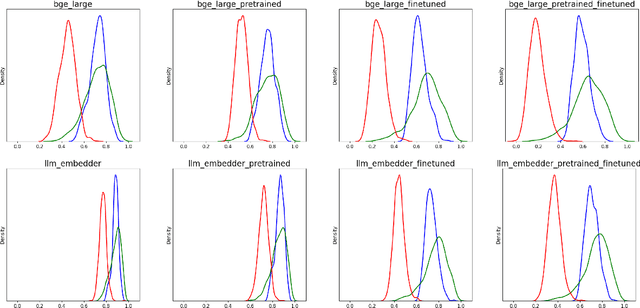
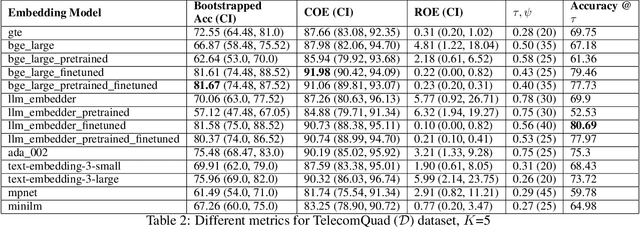
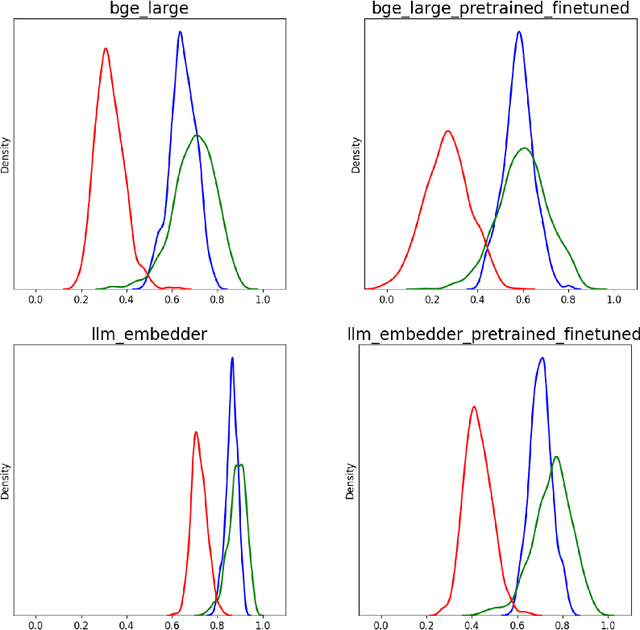
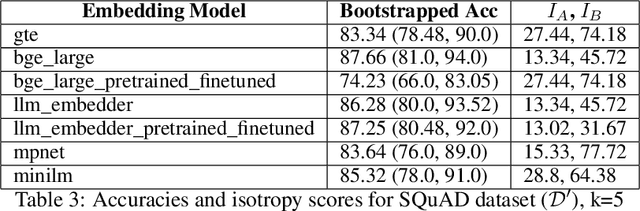
A plethora of sentence embedding models makes it challenging to choose one, especially for domains such as telecom, rich with specialized vocabulary. We evaluate multiple embeddings obtained from publicly available models and their domain-adapted variants, on both point retrieval accuracies as well as their (95\%) confidence intervals. We establish a systematic method to obtain thresholds for similarity scores for different embeddings. We observe that fine-tuning improves mean bootstrapped accuracies as well as tightens confidence intervals. The pre-training combined with fine-tuning makes confidence intervals even tighter. To understand these variations, we analyse and report significant correlations between the distributional overlap between top-$K$, correct and random sentence similarities with retrieval accuracies and similarity thresholds. Following current literature, we analyze if retrieval accuracy variations can be attributed to isotropy of embeddings. Our conclusions are that isotropy of embeddings (as measured by two independent state-of-the-art isotropy metric definitions) cannot be attributed to better retrieval performance. However, domain adaptation which improves retrieval accuracies also improves isotropy. We establish that domain adaptation moves domain specific embeddings further away from general domain embeddings.