 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Hybrid Framework for Real-Time Data Drift and Anomaly Identification Using Hierarchical Temporal Memory and Statistical Tests
Apr 24, 2025



Data Drift is the phenomenon where the generating model behind the data changes over time. Due to data drift, any model built on the past training data becomes less relevant and inaccurate over time. Thus, detecting and controlling for data drift is critical in machine learning models. Hierarchical Temporal Memory (HTM) is a machine learning model developed by Jeff Hawkins, inspired by how the human brain processes information. It is a biologically inspired model of memory that is similar in structure to the neocortex, and whose performance is claimed to be comparable to state of the art models in detecting anomalies in time series data. Another unique benefit of HTMs is its independence from training and testing cycle; all the learning takes place online with streaming data and no separate training and testing cycle is required. In sequential learning paradigm, Sequential Probability Ratio Test (SPRT) offers some unique benefit for online learning and inference. This paper proposes a novel hybrid framework combining HTM and SPRT for real-time data drift detection and anomaly identification. Unlike existing data drift methods, our approach eliminates frequent retraining and ensures low false positive rates. HTMs currently work with one dimensional or univariate data. In a second study, we also propose an application of HTM in multidimensional supervised scenario for anomaly detection by combining the outputs of multiple HTM columns, one for each dimension of the data, through a neural network. Experimental evaluations demonstrate that the proposed method outperforms conventional drift detection techniques like the Kolmogorov-Smirnov (KS) test, Wasserstein distance, and Population Stability Index (PSI) in terms of accuracy, adaptability, and computational efficiency. Our experiments also provide insights into optimizing hyperparameters for real-time deployment in domains such as Telecom.
* 26 pages, 9 figures
A Compass for Navigating the World of Sentence Embeddings for the Telecom Domain
Jun 18, 2024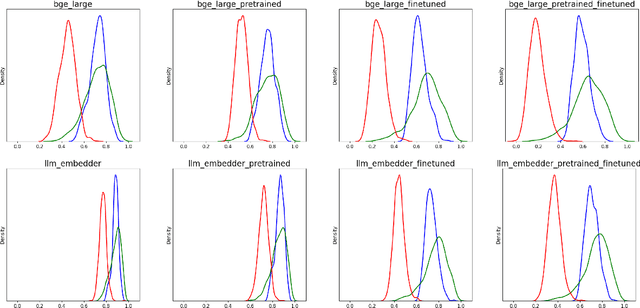
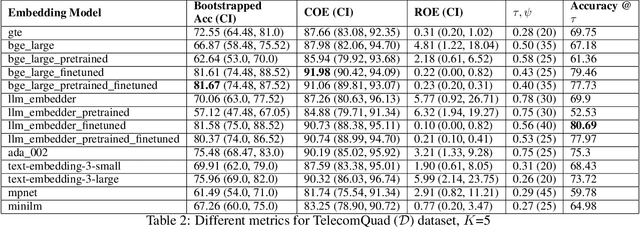
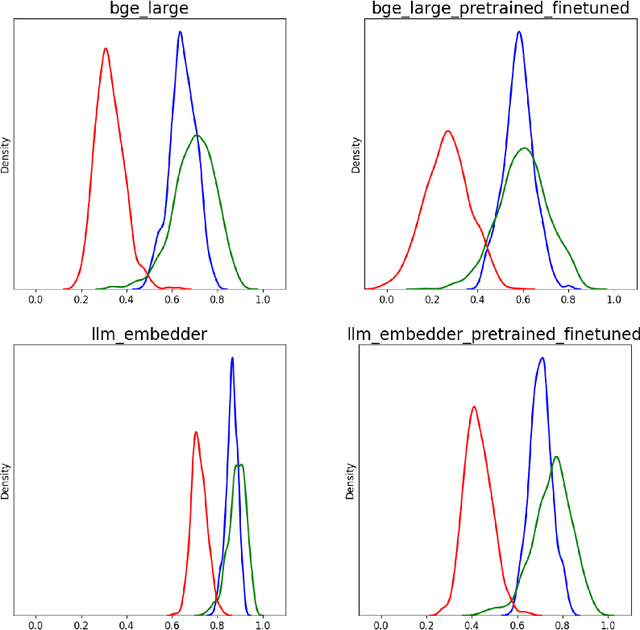
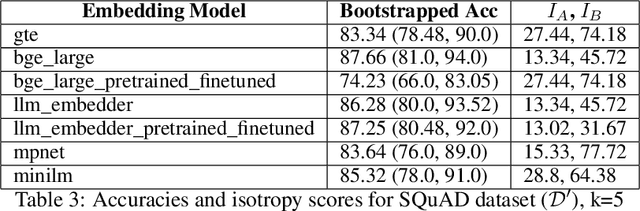
A plethora of sentence embedding models makes it challenging to choose one, especially for domains such as telecom, rich with specialized vocabulary. We evaluate multiple embeddings obtained from publicly available models and their domain-adapted variants, on both point retrieval accuracies as well as their (95\%) confidence intervals. We establish a systematic method to obtain thresholds for similarity scores for different embeddings. We observe that fine-tuning improves mean bootstrapped accuracies as well as tightens confidence intervals. The pre-training combined with fine-tuning makes confidence intervals even tighter. To understand these variations, we analyse and report significant correlations between the distributional overlap between top-$K$, correct and random sentence similarities with retrieval accuracies and similarity thresholds. Following current literature, we analyze if retrieval accuracy variations can be attributed to isotropy of embeddings. Our conclusions are that isotropy of embeddings (as measured by two independent state-of-the-art isotropy metric definitions) cannot be attributed to better retrieval performance. However, domain adaptation which improves retrieval accuracies also improves isotropy. We establish that domain adaptation moves domain specific embeddings further away from general domain embeddings.