 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Framework for Graph-Conditioned Hierarchical Shapley Attribution in Patent Valuation
Jun 01, 2026Estimating the economic contribution of a single patent inside a product that embodies tens of thousands of patents is a long-standing unsolved problem in intellectual property economics. We propose PatentXAI, a framework that treats patent valuation as a problem of explainable AI: given a characteristic function v(S) encoding the revenue achievable by patent subset S, a patent's Shapley value measures its fair share of product profit in a way that satisfies efficiency, symmetry, dummy, and additivity. To make computation tractable we restrict each patent's coalition to its Markov Blanket inside a knowledge graph, grounded in the C-SVE conditional independence theorem (Li et al., 2020). Scaling experiments from n=12 to n=100 patents using Pareto-distributed coverage graphs report median Markov Blanket size of 32.9 percent of n at n=100, with 90th-percentile blanket size of 55.2 percent of n, and runtime of 10 milliseconds per patent. Difference against exact ground truth at n=12 is 0.088; difference against a high-sample Monte Carlo reference at n=100 is 0.062 plus or minus 0.003. A dense-component experiment shows that when 80 percent of patents share one component, the blanket correctly expands to cover that dense cluster, and the difference versus reference falls to 0.039 because the pooled computation becomes more accurate on homogeneous portfolios. Profit allocation proceeds hierarchically: exact Shapley distributes total profit among macro-components, then centrality-weighted Shapley distributes each component budget among covering patents. Estimating v(S) from real data is the primary open problem; we distinguish this from the computational contribution and outline a concrete roadmap for empirical validation using public ETSI, USPTO, and Lens.org datasets.
Attention Asymmetry in AI Layoff Discourse on X: A Computational Analysis of Capital vs Labour Amplification
May 28, 2026When workers lose jobs to AI-driven restructuring, two very different conversations happen on X (formerly Twitter) at the same time. Tech executives and AI researchers talk about productivity, transformation, and opportunity. Laid-off workers and labour critics talk about job loss, uncertainty, and fear. This paper asks a simple question: which conversation gets more reach? We report three studies using two collection methods and 763 tweets from 20 named public accounts. Study 1 used keyword-based collection (n=392) and found no significant difference between corpora (p=0.891), revealing that keyword search is too noisy for this task. Study 2 used account-based collection (n=96) and found a 3.12x mean amplification advantage for capital discourse over labour discourse (p=0.000003, Cohen's d=0.555). Study 3 combined both methods (n=763) and confirmed the finding at 4.18x mean and 10.77x median amplification ratio (p<0.000001). Critically, after normalising for follower count, the asymmetry persists at 2.69x (p=0.000009, Cohen's d=0.491), demonstrating that the effect is not simply a consequence of capital accounts having larger audiences. The finding is robust across all tested amplification metric weightings. We introduce the Amplification Ratio and Amplification Normalisation Index as simple metrics for measuring platform-level discourse inequality. A cross-platform replication on Reddit (n=647 posts) did not replicate the finding, suggesting the asymmetry may be specific to X's account-based amplification architecture. We discuss the methodological implications for cross-platform discourse analysis.
Temporal Coding as a Substrate for Sensorimotor Object Inference: A Spiking Reinterpretation of Thousand Brains Architecture
May 21, 2026The Thousand Brains Theory (TBT) and its open-source Monty framework model object recognition through sensorimotor inference -- identifying objects by actively moving a sensor across their surface and building evidence contact by contact. The current implementation encodes each contact as a dense floating-point vector. While Monty tracks inter-step displacement and accumulates evidence across contacts, it treats the feature activation pattern at each contact as an unordered set - the directional sequence in which features are encountered carries no representational weight. In TBT, the sequence of contacts carries spatial meaning: knowing that feature A was felt before feature B during a left-to-right sweep tells you something about where A and B sit on the object. Dense vectors discard this ordering. We propose replacing dense vectors with rank-order spike packets: each contact produces a brief burst of neural events where the most strongly activated neuron fires first. The time gap between successive bursts implicitly encodes sensor displacement without explicit coordinate calculations. A biologically motivated learning rule (STDP) encodes traversal direction into synaptic weights. A learnable parameter lambda adjusts reliance on earlier versus recent contacts, adapting to each object's geometry. We derive three testable predictions and specify an implementation of four components in approximately 450 lines of NumPy. Three synthetic experiments confirm the core claims: temporal coding achieves perfect discrimination accuracy on objects with identical features in different spatial arrangements, where dense accumulation performs at chance; temporal coding maintains a 30-50 percentage point advantage across all tested noise levels; the adaptive lambda converges to distinct values, reflecting object geometric complexity. End-to-end evaluation on Monty's YCB benchmark is left for future work.
IMLJD: A Computational Dataset for Indian Matrimonial Litigation Analysis
May 19, 2026We present IMLJD, an open dataset of 3,613 Indian court judgments covering matrimonial disputes under IPC Section 498A, the Protection of Women from Domestic Violence Act, and CrPC Section 482. The dataset covers the Supreme Court of India from 2000 to 2024 (1,474 cases) and the Karnataka High Court from 2018 to 2024 (2,139 cases), with structured outcome labels, metadata-derived indicators, and a knowledge graph. We find that 57.6% of quashing petitions succeed at the Supreme Court level compared to 39.7% at the Karnataka High Court level. On a matched 2018 to 2024 period, the SC quash rate is 59.3%, widening the differential to 19.6 percentage points and confirming the finding is robust to temporal adjustment. The dataset, code, and knowledge graph are released openly at https://github.com/joyboseroy/imljd and https://huggingface.co/datasets/joyboseroy/imljd.
Falkor-IRAC: Graph-Constrained Generation for Verified Legal Reasoning in Indian Judicial AI
May 14, 2026Legal reasoning is not semantic similarity search. A court judgment encodes constrained symbolic reasoning: precedent propagation, procedural state transitions, and statute-bound inference. These are properties that vector-based retrieval-augmented generation (RAG) cannot faithfully represent. Hallucinated precedents, outdated statute citations, and unsupported reasoning chains remain persistent failure modes in LLM-based legal AI, with real consequences for access to justice in high-caseload jurisdictions such as India. This paper presents Falkor-IRAC, a graph-constrained generation framework for Indian legal AI that grounds generation in structured reasoning over an IRAC (Issue, Rule, Analysis, Conclusion) knowledge graph. Judgments from the Supreme Court and High Courts of India are ingested as IRAC node structures enriched with procedural state transitions, precedent relationships, and statutory references, stored in FalkorDB for low-latency agentic traversal. At inference time, LLM-generated answers are accepted only if a valid supporting path can be traced through the graph, a check performed by a falsifiability oracle called the Verifier Agent. The system also detects doctrinal conflicts as a first-class output rather than silently resolving them. Falkor-IRAC is evaluated using graph-native metrics: citation grounding accuracy, path validity rate, hallucinated precedent rate, and conflict detection rate. These metrics are argued to be more appropriate for legal reasoning evaluation than BLEU and ROUGE. On a proof-of-concept corpus of 51 Supreme Court judgments, the Verifier Agent correctly validated citations on completed queries and correctly rejected fabricated citations. Evaluation against vector-only RAG baselines is left for future work, as is GPU-accelerated inference to address current timeout rates on CPU hardware.
IdeaForge: A Knowledge Graph-Grounded Multi-Agent Framework for Cross-Methodology Innovation Analysis and Patent Claim Generation
May 13, 2026Current AI-assisted innovation systems typically apply a single ideation methodology (such as TRIZ or Design Thinking) using sequential prompt-based workflows that do not preserve intermediate reasoning structure. As a result, insights generated across methodologies remain fragmented, limiting traceability, synthesis, and systematic evaluation of novelty. We present IdeaForge, a knowledge graph-grounded multi-agent framework for innovation analysis and patent claim generation. IdeaForge integrates multiple innovation methodologies (TRIZ, Design Thinking, and SCAMPER) through specialist agents operating over a persistent FalkorDB knowledge graph. Each agent contributes structured entities and relationships representing contradictions, inventive principles, user needs, transformations, analogies, and candidate claims. The central contribution of IdeaForge is a cross-methodology convergence mechanism implemented through graph-based claim linkage. Claims independently supported by multiple methodologies are connected using CONVERGENT relationships, enabling identification of high-confidence innovation candidates through graph traversal. A downstream patent drafting agent generates structured patent drafts grounded in convergent claim subgraphs, reducing reliance on unconstrained language model generation. An InnovationScore formula ranks claims by convergent support, methodology diversity, claim strength, and prior art challenge count. We describe the graph schema, agent architecture, convergence detection pipeline, and patent synthesis workflow. Experiments on a legal technology use case demonstrate that graph-grounded multi-methodology synthesis produces more diverse and traceable innovation candidates compared to single-methodology baselines. We discuss implications for computational creativity, explainable AI-assisted invention, and graph-native innovation systems.
Pendulum Model of Spiking Neurons
Jul 29, 2025We propose a biologically inspired model of spiking neurons based on the dynamics of a damped, driven pendulum. Unlike traditional models such as the Leaky Integrate-and-Fire (LIF) neurons, the pendulum neuron incorporates second-order, nonlinear dynamics that naturally give rise to oscillatory behavior and phase-based spike encoding. This model captures richer temporal features and supports timing-sensitive computations critical for sequence processing and symbolic learning. We present an analysis of single-neuron dynamics and extend the model to multi-neuron layers governed by Spike-Timing Dependent Plasticity (STDP) learning rules. We demonstrate practical implementation with python code and with the Brian2 spiking neural simulator, and outline a methodology for deploying the model on neuromorphic hardware platforms, using an approximation of the second-order equations. This framework offers a foundation for developing energy-efficient neural systems for neuromorphic computing and sequential cognition tasks.
A Hybrid Framework for Real-Time Data Drift and Anomaly Identification Using Hierarchical Temporal Memory and Statistical Tests
Apr 24, 2025



Data Drift is the phenomenon where the generating model behind the data changes over time. Due to data drift, any model built on the past training data becomes less relevant and inaccurate over time. Thus, detecting and controlling for data drift is critical in machine learning models. Hierarchical Temporal Memory (HTM) is a machine learning model developed by Jeff Hawkins, inspired by how the human brain processes information. It is a biologically inspired model of memory that is similar in structure to the neocortex, and whose performance is claimed to be comparable to state of the art models in detecting anomalies in time series data. Another unique benefit of HTMs is its independence from training and testing cycle; all the learning takes place online with streaming data and no separate training and testing cycle is required. In sequential learning paradigm, Sequential Probability Ratio Test (SPRT) offers some unique benefit for online learning and inference. This paper proposes a novel hybrid framework combining HTM and SPRT for real-time data drift detection and anomaly identification. Unlike existing data drift methods, our approach eliminates frequent retraining and ensures low false positive rates. HTMs currently work with one dimensional or univariate data. In a second study, we also propose an application of HTM in multidimensional supervised scenario for anomaly detection by combining the outputs of multiple HTM columns, one for each dimension of the data, through a neural network. Experimental evaluations demonstrate that the proposed method outperforms conventional drift detection techniques like the Kolmogorov-Smirnov (KS) test, Wasserstein distance, and Population Stability Index (PSI) in terms of accuracy, adaptability, and computational efficiency. Our experiments also provide insights into optimizing hyperparameters for real-time deployment in domains such as Telecom.
* 26 pages, 9 figures
Static Program Analysis Guided LLM Based Unit Test Generation
Mar 07, 2025



We describe a novel approach to automating unit test generation for Java methods using large language models (LLMs). Existing LLM-based approaches rely on sample usage(s) of the method to test (focal method) and/or provide the entire class of the focal method as input prompt and context. The former approach is often not viable due to the lack of sample usages, especially for newly written focal methods. The latter approach does not scale well enough; the bigger the complexity of the focal method and larger associated class, the harder it is to produce adequate test code (due to factors such as exceeding the prompt and context lengths of the underlying LLM). We show that augmenting prompts with \emph{concise} and \emph{precise} context information obtained by program analysis %of the focal method increases the effectiveness of generating unit test code through LLMs. We validate our approach on a large commercial Java project and a popular open-source Java project.
Modeling Effect of Lockdowns and Other Effects on India Covid-19 Infections Using SEIR Model and Machine Learning
Oct 04, 2021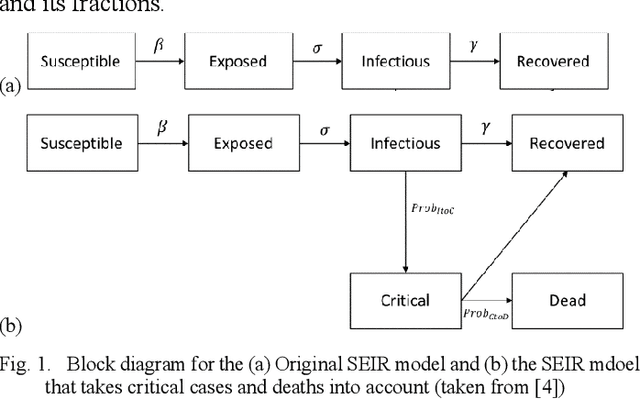

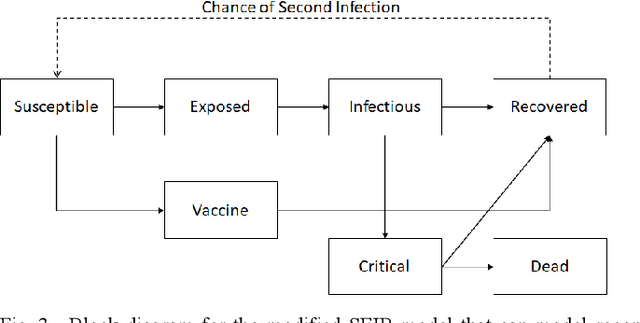

The SEIR model is a widely used epidemiological model used to predict the rise in infections. This model has been widely used in different countries to predict the number of Covid-19 cases. But the original SEIR model does not take into account the effect of factors such as lockdowns, vaccines, and re-infections. In India the first wave of Covid started in March 2020 and the second wave in April 2021. In this paper, we modify the SEIR model equations to model the effect of lockdowns and other influencers, and fit the model on data of the daily Covid-19 infections in India using lmfit, a python library for least squares minimization for curve fitting. We modify R0 parameter in the standard SEIR model as a rectangle in order to account for the effect of lockdowns. Our modified SEIR model accurately fits the available data of infections.