 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Software Engineering for Agile Machine Learning Projects
Dec 16, 2019


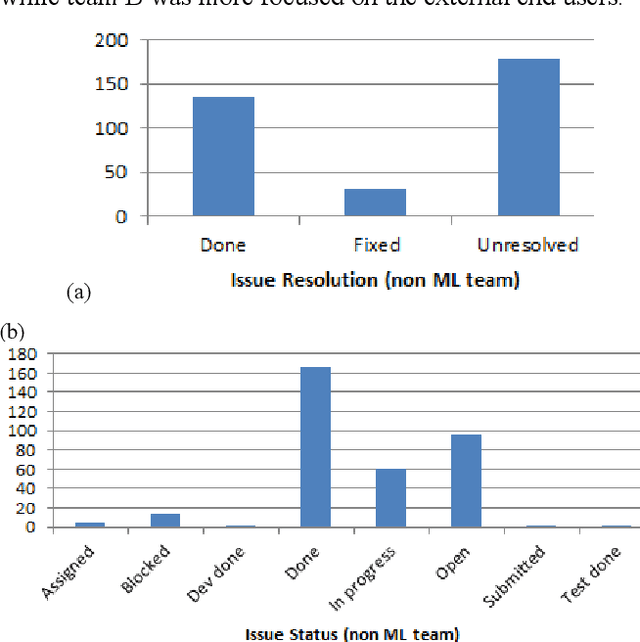
The number of machine learning, artificial intelligence or data science related software engineering projects using Agile methodology is increasing. However, there are very few studies on how such projects work in practice. In this paper, we analyze project issues tracking data taken from Scrum (a popular tool for Agile) for several machine learning projects. We compare this data with corresponding data from non-machine learning projects, in an attempt to analyze how machine learning projects are executed differently from normal software engineering projects. On analysis, we find that machine learning project issues use different kinds of words to describe issues, have higher number of exploratory or research oriented tasks as compared to implementation tasks, and have a higher number of issues in the product backlog after each sprint, denoting that it is more difficult to estimate the duration of machine learning project related tasks in advance. After analyzing this data, we propose a few ways in which Agile machine learning projects can be better logged and executed, given their differences with normal software engineering projects.
Improving Long Distance Slot Carryover in Spoken Dialogue Systems
Jun 04, 2019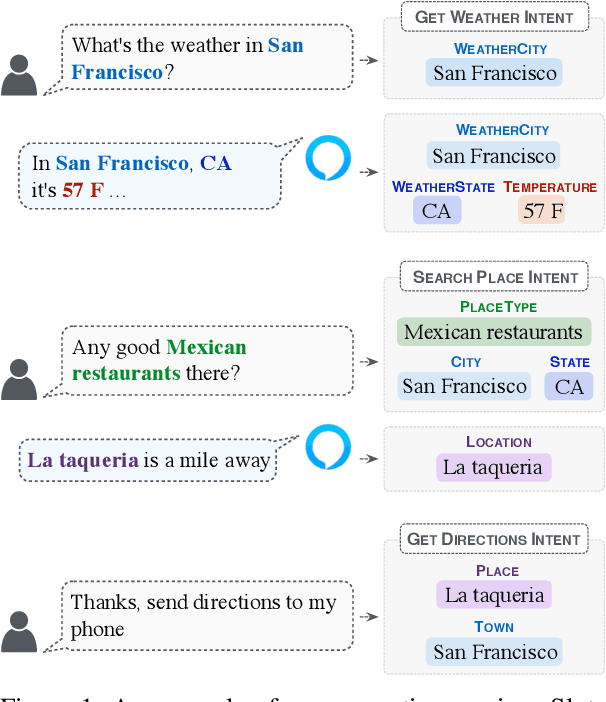
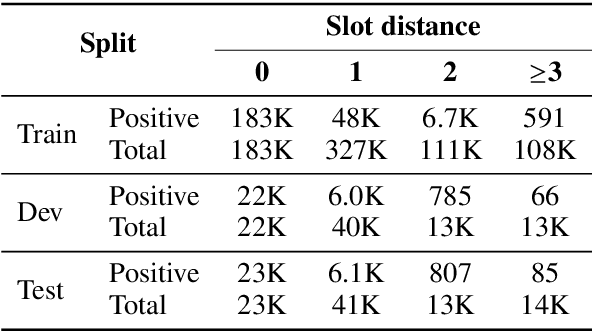

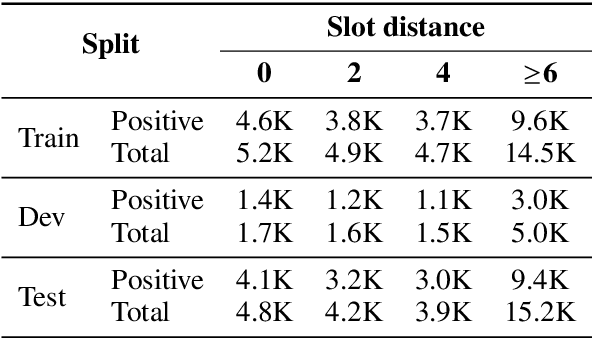
Tracking the state of the conversation is a central component in task-oriented spoken dialogue systems. One such approach for tracking the dialogue state is slot carryover, where a model makes a binary decision if a slot from the context is relevant to the current turn. Previous work on the slot carryover task used models that made independent decisions for each slot. A close analysis of the results show that this approach results in poor performance over longer context dialogues. In this paper, we propose to jointly model the slots. We propose two neural network architectures, one based on pointer networks that incorporate slot ordering information, and the other based on transformer networks that uses self attention mechanism to model the slot interdependencies. Our experiments on an internal dialogue benchmark dataset and on the public DSTC2 dataset demonstrate that our proposed models are able to resolve longer distance slot references and are able to achieve competitive performance.
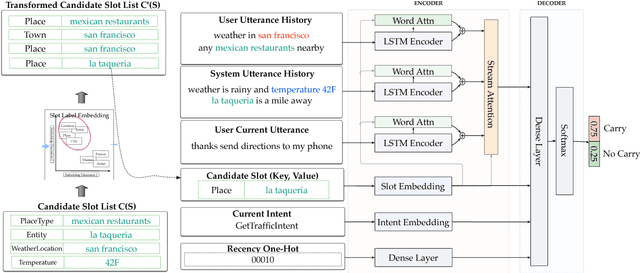
Cross-Lingual Approaches to Reference Resolution in Dialogue Systems
Nov 27, 2018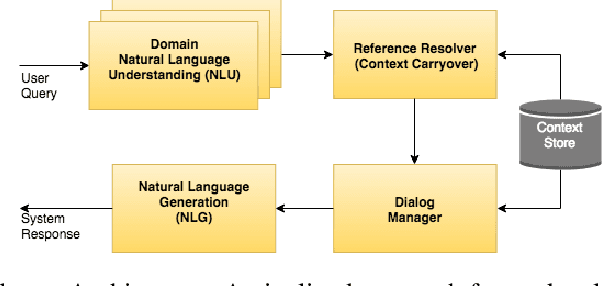

In the slot-filling paradigm, where a user can refer back to slots in the context during the conversation, the goal of the contextual understanding system is to resolve the referring expressions to the appropriate slots in the context. In this paper, we build on the context carryover system~\citep{Naik2018ContextualSC}, which provides a scalable multi-domain framework for resolving references. However, scaling this approach across languages is not a trivial task, due to the large demand on acquisition of annotated data in the target language. Our main focus is on cross-lingual methods for reference resolution as a way to alleviate the need for annotated data in the target language. In the cross-lingual setup, we assume there is access to annotated resources as well as a well trained model in the source language and little to no annotated data in the target language. In this paper, we explore three different approaches for cross-lingual transfer \textemdash~\ delexicalization as data augmentation, multilingual embeddings and machine translation. We compare these approaches both on a low resource setting as well as a large resource setting. Our experiments show that multilingual embeddings and delexicalization via data augmentation have a significant impact in the low resource setting, but the gains diminish as the amount of available data in the target language increases. Furthermore, when combined with machine translation we can get performance very close to actual live data in the target language, with only 25\% of the data projected into the target language.
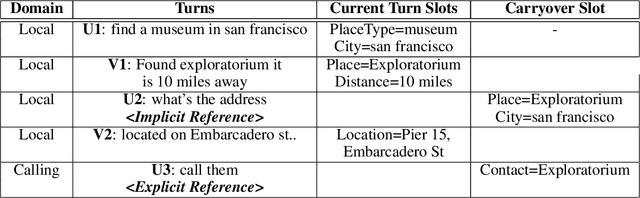
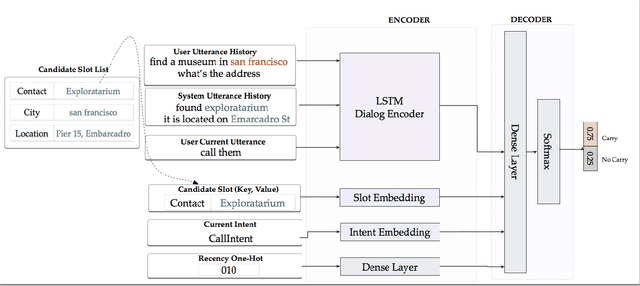
Contextual Slot Carryover for Disparate Schemas
Jun 05, 2018
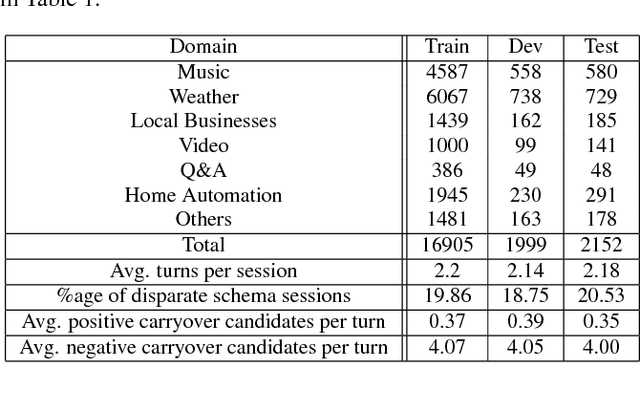
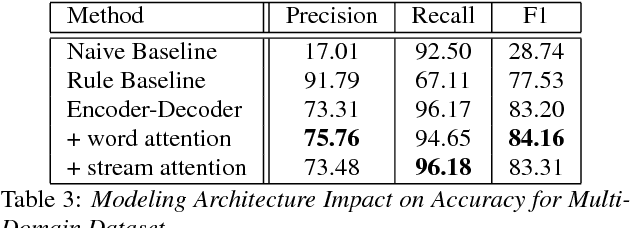
In the slot-filling paradigm, where a user can refer back to slots in the context during a conversation, the goal of the contextual understanding system is to resolve the referring expressions to the appropriate slots in the context. In large-scale multi-domain systems, this presents two challenges - scaling to a very large and potentially unbounded set of slot values, and dealing with diverse schemas. We present a neural network architecture that addresses the slot value scalability challenge by reformulating the contextual interpretation as a decision to carryover a slot from a set of possible candidates. To deal with heterogenous schemas, we introduce a simple data-driven method for trans- forming the candidate slots. Our experiments show that our approach can scale to multiple domains and provides competitive results over a strong baseline.