 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCross-Lingual Approaches to Reference Resolution in Dialogue Systems
Nov 27, 2018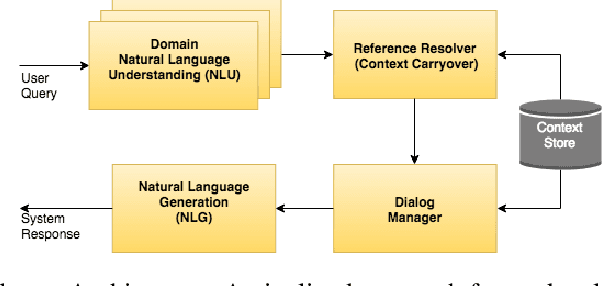
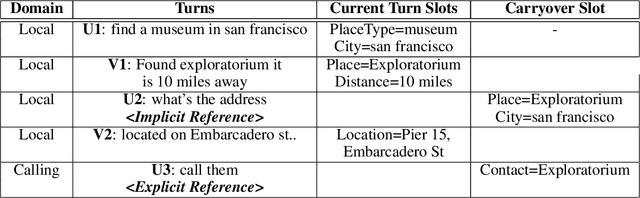

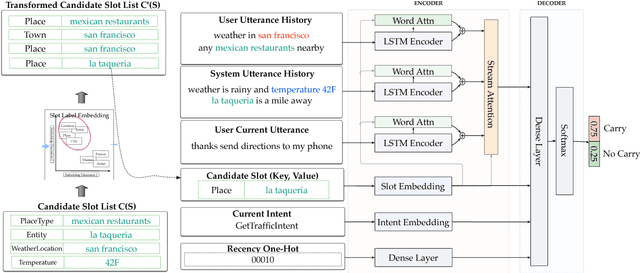
In the slot-filling paradigm, where a user can refer back to slots in the context during the conversation, the goal of the contextual understanding system is to resolve the referring expressions to the appropriate slots in the context. In this paper, we build on the context carryover system~\citep{Naik2018ContextualSC}, which provides a scalable multi-domain framework for resolving references. However, scaling this approach across languages is not a trivial task, due to the large demand on acquisition of annotated data in the target language. Our main focus is on cross-lingual methods for reference resolution as a way to alleviate the need for annotated data in the target language. In the cross-lingual setup, we assume there is access to annotated resources as well as a well trained model in the source language and little to no annotated data in the target language. In this paper, we explore three different approaches for cross-lingual transfer \textemdash~\ delexicalization as data augmentation, multilingual embeddings and machine translation. We compare these approaches both on a low resource setting as well as a large resource setting. Our experiments show that multilingual embeddings and delexicalization via data augmentation have a significant impact in the low resource setting, but the gains diminish as the amount of available data in the target language increases. Furthermore, when combined with machine translation we can get performance very close to actual live data in the target language, with only 25\% of the data projected into the target language.
Contextual Slot Carryover for Disparate Schemas
Jun 05, 2018
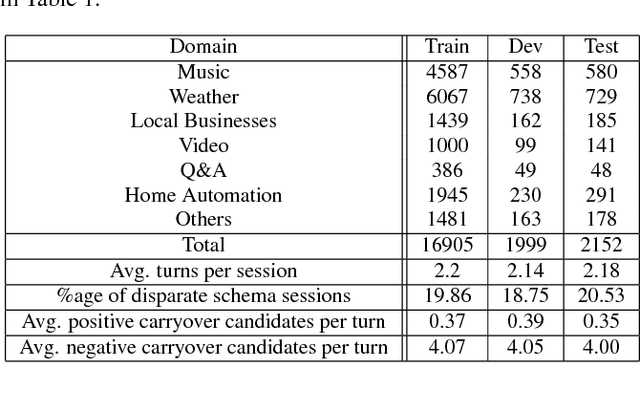
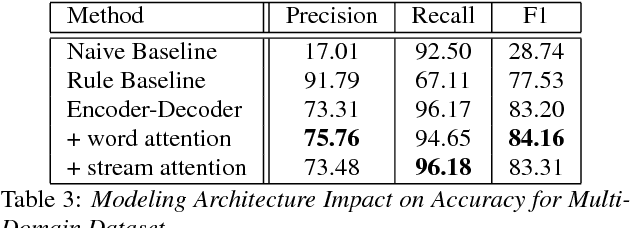
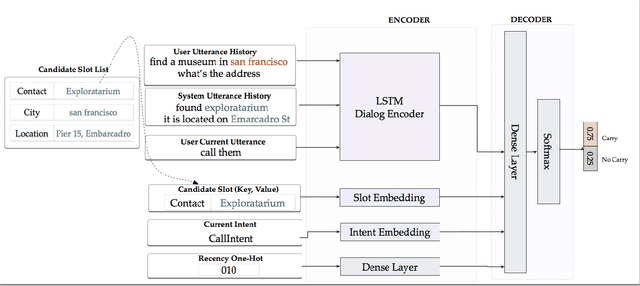
In the slot-filling paradigm, where a user can refer back to slots in the context during a conversation, the goal of the contextual understanding system is to resolve the referring expressions to the appropriate slots in the context. In large-scale multi-domain systems, this presents two challenges - scaling to a very large and potentially unbounded set of slot values, and dealing with diverse schemas. We present a neural network architecture that addresses the slot value scalability challenge by reformulating the contextual interpretation as a decision to carryover a slot from a set of possible candidates. To deal with heterogenous schemas, we introduce a simple data-driven method for trans- forming the candidate slots. Our experiments show that our approach can scale to multiple domains and provides competitive results over a strong baseline.
Tensor Completion Algorithms in Big Data Analytics
May 03, 2018


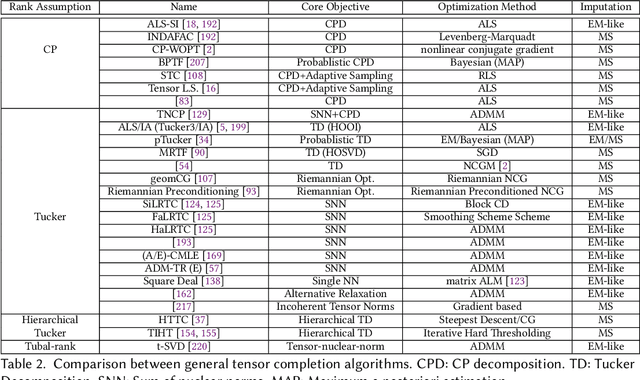
Tensor completion is a problem of filling the missing or unobserved entries of partially observed tensors. Due to the multidimensional character of tensors in describing complex datasets, tensor completion algorithms and their applications have received wide attention and achievement in areas like data mining, computer vision, signal processing, and neuroscience. In this survey, we provide a modern overview of recent advances in tensor completion algorithms from the perspective of big data analytics characterized by diverse variety, large volume, and high velocity. We characterize these advances from four perspectives: general tensor completion algorithms, tensor completion with auxiliary information (variety), scalable tensor completion algorithms (volume), and dynamic tensor completion algorithms (velocity). Further, we identify several tensor completion applications on real-world data-driven problems and present some common experimental frameworks popularized in the literature. Our goal is to summarize these popular methods and introduce them to researchers and practitioners for promoting future research and applications. We conclude with a discussion of key challenges and promising research directions in this community for future exploration.