 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalysis of Software Engineering for Agile Machine Learning Projects
Dec 16, 2019


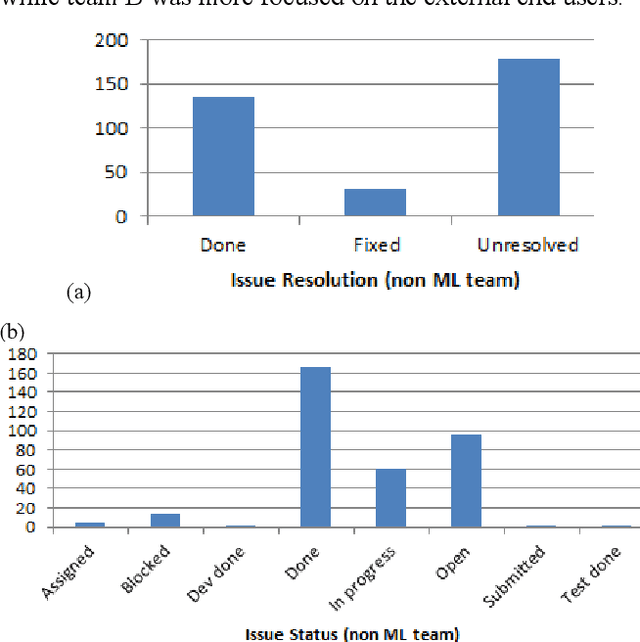
The number of machine learning, artificial intelligence or data science related software engineering projects using Agile methodology is increasing. However, there are very few studies on how such projects work in practice. In this paper, we analyze project issues tracking data taken from Scrum (a popular tool for Agile) for several machine learning projects. We compare this data with corresponding data from non-machine learning projects, in an attempt to analyze how machine learning projects are executed differently from normal software engineering projects. On analysis, we find that machine learning project issues use different kinds of words to describe issues, have higher number of exploratory or research oriented tasks as compared to implementation tasks, and have a higher number of issues in the product backlog after each sprint, denoting that it is more difficult to estimate the duration of machine learning project related tasks in advance. After analyzing this data, we propose a few ways in which Agile machine learning projects can be better logged and executed, given their differences with normal software engineering projects.
Evaluating Usage of Images for App Classification
Dec 16, 2019
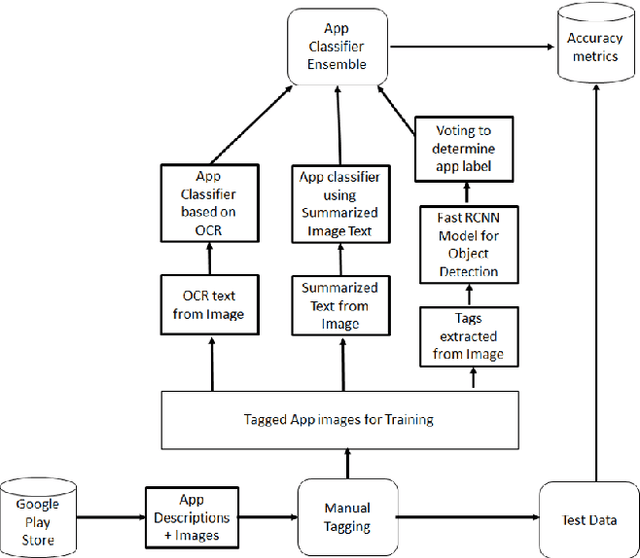
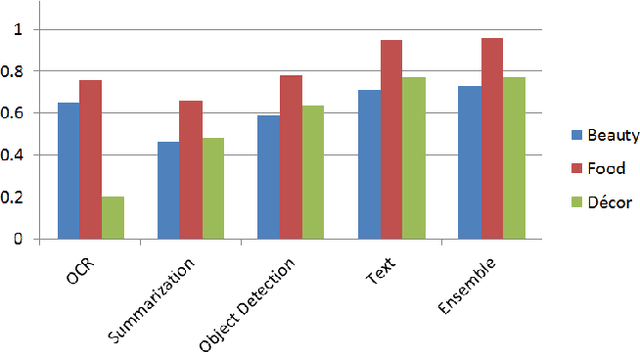
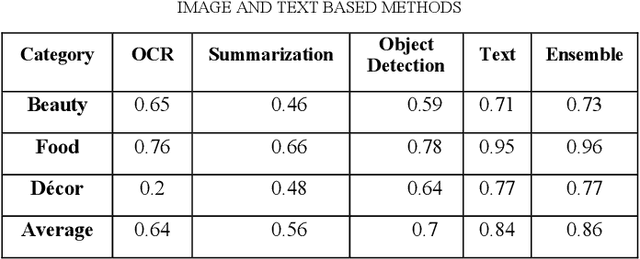
App classification is useful in a number of applications such as adding apps to an app store or building a user model based on the installed apps. Presently there are a number of existing methods to classify apps based on a given taxonomy on the basis of their text metadata. However, text based methods for app classification may not work in all cases, such as when the text descriptions are in a different language, or missing, or inadequate to classify the app. One solution in such cases is to utilize the app images to supplement the text description. In this paper, we evaluate a number of approaches in which app images can be used to classify the apps. In one approach, we use Optical character recognition (OCR) to extract text from images, which is then used to supplement the text description of the app. In another, we use pic2vec to convert the app images into vectors, then train an SVM to classify the vectors to the correct app label. In another, we use the captionbot.ai tool to generate natural language descriptions from the app images. Finally, we use a method to detect and label objects in the app images and use a voting technique to determine the category of the app based on all the images. We compare the performance of our image-based techniques to classify a number of apps in our dataset. We use a text based SVM app classifier as our base and obtained an improved classification accuracy of 96% for some classes when app images are added.
IoT2Vec: Identification of Similar IoT Devices via Activity Footprints
May 21, 2018
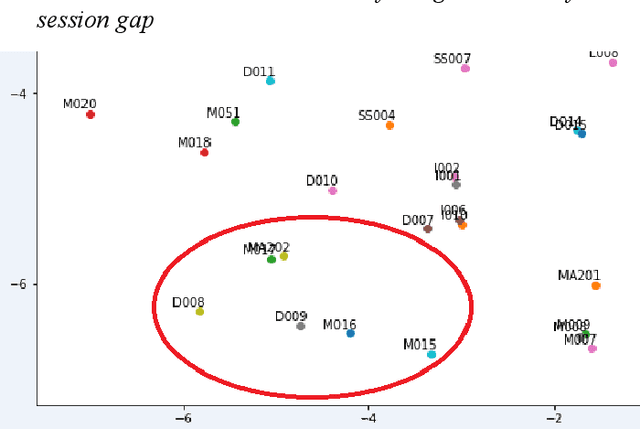

We consider a smart home or smart office environment with a number of IoT devices connected and passing data between one another. The footprints of the data transferred can provide valuable information about the devices, which can be used to (a) identify the IoT devices and (b) in case of failure, to identify the correct replacements for these devices. In this paper, we generate the embeddings for IoT devices in a smart home using Word2Vec, and explore the possibility of having a similar concept for IoT devices, aka IoT2Vec. These embeddings can be used in a number of ways, such as to find similar devices in an IoT device store, or as a signature of each type of IoT device. We show results of a feasibility study on the CASAS dataset of IoT device activity logs, using our method to identify the patterns in embeddings of various types of IoT devices in a household.