 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Learning for Words and Entities
Jun 12, 2019
This thesis presents new methods for unsupervised learning of distributed representations of words and entities from text and knowledge bases. The first algorithm presented in the thesis is a multi-view algorithm for learning representations of words called Multiview Latent Semantic Analysis (MVLSA). By incorporating up to 46 different types of co-occurrence statistics for the same vocabulary of english words, I show that MVLSA outperforms other state-of-the-art word embedding models. Next, I focus on learning entity representations for search and recommendation and present the second method of this thesis, Neural Variational Set Expansion (NVSE). NVSE is also an unsupervised learning method, but it is based on the Variational Autoencoder framework. Evaluations with human annotators show that NVSE can facilitate better search and recommendation of information gathered from noisy, automatic annotation of unstructured natural language corpora. Finally, I move from unstructured data and focus on structured knowledge graphs. I present novel approaches for learning embeddings of vertices and edges in a knowledge graph that obey logical constraints.
Improving Long Distance Slot Carryover in Spoken Dialogue Systems
Jun 04, 2019
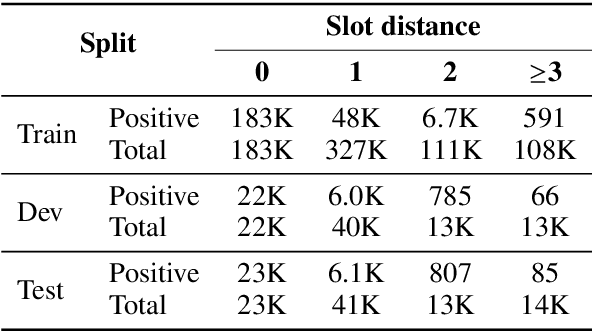

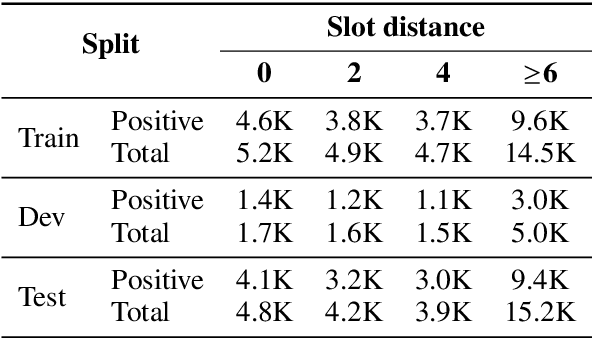
Tracking the state of the conversation is a central component in task-oriented spoken dialogue systems. One such approach for tracking the dialogue state is slot carryover, where a model makes a binary decision if a slot from the context is relevant to the current turn. Previous work on the slot carryover task used models that made independent decisions for each slot. A close analysis of the results show that this approach results in poor performance over longer context dialogues. In this paper, we propose to jointly model the slots. We propose two neural network architectures, one based on pointer networks that incorporate slot ordering information, and the other based on transformer networks that uses self attention mechanism to model the slot interdependencies. Our experiments on an internal dialogue benchmark dataset and on the public DSTC2 dataset demonstrate that our proposed models are able to resolve longer distance slot references and are able to achieve competitive performance.
A dataset for resolving referring expressions in spoken dialogue via contextual query rewrites (CQR)
Apr 01, 2019
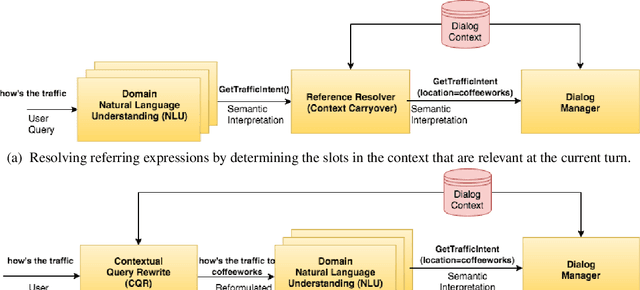
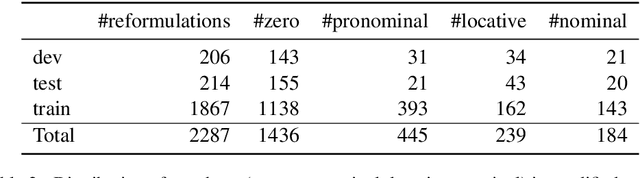
We present Contextual Query Rewrite (CQR) a dataset for multi-domain task-oriented spoken dialogue systems that is an extension of the Stanford dialog corpus (Eric et al., 2017a). While previous approaches have addressed the issue of diverse schemas by learning candidate transformations (Naik et al., 2018), we instead model the reference resolution task as a user query reformulation task, where the dialog state is serialized into a natural language query that can be executed by the downstream spoken language understanding system. In this paper, we describe our methodology for creating the query reformulation extension to the dialog corpus, and present an initial set of experiments to establish a baseline for the CQR task. We have released the corpus to the public [1] to support further research in this area.
Scaling Multi-Domain Dialogue State Tracking via Query Reformulation
Mar 29, 2019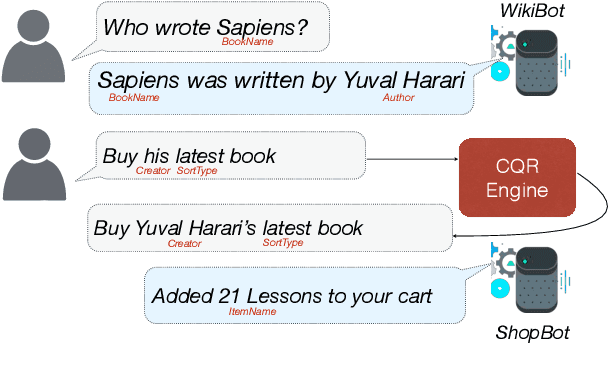
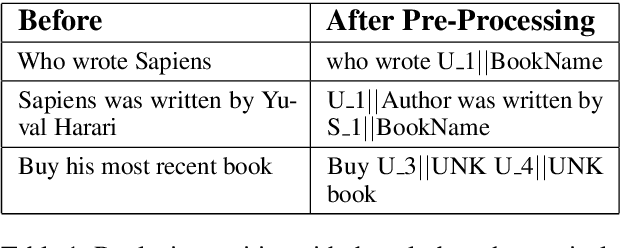

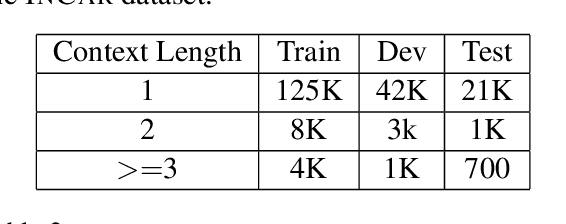
We present a novel approach to dialogue state tracking and referring expression resolution tasks. Successful contextual understanding of multi-turn spoken dialogues requires resolving referring expressions across turns and tracking the entities relevant to the conversation across turns. Tracking conversational state is particularly challenging in a multi-domain scenario when there exist multiple spoken language understanding (SLU) sub-systems, and each SLU sub-system operates on its domain-specific meaning representation. While previous approaches have addressed the disparate schema issue by learning candidate transformations of the meaning representation, in this paper, we instead model the reference resolution as a dialogue context-aware user query reformulation task -- the dialog state is serialized to a sequence of natural language tokens representing the conversation. We develop our model for query reformulation using a pointer-generator network and a novel multi-task learning setup. In our experiments, we show a significant improvement in absolute F1 on an internal as well as a, soon to be released, public benchmark respectively.
Problems With Evaluation of Word Embeddings Using Word Similarity Tasks
Jun 22, 2016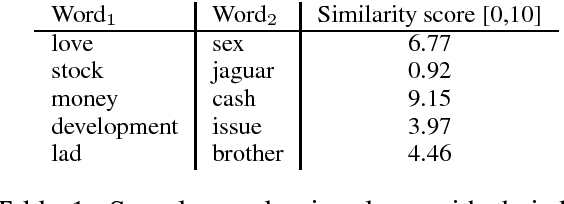
Lacking standardized extrinsic evaluation methods for vector representations of words, the NLP community has relied heavily on word similarity tasks as a proxy for intrinsic evaluation of word vectors. Word similarity evaluation, which correlates the distance between vectors and human judgments of semantic similarity is attractive, because it is computationally inexpensive and fast. In this paper we present several problems associated with the evaluation of word vectors on word similarity datasets, and summarize existing solutions. Our study suggests that the use of word similarity tasks for evaluation of word vectors is not sustainable and calls for further research on evaluation methods.
A Critical Examination of RESCAL for Completion of Knowledge Bases with Transitive Relations
May 16, 2016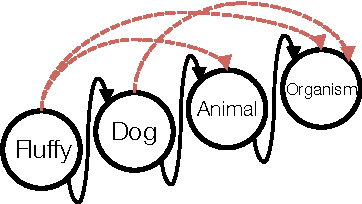
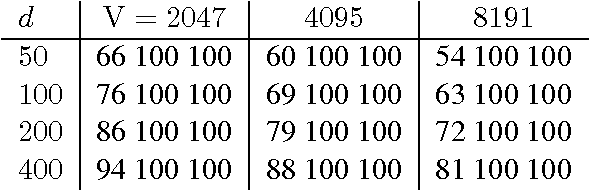
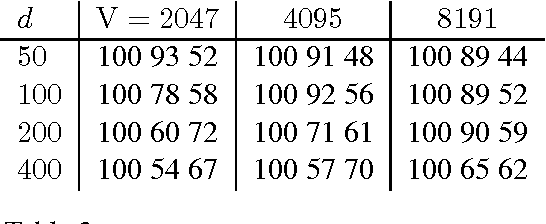
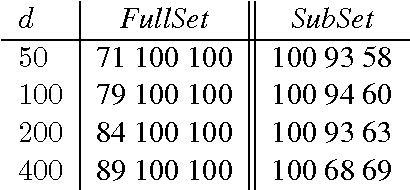
Link prediction in large knowledge graphs has received a lot of attention recently because of its importance for inferring missing relations and for completing and improving noisily extracted knowledge graphs. Over the years a number of machine learning researchers have presented various models for predicting the presence of missing relations in a knowledge base. Although all the previous methods are presented with empirical results that show high performance on select datasets, there is almost no previous work on understanding the connection between properties of a knowledge base and the performance of a model. In this paper we analyze the RESCAL method and prove that it can not encode asymmetric transitive relations in knowledge bases.
Sublinear Partition Estimation
Aug 07, 2015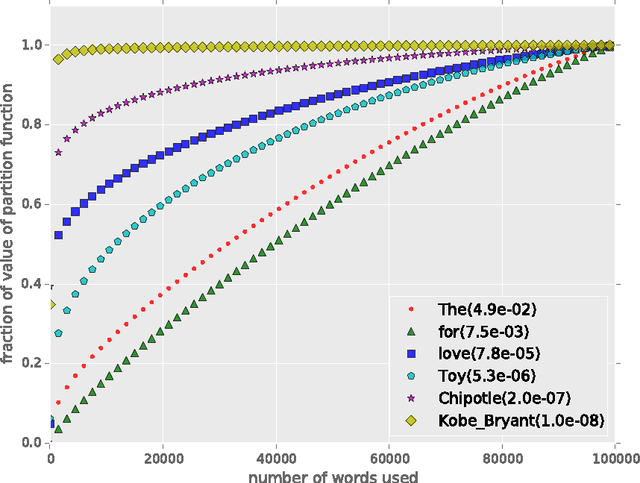
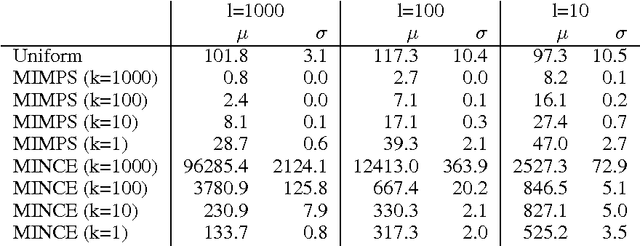
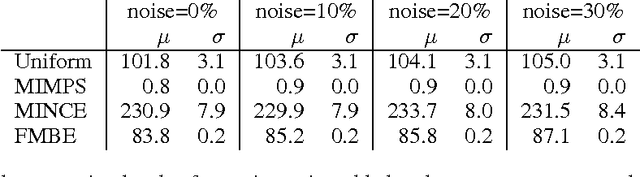

The output scores of a neural network classifier are converted to probabilities via normalizing over the scores of all competing categories. Computing this partition function, $Z$, is then linear in the number of categories, which is problematic as real-world problem sets continue to grow in categorical types, such as in visual object recognition or discriminative language modeling. We propose three approaches for sublinear estimation of the partition function, based on approximate nearest neighbor search and kernel feature maps and compare the performance of the proposed approaches empirically.