 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASSIVE Multilingual Abstract Meaning Representation: A Dataset and Baselines for Hallucination Detection
May 29, 2024
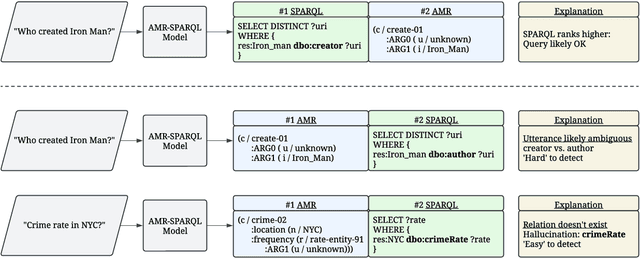
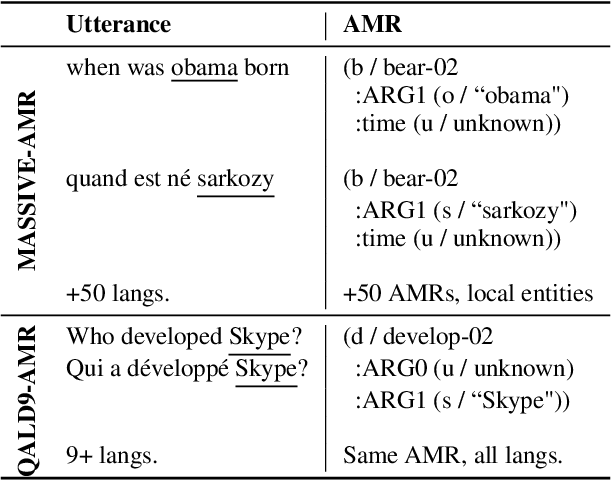

Abstract Meaning Representation (AMR) is a semantic formalism that captures the core meaning of an utterance. There has been substantial work developing AMR corpora in English and more recently across languages, though the limited size of existing datasets and the cost of collecting more annotations are prohibitive. With both engineering and scientific questions in mind, we introduce MASSIVE-AMR, a dataset with more than 84,000 text-to-graph annotations, currently the largest and most diverse of its kind: AMR graphs for 1,685 information-seeking utterances mapped to 50+ typologically diverse languages. We describe how we built our resource and its unique features before reporting on experiments using large language models for multilingual AMR and SPARQL parsing as well as applying AMRs for hallucination detection in the context of knowledge base question answering, with results shedding light on persistent issues using LLMs for structured parsing.
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?
Jun 06, 2023Annotating cross-document event coreference links is a time-consuming and cognitively demanding task that can compromise annotation quality and efficiency. To address this, we propose a model-in-the-loop annotation approach for event coreference resolution, where a machine learning model suggests likely corefering event pairs only. We evaluate the effectiveness of this approach by first simulating the annotation process and then, using a novel annotator-centric Recall-Annotation effort trade-off metric, we compare the results of various underlying models and datasets. We finally present a method for obtaining 97\% recall while substantially reducing the workload required by a fully manual annotation process. Code and data can be found at https://github.com/ahmeshaf/model_in_coref
Causal schema induction for knowledge discovery
Mar 27, 2023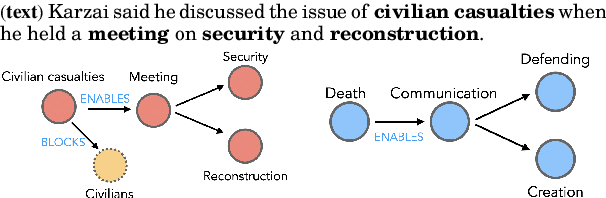


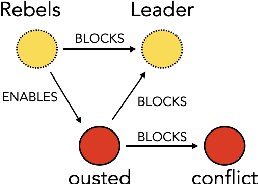
Making sense of familiar yet new situations typically involves making generalizations about causal schemas, stories that help humans reason about event sequences. Reasoning about events includes identifying cause and effect relations shared across event instances, a process we refer to as causal schema induction. Statistical schema induction systems may leverage structural knowledge encoded in discourse or the causal graphs associated with event meaning, however resources to study such causal structure are few in number and limited in size. In this work, we investigate how to apply schema induction models to the task of knowledge discovery for enhanced search of English-language news texts. To tackle the problem of data scarcity, we present Torquestra, a manually curated dataset of text-graph-schema units integrating temporal, event, and causal structures. We benchmark our dataset on three knowledge discovery tasks, building and evaluating models for each. Results show that systems that harness causal structure are effective at identifying texts sharing similar causal meaning components rather than relying on lexical cues alone. We make our dataset and models available for research purposes.
A dataset for resolving referring expressions in spoken dialogue via contextual query rewrites (CQR)
Apr 01, 2019
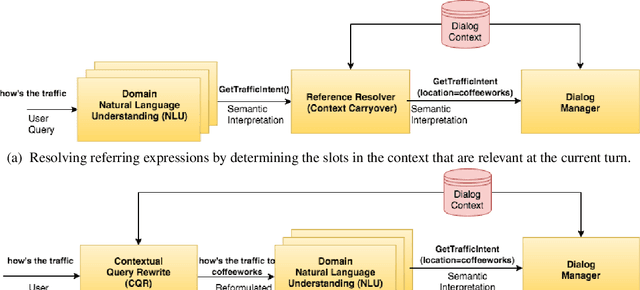
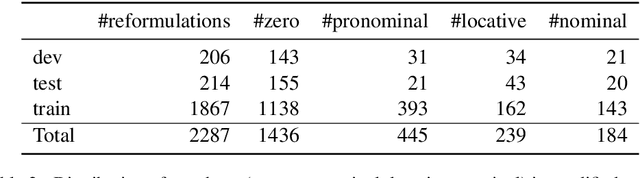
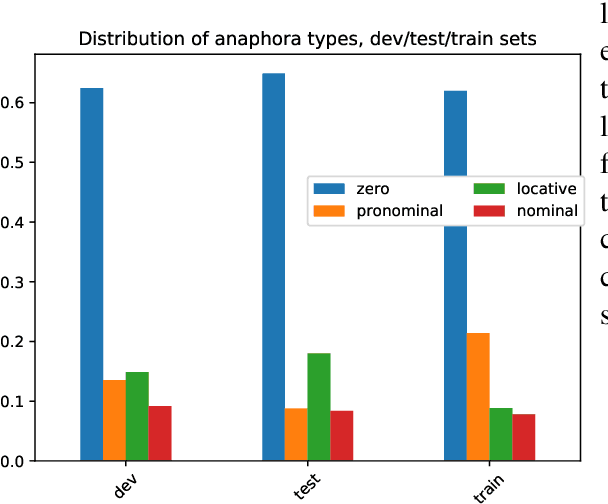
We present Contextual Query Rewrite (CQR) a dataset for multi-domain task-oriented spoken dialogue systems that is an extension of the Stanford dialog corpus (Eric et al., 2017a). While previous approaches have addressed the issue of diverse schemas by learning candidate transformations (Naik et al., 2018), we instead model the reference resolution task as a user query reformulation task, where the dialog state is serialized into a natural language query that can be executed by the downstream spoken language understanding system. In this paper, we describe our methodology for creating the query reformulation extension to the dialog corpus, and present an initial set of experiments to establish a baseline for the CQR task. We have released the corpus to the public [1] to support further research in this area.