 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Apr 13, 2024



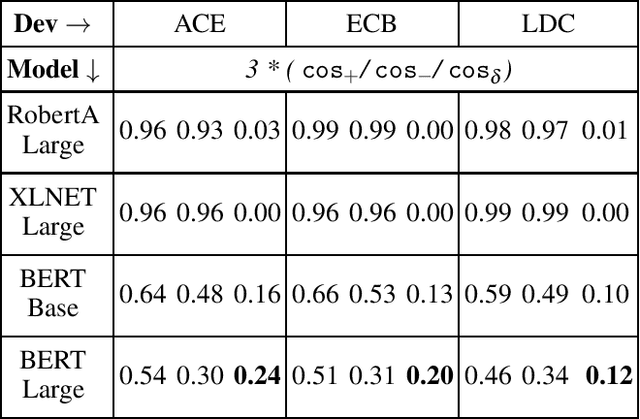
Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
CAMRA: Copilot for AMR Annotation
Nov 18, 2023


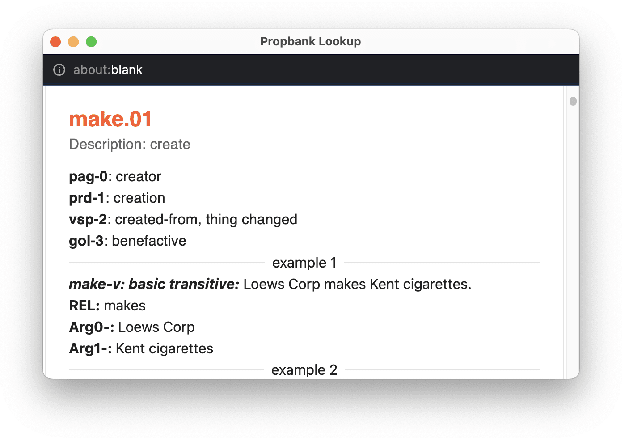
In this paper, we introduce CAMRA (Copilot for AMR Annotatations), a cutting-edge web-based tool designed for constructing Abstract Meaning Representation (AMR) from natural language text. CAMRA offers a novel approach to deep lexical semantics annotation such as AMR, treating AMR annotation akin to coding in programming languages. Leveraging the familiarity of programming paradigms, CAMRA encompasses all essential features of existing AMR editors, including example lookup, while going a step further by integrating Propbank roleset lookup as an autocomplete feature within the tool. Notably, CAMRA incorporates AMR parser models as coding co-pilots, greatly enhancing the efficiency and accuracy of AMR annotators. To demonstrate the tool's capabilities, we provide a live demo accessible at: https://camra.colorado.edu
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?
Jun 06, 2023Annotating cross-document event coreference links is a time-consuming and cognitively demanding task that can compromise annotation quality and efficiency. To address this, we propose a model-in-the-loop annotation approach for event coreference resolution, where a machine learning model suggests likely corefering event pairs only. We evaluate the effectiveness of this approach by first simulating the annotation process and then, using a novel annotator-centric Recall-Annotation effort trade-off metric, we compare the results of various underlying models and datasets. We finally present a method for obtaining 97\% recall while substantially reducing the workload required by a fully manual annotation process. Code and data can be found at https://github.com/ahmeshaf/model_in_coref
$2 * n$ is better than $n^2$: Decomposing Event Coreference Resolution into Two Tractable Problems
May 09, 2023



Event Coreference Resolution (ECR) is the task of linking mentions of the same event either within or across documents. Most mention pairs are not coreferent, yet many that are coreferent can be identified through simple techniques such as lemma matching of the event triggers or the sentences in which they appear. Existing methods for training coreference systems sample from a largely skewed distribution, making it difficult for the algorithm to learn coreference beyond surface matching. Additionally, these methods are intractable because of the quadratic operations needed. To address these challenges, we break the problem of ECR into two parts: a) a heuristic to efficiently filter out a large number of non-coreferent pairs, and b) a training approach on a balanced set of coreferent and non-coreferent mention pairs. By following this approach, we show that we get comparable results to the state of the art on two popular ECR datasets while significantly reducing compute requirements. We also analyze the mention pairs that are "hard" to accurately classify as coreferent or non-coreferent. Code at https://github.com/ahmeshaf/lemma_ce_coref
Within-Document Event Coreference with BERT-Based Contextualized Representations
Feb 15, 2021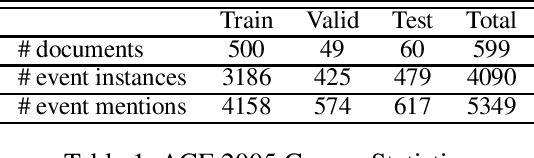
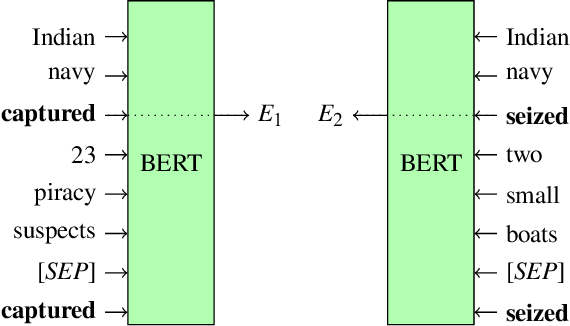
Event coreference continues to be a challenging problem in information extraction. With the absence of any external knowledge bases for events, coreference becomes a clustering task that relies on effective representations of the context in which event mentions appear. Recent advances in contextualized language representations have proven successful in many tasks, however, their use in event linking been limited. Here we present a three part approach that (1) uses representations derived from a pretrained BERT model to (2) train a neural classifier to (3) drive a simple clustering algorithm to create coreference chains. We achieve state of the art results with this model on two standard datasets for within-document event coreference task and establish a new standard on a third newer dataset.
From Algebraic Word Problem to Program: A Formalized Approach
Mar 11, 2020



In this paper, we propose a pipeline to convert grade school level algebraic word problem into program of a formal languageA-IMP. Using natural language processing tools, we break the problem into sentence fragments which can then be reduced to functions. The functions are categorized by the head verb of the sentence and its structure, as defined by (Hosseini et al., 2014). We define the function signature and extract its arguments from the text using dependency parsing. We have a working implementation of the entire pipeline which can be found on our github repository.