 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Talk Moves Analysis in Mathematics Tutoring through Classroom Teaching Discourse
Dec 18, 2024Human tutoring interventions play a crucial role in supporting student learning, improving academic performance, and promoting personal growth. This paper focuses on analyzing mathematics tutoring discourse using talk moves - a framework of dialogue acts grounded in Accountable Talk theory. However, scaling the collection, annotation, and analysis of extensive tutoring dialogues to develop machine learning models is a challenging and resource-intensive task. To address this, we present SAGA22, a compact dataset, and explore various modeling strategies, including dialogue context, speaker information, pretraining datasets, and further fine-tuning. By leveraging existing datasets and models designed for classroom teaching, our results demonstrate that supplementary pretraining on classroom data enhances model performance in tutoring settings, particularly when incorporating longer context and speaker information. Additionally, we conduct extensive ablation studies to underscore the challenges in talk move modeling.
Adapting Abstract Meaning Representation Parsing to the Clinical Narrative -- the SPRING THYME parser
May 15, 2024This paper is dedicated to the design and evaluation of the first AMR parser tailored for clinical notes. Our objective was to facilitate the precise transformation of the clinical notes into structured AMR expressions, thereby enhancing the interpretability and usability of clinical text data at scale. Leveraging the colon cancer dataset from the Temporal Histories of Your Medical Events (THYME) corpus, we adapted a state-of-the-art AMR parser utilizing continuous training. Our approach incorporates data augmentation techniques to enhance the accuracy of AMR structure predictions. Notably, through this learning strategy, our parser achieved an impressive F1 score of 88% on the THYME corpus's colon cancer dataset. Moreover, our research delved into the efficacy of data required for domain adaptation within the realm of clinical notes, presenting domain adaptation data requirements for AMR parsing. This exploration not only underscores the parser's robust performance but also highlights its potential in facilitating a deeper understanding of clinical narratives through structured semantic representations.
Multimodal Cross-Document Event Coreference Resolution Using Linear Semantic Transfer and Mixed-Modality Ensembles
Apr 13, 2024



Event coreference resolution (ECR) is the task of determining whether distinct mentions of events within a multi-document corpus are actually linked to the same underlying occurrence. Images of the events can help facilitate resolution when language is ambiguous. Here, we propose a multimodal cross-document event coreference resolution method that integrates visual and textual cues with a simple linear map between vision and language models. As existing ECR benchmark datasets rarely provide images for all event mentions, we augment the popular ECB+ dataset with event-centric images scraped from the internet and generated using image diffusion models. We establish three methods that incorporate images and text for coreference: 1) a standard fused model with finetuning, 2) a novel linear mapping method without finetuning and 3) an ensembling approach based on splitting mention pairs by semantic and discourse-level difficulty. We evaluate on 2 datasets: the augmented ECB+, and AIDA Phase 1. Our ensemble systems using cross-modal linear mapping establish an upper limit (91.9 CoNLL F1) on ECB+ ECR performance given the preprocessing assumptions used, and establish a novel baseline on AIDA Phase 1. Our results demonstrate the utility of multimodal information in ECR for certain challenging coreference problems, and highlight a need for more multimodal resources in the coreference resolution space.
CAMRA: Copilot for AMR Annotation
Nov 18, 2023


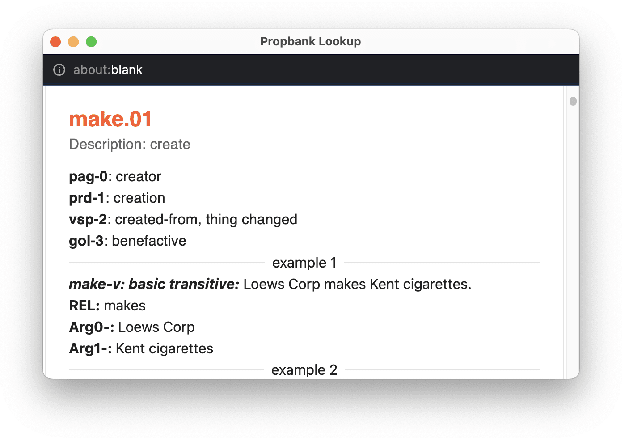
In this paper, we introduce CAMRA (Copilot for AMR Annotatations), a cutting-edge web-based tool designed for constructing Abstract Meaning Representation (AMR) from natural language text. CAMRA offers a novel approach to deep lexical semantics annotation such as AMR, treating AMR annotation akin to coding in programming languages. Leveraging the familiarity of programming paradigms, CAMRA encompasses all essential features of existing AMR editors, including example lookup, while going a step further by integrating Propbank roleset lookup as an autocomplete feature within the tool. Notably, CAMRA incorporates AMR parser models as coding co-pilots, greatly enhancing the efficiency and accuracy of AMR annotators. To demonstrate the tool's capabilities, we provide a live demo accessible at: https://camra.colorado.edu
How Good is the Model in Model-in-the-loop Event Coreference Resolution Annotation?
Jun 06, 2023Annotating cross-document event coreference links is a time-consuming and cognitively demanding task that can compromise annotation quality and efficiency. To address this, we propose a model-in-the-loop annotation approach for event coreference resolution, where a machine learning model suggests likely corefering event pairs only. We evaluate the effectiveness of this approach by first simulating the annotation process and then, using a novel annotator-centric Recall-Annotation effort trade-off metric, we compare the results of various underlying models and datasets. We finally present a method for obtaining 97\% recall while substantially reducing the workload required by a fully manual annotation process. Code and data can be found at https://github.com/ahmeshaf/model_in_coref
$2 * n$ is better than $n^2$: Decomposing Event Coreference Resolution into Two Tractable Problems
May 09, 2023



Event Coreference Resolution (ECR) is the task of linking mentions of the same event either within or across documents. Most mention pairs are not coreferent, yet many that are coreferent can be identified through simple techniques such as lemma matching of the event triggers or the sentences in which they appear. Existing methods for training coreference systems sample from a largely skewed distribution, making it difficult for the algorithm to learn coreference beyond surface matching. Additionally, these methods are intractable because of the quadratic operations needed. To address these challenges, we break the problem of ECR into two parts: a) a heuristic to efficiently filter out a large number of non-coreferent pairs, and b) a training approach on a balanced set of coreferent and non-coreferent mention pairs. By following this approach, we show that we get comparable results to the state of the art on two popular ECR datasets while significantly reducing compute requirements. We also analyze the mention pairs that are "hard" to accurately classify as coreferent or non-coreferent. Code at https://github.com/ahmeshaf/lemma_ce_coref
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023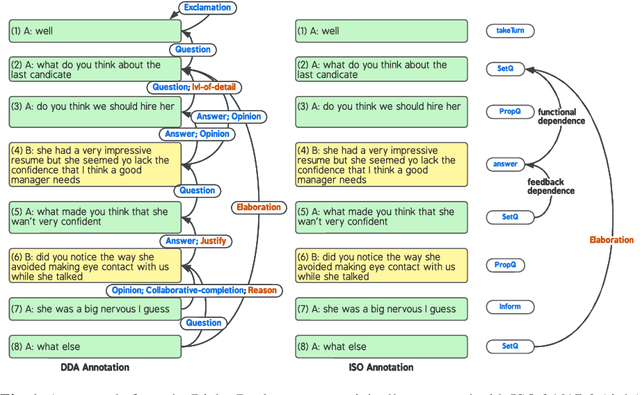

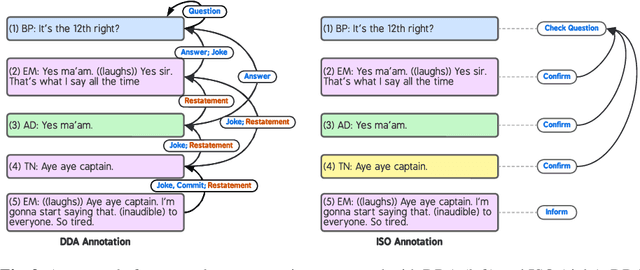
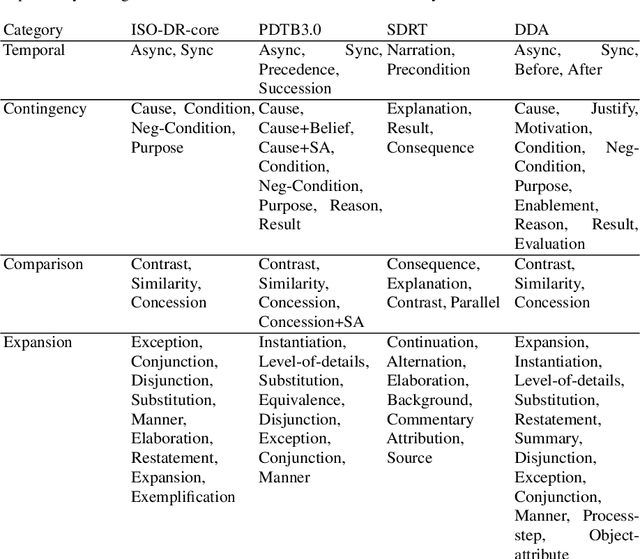
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
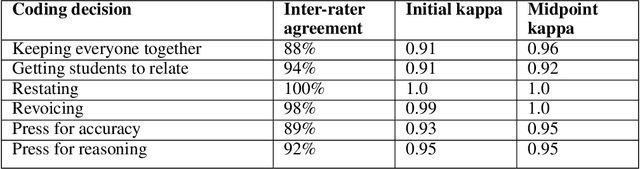
The TalkMoves Dataset: K-12 Mathematics Lesson Transcripts Annotated for Teacher and Student Discursive Moves
Apr 06, 2022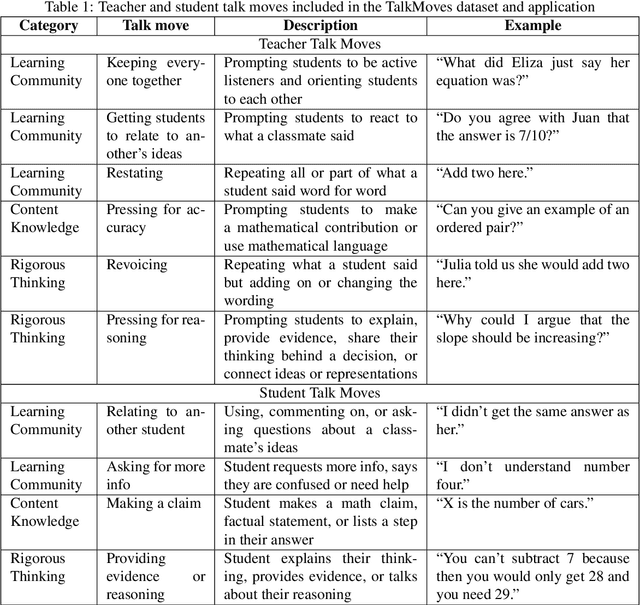
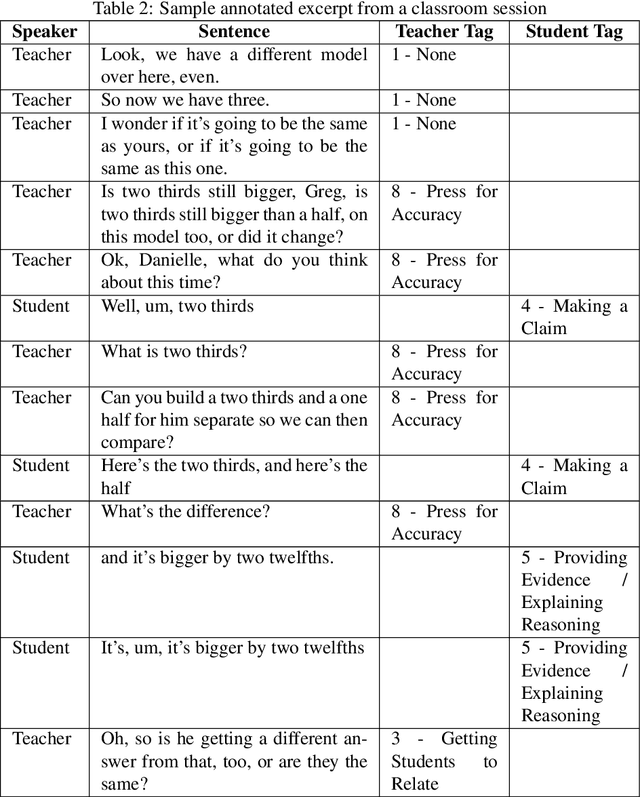
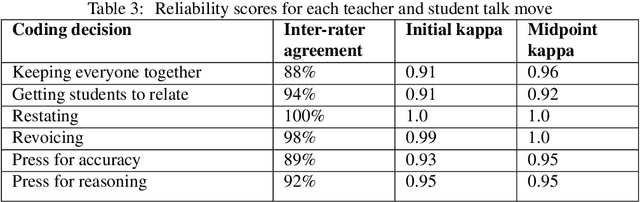
Transcripts of teaching episodes can be effective tools to understand discourse patterns in classroom instruction. According to most educational experts, sustained classroom discourse is a critical component of equitable, engaging, and rich learning environments for students. This paper describes the TalkMoves dataset, composed of 567 human-annotated K-12 mathematics lesson transcripts (including entire lessons or portions of lessons) derived from video recordings. The set of transcripts primarily includes in-person lessons with whole-class discussions and/or small group work, as well as some online lessons. All of the transcripts are human-transcribed, segmented by the speaker (teacher or student), and annotated at the sentence level for ten discursive moves based on accountable talk theory. In addition, the transcripts include utterance-level information in the form of dialogue act labels based on the Switchboard Dialog Act Corpus. The dataset can be used by educators, policymakers, and researchers to understand the nature of teacher and student discourse in K-12 math classrooms. Portions of this dataset have been used to develop the TalkMoves application, which provides teachers with automated, immediate, and actionable feedback about their mathematics instruction.
Using Transformers to Provide Teachers with Personalized Feedback on their Classroom Discourse: The TalkMoves Application
Apr 29, 2021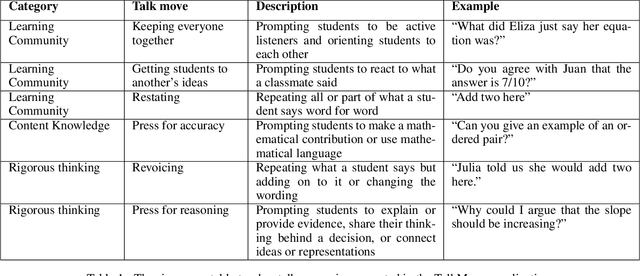

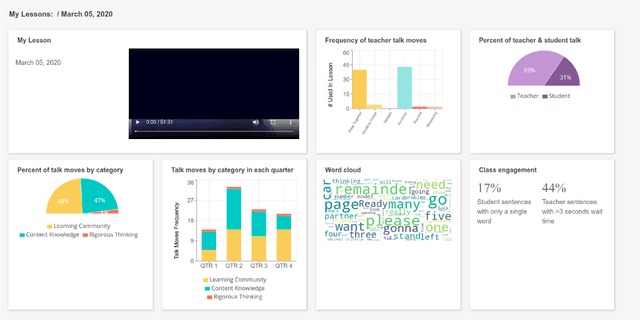
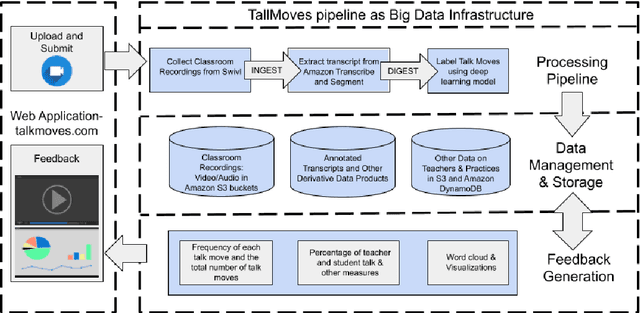
TalkMoves is an innovative application designed to support K-12 mathematics teachers to reflect on, and continuously improve their instructional practices. This application combines state-of-the-art natural language processing capabilities with automated speech recognition to automatically analyze classroom recordings and provide teachers with personalized feedback on their use of specific types of discourse aimed at broadening and deepening classroom conversations about mathematics. These specific discourse strategies are referred to as "talk moves" within the mathematics education community and prior research has documented the ways in which systematic use of these discourse strategies can positively impact student engagement and learning. In this article, we describe the TalkMoves application's cloud-based infrastructure for managing and processing classroom recordings, and its interface for providing teachers with feedback on their use of talk moves during individual teaching episodes. We present the series of model architectures we developed, and the studies we conducted, to develop our best-performing, transformer-based model (F1 = 79.3%). We also discuss several technical challenges that need to be addressed when working with real-world speech and language data from noisy K-12 classrooms.
Within-Document Event Coreference with BERT-Based Contextualized Representations
Feb 15, 2021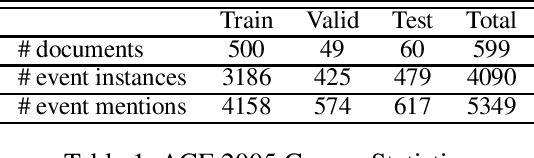
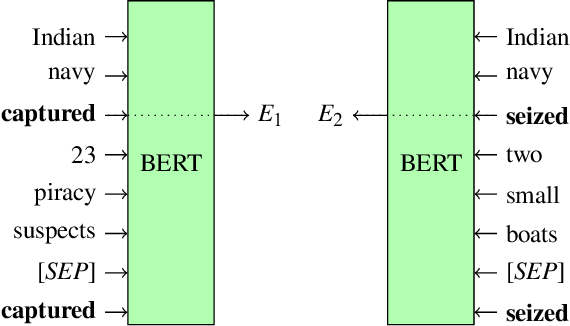
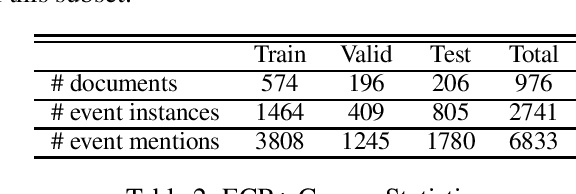
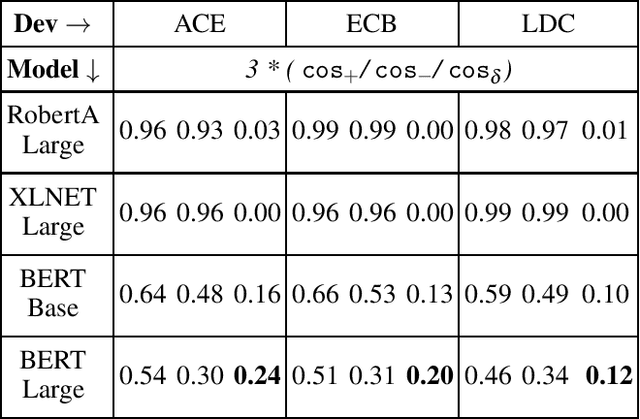
Event coreference continues to be a challenging problem in information extraction. With the absence of any external knowledge bases for events, coreference becomes a clustering task that relies on effective representations of the context in which event mentions appear. Recent advances in contextualized language representations have proven successful in many tasks, however, their use in event linking been limited. Here we present a three part approach that (1) uses representations derived from a pretrained BERT model to (2) train a neural classifier to (3) drive a simple clustering algorithm to create coreference chains. We achieve state of the art results with this model on two standard datasets for within-document event coreference task and establish a new standard on a third newer dataset.