 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Power of the Noisy Channel: Unsupervised End-to-End Task-Oriented Dialogue with LLMs
Apr 23, 2024



Training task-oriented dialogue systems typically requires turn-level annotations for interacting with their APIs: e.g. a dialogue state and the system actions taken at each step. These annotations can be costly to produce, error-prone, and require both domain and annotation expertise. With advances in LLMs, we hypothesize unlabelled data and a schema definition are sufficient for building a working task-oriented dialogue system, completely unsupervised. Using only (1) a well-defined API schema (2) a set of unlabelled dialogues between a user and agent, we develop a novel approach for inferring turn-level annotations as latent variables using a noisy channel model. We iteratively improve these pseudo-labels with expectation-maximization (EM), and use the inferred labels to train an end-to-end dialogue agent. Evaluating our approach on the MultiWOZ benchmark, our method more than doubles the dialogue success rate of a strong GPT-3.5 baseline.
Diverse Retrieval-Augmented In-Context Learning for Dialogue State Tracking
Jul 04, 2023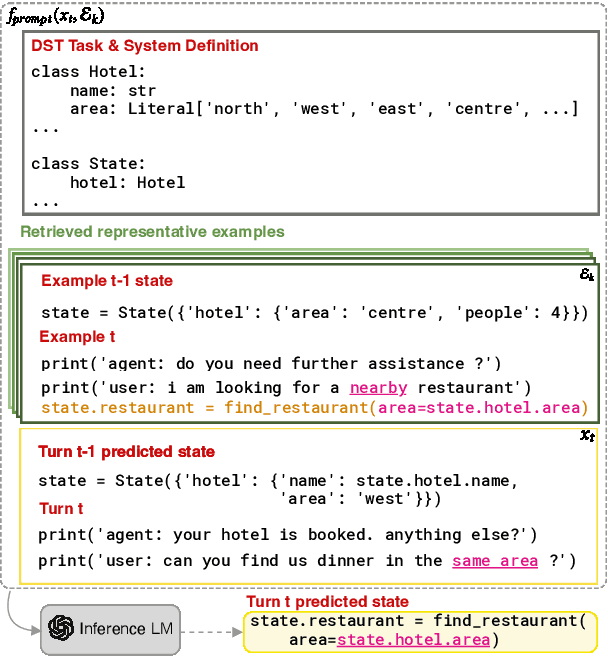

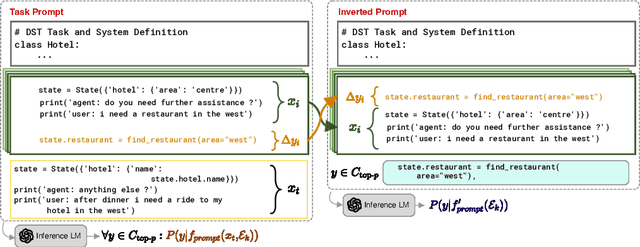
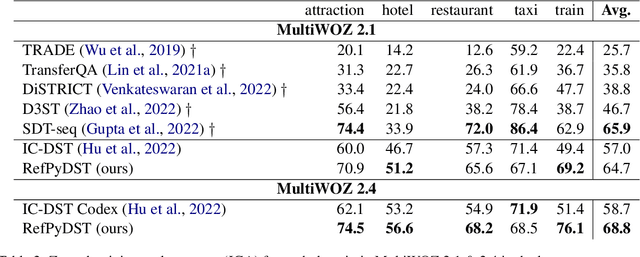
There has been significant interest in zero and few-shot learning for dialogue state tracking (DST) due to the high cost of collecting and annotating task-oriented dialogues. Recent work has demonstrated that in-context learning requires very little data and zero parameter updates, and even outperforms trained methods in the few-shot setting (Hu et al. 2022). We propose RefPyDST, which advances the state of the art with three advancements to in-context learning for DST. First, we formulate DST as a Python programming task, explicitly modeling language coreference as variable reference in Python. Second, since in-context learning depends highly on the context examples, we propose a method to retrieve a diverse set of relevant examples to improve performance. Finally, we introduce a novel re-weighting method during decoding that takes into account probabilities of competing surface forms, and produces a more accurate dialogue state prediction. We evaluate our approach using MultiWOZ and achieve state-of-the-art multi-domain joint-goal accuracy in zero and few-shot settings.
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023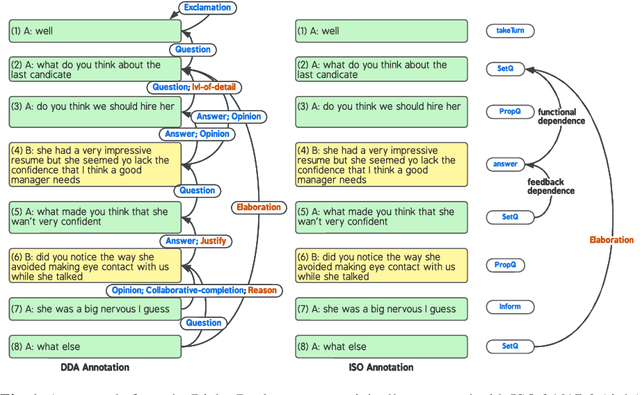

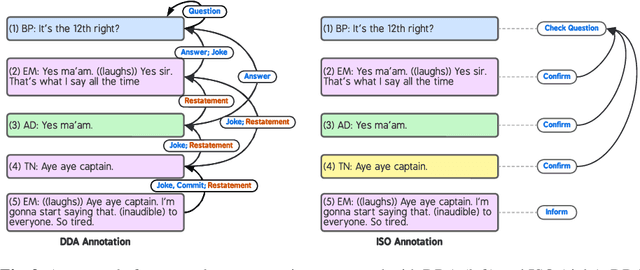
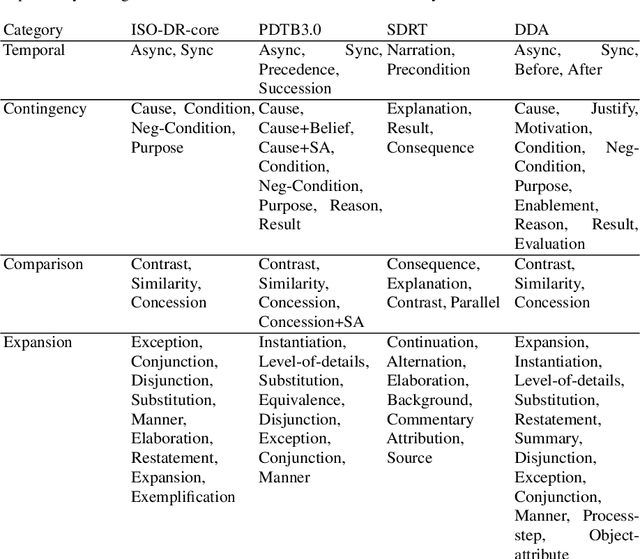
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology