 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023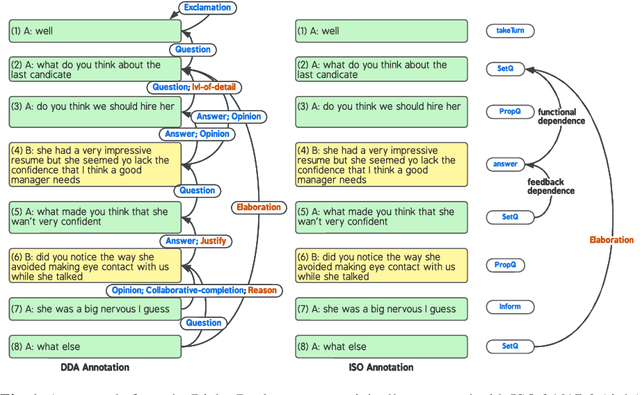

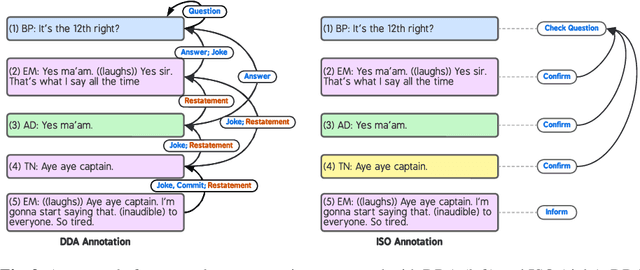
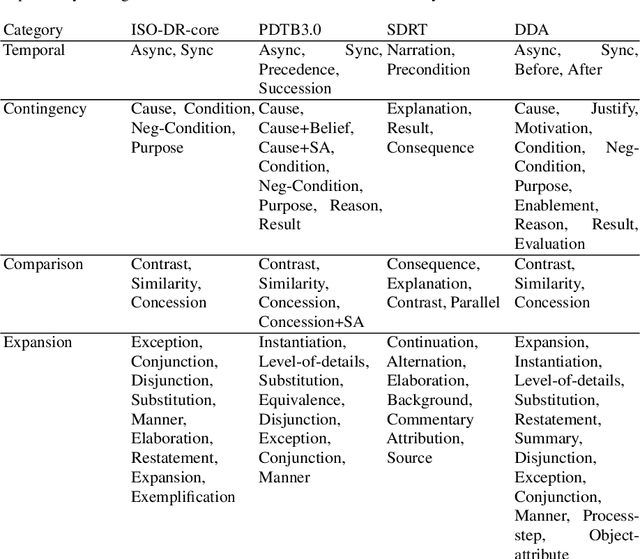
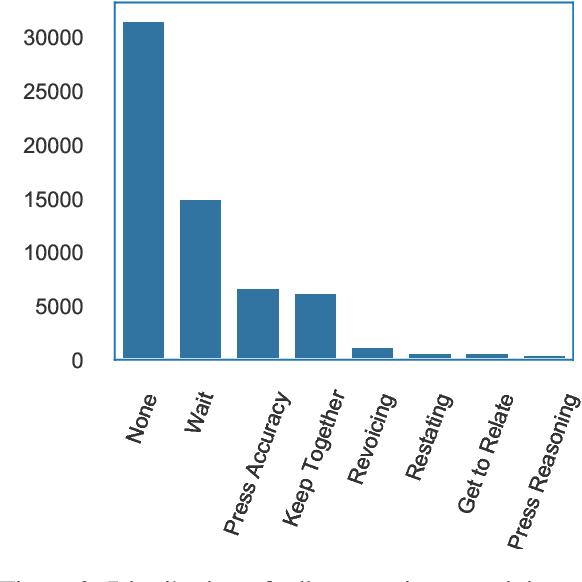
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
Don't Rule Out Monolingual Speakers: A Method For Crowdsourcing Machine Translation Data
Jun 12, 2021



High-performing machine translation (MT) systems can help overcome language barriers while making it possible for everyone to communicate and use language technologies in the language of their choice. However, such systems require large amounts of parallel sentences for training, and translators can be difficult to find and expensive. Here, we present a data collection strategy for MT which, in contrast, is cheap and simple, as it does not require bilingual speakers. Based on the insight that humans pay specific attention to movements, we use graphics interchange formats (GIFs) as a pivot to collect parallel sentences from monolingual annotators. We use our strategy to collect data in Hindi, Tamil and English. As a baseline, we also collect data using images as a pivot. We perform an intrinsic evaluation by manually evaluating a subset of the sentence pairs and an extrinsic evaluation by finetuning mBART on the collected data. We find that sentences collected via GIFs are indeed of higher quality.
What Would a Teacher Do? Predicting Future Talk Moves
Jun 09, 2021


Recent advances in natural language processing (NLP) have the ability to transform how classroom learning takes place. Combined with the increasing integration of technology in today's classrooms, NLP systems leveraging question answering and dialog processing techniques can serve as private tutors or participants in classroom discussions to increase student engagement and learning. To progress towards this goal, we use the classroom discourse framework of academically productive talk (APT) to learn strategies that make for the best learning experience. In this paper, we introduce a new task, called future talk move prediction (FTMP): it consists of predicting the next talk move -- an utterance strategy from APT -- given a conversation history with its corresponding talk moves. We further introduce a neural network model for this task, which outperforms multiple baselines by a large margin. Finally, we compare our model's performance on FTMP to human performance and show several similarities between the two.
Energy and Policy Considerations for Deep Learning in NLP
Jun 05, 2019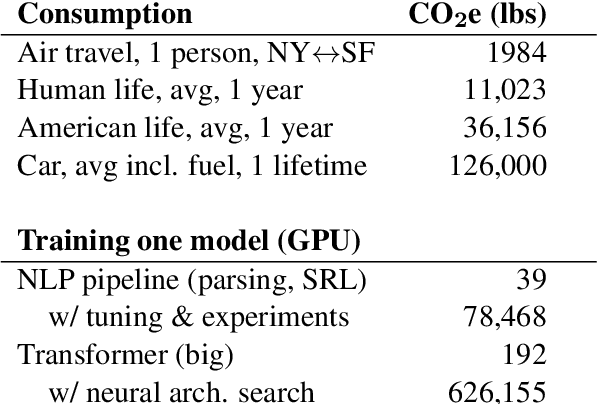
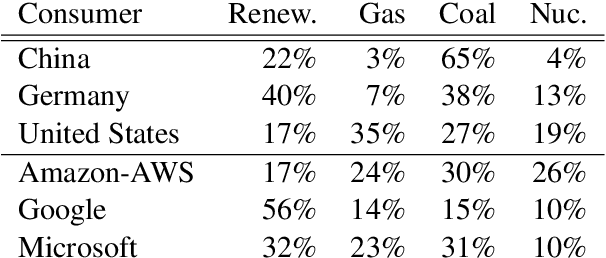

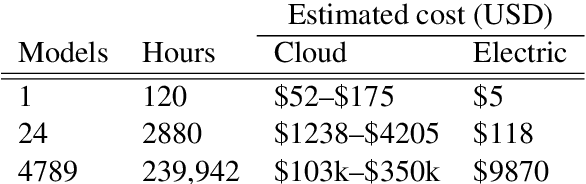
Recent progress in hardware and methodology for training neural networks has ushered in a new generation of large networks trained on abundant data. These models have obtained notable gains in accuracy across many NLP tasks. However, these accuracy improvements depend on the availability of exceptionally large computational resources that necessitate similarly substantial energy consumption. As a result these models are costly to train and develop, both financially, due to the cost of hardware and electricity or cloud compute time, and environmentally, due to the carbon footprint required to fuel modern tensor processing hardware. In this paper we bring this issue to the attention of NLP researchers by quantifying the approximate financial and environmental costs of training a variety of recently successful neural network models for NLP. Based on these findings, we propose actionable recommendations to reduce costs and improve equity in NLP research and practice.
Efficient Graph-based Word Sense Induction by Distributional Inclusion Vector Embeddings
May 29, 2018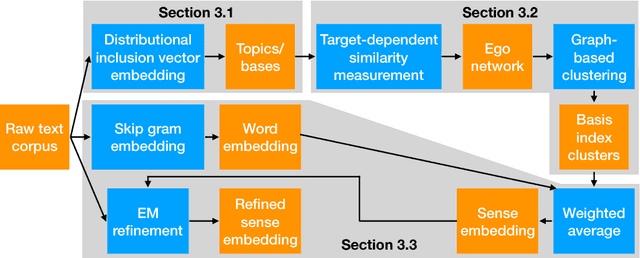
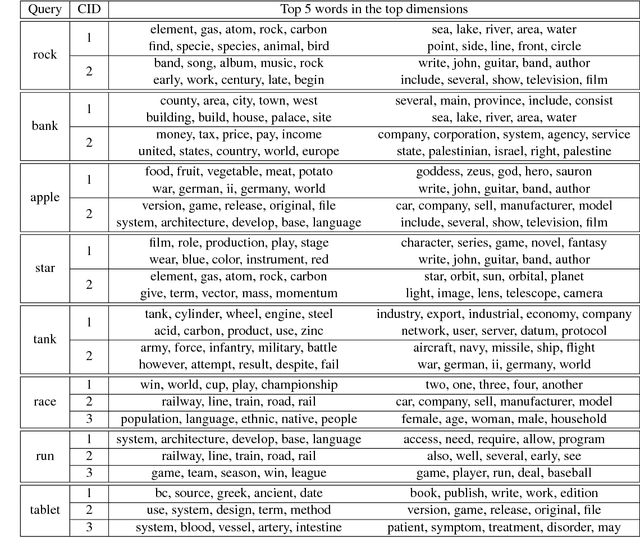
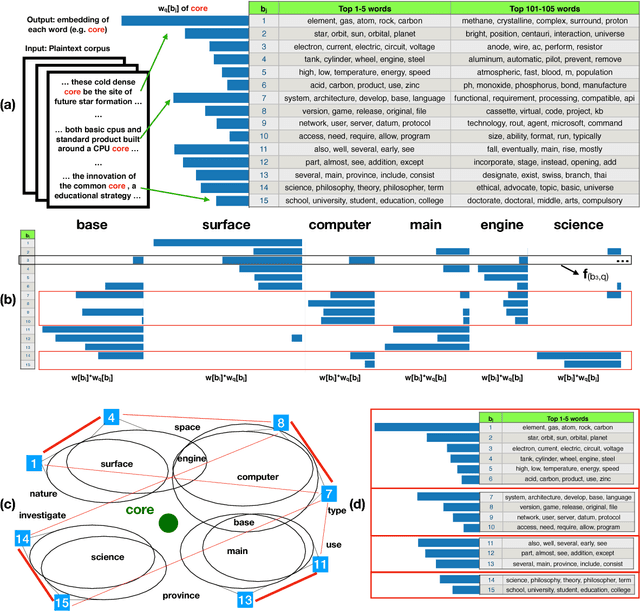
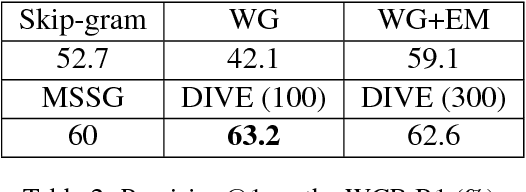
Word sense induction (WSI), which addresses polysemy by unsupervised discovery of multiple word senses, resolves ambiguities for downstream NLP tasks and also makes word representations more interpretable. This paper proposes an accurate and efficient graph-based method for WSI that builds a global non-negative vector embedding basis (which are interpretable like topics) and clusters the basis indexes in the ego network of each polysemous word. By adopting distributional inclusion vector embeddings as our basis formation model, we avoid the expensive step of nearest neighbor search that plagues other graph-based methods without sacrificing the quality of sense clusters. Experiments on three datasets show that our proposed method produces similar or better sense clusters and embeddings compared with previous state-of-the-art methods while being significantly more efficient.