 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeech Is Not Enough: Interpreting Nonverbal Indicators of Common Knowledge and Engagement
Dec 08, 2024

Our goal is to develop an AI Partner that can provide support for group problem solving and social dynamics. In multi-party working group environments, multimodal analytics is crucial for identifying non-verbal interactions of group members. In conjunction with their verbal participation, this creates an holistic understanding of collaboration and engagement that provides necessary context for the AI Partner. In this demo, we illustrate our present capabilities at detecting and tracking nonverbal behavior in student task-oriented interactions in the classroom, and the implications for tracking common ground and engagement.
SCI 3.0: A Web-based Schema Curation Interface for Graphical Event Representations
May 17, 2024To understand the complexity of global events, one must navigate a web of interwoven sub-events, identifying those most impactful elements within the larger, abstract macro-event framework at play. This concept can be extended to the field of natural language processing (NLP) through the creation of structured event schemas which can serve as representations of these abstract events. Central to our approach is the Schema Curation Interface 3.0 (SCI 3.0), a web application that facilitates real-time editing of event schema properties within a generated graph e.g., adding, removing, or editing sub-events, entities, and relations directly through an interface.
Adapting Abstract Meaning Representation Parsing to the Clinical Narrative -- the SPRING THYME parser
May 15, 2024This paper is dedicated to the design and evaluation of the first AMR parser tailored for clinical notes. Our objective was to facilitate the precise transformation of the clinical notes into structured AMR expressions, thereby enhancing the interpretability and usability of clinical text data at scale. Leveraging the colon cancer dataset from the Temporal Histories of Your Medical Events (THYME) corpus, we adapted a state-of-the-art AMR parser utilizing continuous training. Our approach incorporates data augmentation techniques to enhance the accuracy of AMR structure predictions. Notably, through this learning strategy, our parser achieved an impressive F1 score of 88% on the THYME corpus's colon cancer dataset. Moreover, our research delved into the efficacy of data required for domain adaptation within the realm of clinical notes, presenting domain adaptation data requirements for AMR parsing. This exploration not only underscores the parser's robust performance but also highlights its potential in facilitating a deeper understanding of clinical narratives through structured semantic representations.
RESIN-EDITOR: A Schema-guided Hierarchical Event Graph Visualizer and Editor
Dec 05, 2023In this paper, we present RESIN-EDITOR, an interactive event graph visualizer and editor designed for analyzing complex events. Our RESIN-EDITOR system allows users to render and freely edit hierarchical event graphs extracted from multimedia and multi-document news clusters with guidance from human-curated event schemas. RESIN-EDITOR's unique features include hierarchical graph visualization, comprehensive source tracing, and interactive user editing, which is more powerful and versatile than existing Information Extraction (IE) visualization tools. In our evaluation of RESIN-EDITOR, we demonstrate ways in which our tool is effective in understanding complex events and enhancing system performance. The source code, a video demonstration, and a live website for RESIN-EDITOR have been made publicly available.
CAMRA: Copilot for AMR Annotation
Nov 18, 2023


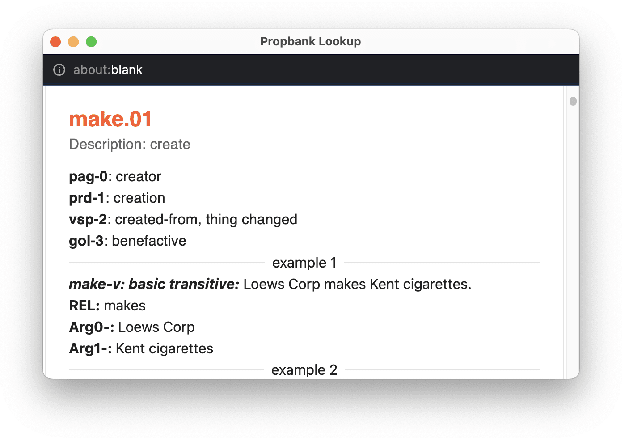
In this paper, we introduce CAMRA (Copilot for AMR Annotatations), a cutting-edge web-based tool designed for constructing Abstract Meaning Representation (AMR) from natural language text. CAMRA offers a novel approach to deep lexical semantics annotation such as AMR, treating AMR annotation akin to coding in programming languages. Leveraging the familiarity of programming paradigms, CAMRA encompasses all essential features of existing AMR editors, including example lookup, while going a step further by integrating Propbank roleset lookup as an autocomplete feature within the tool. Notably, CAMRA incorporates AMR parser models as coding co-pilots, greatly enhancing the efficiency and accuracy of AMR annotators. To demonstrate the tool's capabilities, we provide a live demo accessible at: https://camra.colorado.edu
Learning Semantic Role Labeling from Compatible Label Sequences
May 24, 2023This paper addresses the question of how to efficiently learn from disjoint, compatible label sequences. We argue that the compatible structures between disjoint label sets help model learning and inference. We verify this hypothesis on the task of semantic role labeling (SRL), specifically, tagging a sentence with two role sequences: VerbNet arguments and PropBank arguments. Prior work has shown that cross-task interaction improves performance. However, the two tasks are still separately decoded, running the risk of generating structurally inconsistent label sequences (as per lexicons like SEMLINK). To eliminate this issue, we first propose a simple and effective setup that jointly handles VerbNet and PropBank labels as one sequence. With this setup, we show that enforcing SEMLINK constraints during decoding constantly improves the overall F1. With special input constructions, our joint model infers VerbNet arguments from PropBank arguments with over 99% accuracy. We also propose a constrained marginal model that uses SEMLINK information during training to further benefit from the large amounts of PropBank-only data. Our models achieve state-of-the-art F1's on VerbNet and PropBank argument labeling on the CoNLL05 dataset with strong out-of-domain generalization.
GLEN: General-Purpose Event Detection for Thousands of Types
Mar 20, 2023



The development of event extraction systems has been hindered by the absence of wide-coverage, large-scale datasets. To make event extraction systems more accessible, we build a general-purpose event detection dataset GLEN, which covers 3,465 different event types, making it over 20x larger in ontology than any current dataset. GLEN is created by utilizing the DWD Overlay, which provides a mapping between Wikidata Qnodes and PropBank rolesets. This enables us to use the abundant existing annotation for PropBank as distant supervision. In addition, we also propose a new multi-stage event detection model specifically designed to handle the large ontology size and partial labels in GLEN. We show that our model exhibits superior performance (~10% F1 gain) compared to both conventional classification baselines and newer definition-based models. Finally, we perform error analysis and show that label noise is still the largest challenge for improving performance.
Dependency Dialogue Acts -- Annotation Scheme and Case Study
Feb 25, 2023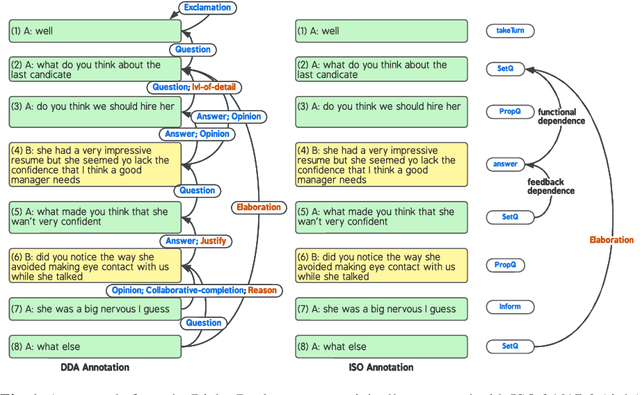

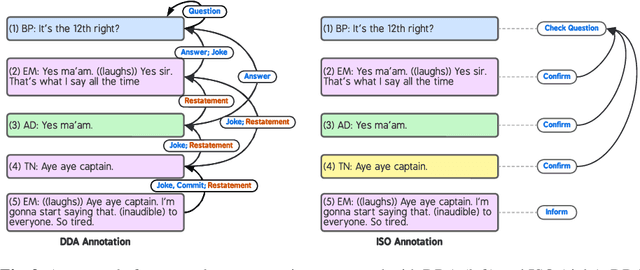
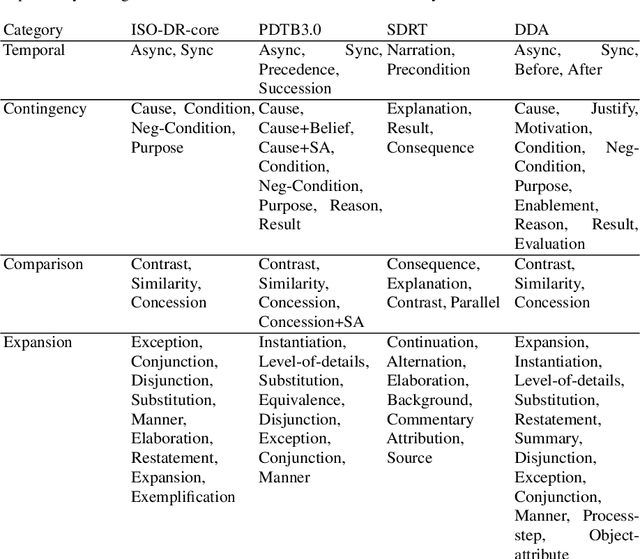
In this paper, we introduce Dependency Dialogue Acts (DDA), a novel framework for capturing the structure of speaker-intentions in multi-party dialogues. DDA combines and adapts features from existing dialogue annotation frameworks, and emphasizes the multi-relational response structure of dialogues in addition to the dialogue acts and rhetorical relations. It represents the functional, discourse, and response structure in multi-party multi-threaded conversations. A few key features distinguish DDA from existing dialogue annotation frameworks such as SWBD-DAMSL and the ISO 24617-2 standard. First, DDA prioritizes the relational structure of the dialogue units and the dialog context, annotating both dialog acts and rhetorical relations as response relations to particular utterances. Second, DDA embraces overloading in dialogues, encouraging annotators to specify multiple response relations and dialog acts for each dialog unit. Lastly, DDA places an emphasis on adequately capturing how a speaker is using the full dialog context to plan and organize their speech. With these features, DDA is highly expressive and recall-oriented with regard to conversation dynamics between multiple speakers. In what follows, we present the DDA annotation framework and case studies annotating DDA structures in multi-party, multi-threaded conversations.
* The 13th International Workshop on Spoken Dialogue Systems Technology
Human-in-the-Loop Schema Induction
Feb 25, 2023Schema induction builds a graph representation explaining how events unfold in a scenario. Existing approaches have been based on information retrieval (IR) and information extraction(IE), often with limited human curation. We demonstrate a human-in-the-loop schema induction system powered by GPT-3. We first describe the different modules of our system, including prompting to generate schematic elements, manual edit of those elements, and conversion of those into a schema graph. By qualitatively comparing our system to previous ones, we show that our system not only transfers to new domains more easily than previous approaches, but also reduces efforts of human curation thanks to our interactive interface.
Human-guided Collaborative Problem Solving: A Natural Language based Framework
Jul 19, 2022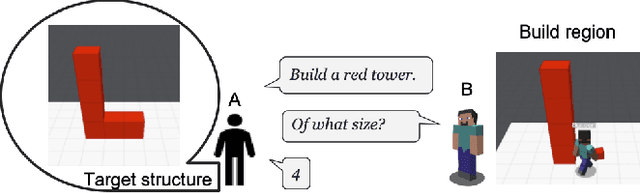
We consider the problem of human-machine collaborative problem solving as a planning task coupled with natural language communication. Our framework consists of three components -- a natural language engine that parses the language utterances to a formal representation and vice-versa, a concept learner that induces generalized concepts for plans based on limited interactions with the user, and an HTN planner that solves the task based on human interaction. We illustrate the ability of this framework to address the key challenges of collaborative problem solving by demonstrating it on a collaborative building task in a Minecraft-based blocksworld domain. The accompanied demo video is available at https://youtu.be/q1pWe4aahF0.