 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCRAFT: Grounded Multi-Agent Coordination Under Partial Information
Mar 26, 2026We introduce CRAFT, a multi-agent benchmark for evaluating pragmatic communication in large language models under strict partial information. In this setting, multiple agents with complementary but incomplete views must coordinate through natural language to construct a shared 3D structure that no single agent can fully observe. We formalize this problem as a multi-sender pragmatic reasoning task and provide a diagnostic framework that decomposes failures into spatial grounding, belief modeling and pragmatic communication errors, including a taxonomy of behavioral failure profiles in both frontier and open-weight models. Across a diverse set of models, including 8 open-weight and 7 frontier including reasoning models, we find that stronger reasoning ability does not reliably translate to better coordination: smaller open-weight models often match or outperform frontier systems, and improved individual communication does not guarantee successful collaboration. These results suggest that multi-agent coordination remains a fundamentally unsolved challenge for current language models. Our code can be found at https://github.com/csu-signal/CRAFT
Distributed Partial Information Puzzles: Examining Common Ground Construction Under Epistemic Asymmetry
Mar 05, 2026Establishing common ground, a shared set of beliefs and mutually recognized facts, is fundamental to collaboration, yet remains a challenge for current AI systems, especially in multimodal, multiparty settings, where the collaborators bring different information to the table. We introduce the Distributed Partial Information Puzzle (DPIP), a collaborative construction task that elicits rich multimodal communication under epistemic asymmetry. We present a multimodal dataset of these interactions, annotated and temporally aligned across speech, gesture, and action modalities to support reasoning over propositional content and belief dynamics. We then evaluate two paradigms for modeling common ground (CG): (1) state-of-the-art large language models (LLMs), prompted to infer shared beliefs from multimodal updates, and (2) an axiomatic pipeline grounded in Dynamic Epistemic Logic (DEL) that incrementally performs the same task. Results on the annotated DPIP data indicate that it poses a challenge to modern LLMs' abilities to track both task progression and belief state.
Owen-Shapley Policy Optimization (OSPO): A Principled RL Algorithm for Generative Search LLMs
Jan 13, 2026Large language models are increasingly trained via reinforcement learning for personalized recommendation tasks, but standard methods like GRPO rely on sparse, sequence-level rewards that create a credit assignment gap, obscuring which tokens drive success. This gap is especially problematic when models must infer latent user intent from under-specified language without ground truth labels, a reasoning pattern rarely seen during pretraining. We introduce Owen-Shapley Policy Optimization (OSPO), a framework that redistributes sequence-level advantages based on tokens' marginal contributions to outcomes. Unlike value-model-based methods requiring additional computation, OSPO employs potential-based reward shaping via Shapley-Owen attributions to assign segment-level credit while preserving the optimal policy, learning directly from task feedback without parametric value models. By forming coalitions of semantically coherent units (phrases describing product attributes or sentences capturing preferences), OSPO identifies which response parts drive performance. Experiments on Amazon ESCI and H&M Fashion datasets show consistent gains over baselines, with notable test-time robustness to out-of-distribution retrievers unseen during training.
Learning "Partner-Aware" Collaborators in Multi-Party Collaboration
Oct 26, 2025Large Language Models (LLMs) are increasingly bring deployed in agentic settings where they act as collaborators with humans. Therefore, it is increasingly important to be able to evaluate their abilities to collaborate effectively in multi-turn, multi-party tasks. In this paper, we build on the AI alignment and safe interruptability literature to offer novel theoretical insights on collaborative behavior between LLM-driven collaborator agents and an intervention agent. Our goal is to learn an ideal partner-aware collaborator that increases the group's common-ground (CG)-alignment on task-relevant propositions-by intelligently collecting information provided in interventions by a partner agent.We show how LLM agents trained using standard RLHF and related approaches are naturally inclined to ignore possibly well-meaning interventions, which makes increasing group common ground non-trivial in this setting. We employ a two-player Modified-Action MDP to examine this suboptimal behavior of standard AI agents, and propose Interruptible Collaborative Roleplayer (ICR)-a novel partner-aware learning algorithm to train CG-optimal collaborators. Experiments on multiple collaborative task environments show that ICR, on average, is more capable of promoting successful CG convergence and exploring more diverse solutions in such tasks.
On the Role of Domain Experts in Creating Effective Tutoring Systems
Oct 01, 2025The role that highly curated knowledge, provided by domain experts, could play in creating effective tutoring systems is often overlooked within the AI for education community. In this paper, we highlight this topic by discussing two ways such highly curated expert knowledge could help in creating novel educational systems. First, we will look at how one could use explainable AI (XAI) techniques to automatically create lessons. Most existing XAI methods are primarily aimed at debugging AI systems. However, we will discuss how one could use expert specified rules about solving specific problems along with novel XAI techniques to automatically generate lessons that could be provided to learners. Secondly, we will see how an expert specified curriculum for learning a target concept can help develop adaptive tutoring systems, that can not only provide a better learning experience, but could also allow us to use more efficient algorithms to create these systems. Finally, we will highlight the importance of such methods using a case study of creating a tutoring system for pollinator identification, where such knowledge could easily be elicited from experts.
The Impact of Background Speech on Interruption Detection in Collaborative Groups
Jul 09, 2025Interruption plays a crucial role in collaborative learning, shaping group interactions and influencing knowledge construction. AI-driven support can assist teachers in monitoring these interactions. However, most previous work on interruption detection and interpretation has been conducted in single-conversation environments with relatively clean audio. AI agents deployed in classrooms for collaborative learning within small groups will need to contend with multiple concurrent conversations -- in this context, overlapping speech will be ubiquitous, and interruptions will need to be identified in other ways. In this work, we analyze interruption detection in single-conversation and multi-group dialogue settings. We then create a state-of-the-art method for interruption identification that is robust to overlapping speech, and thus could be deployed in classrooms. Further, our work highlights meaningful linguistic and prosodic information about how interruptions manifest in collaborative group interactions. Our investigation also paves the way for future works to account for the influence of overlapping speech from multiple groups when tracking group dialog.
Dynamic Epistemic Friction in Dialogue
Jun 12, 2025



Recent developments in aligning Large Language Models (LLMs) with human preferences have significantly enhanced their utility in human-AI collaborative scenarios. However, such approaches often neglect the critical role of "epistemic friction," or the inherent resistance encountered when updating beliefs in response to new, conflicting, or ambiguous information. In this paper, we define dynamic epistemic friction as the resistance to epistemic integration, characterized by the misalignment between an agent's current belief state and new propositions supported by external evidence. We position this within the framework of Dynamic Epistemic Logic (Van Benthem and Pacuit, 2011), where friction emerges as nontrivial belief-revision during the interaction. We then present analyses from a situated collaborative task that demonstrate how this model of epistemic friction can effectively predict belief updates in dialogues, and we subsequently discuss how the model of belief alignment as a measure of epistemic resistance or friction can naturally be made more sophisticated to accommodate the complexities of real-world dialogue scenarios.
Frictional Agent Alignment Framework: Slow Down and Don't Break Things
May 26, 2025AI support of collaborative interactions entails mediating potential misalignment between interlocutor beliefs. Common preference alignment methods like DPO excel in static settings, but struggle in dynamic collaborative tasks where the explicit signals of interlocutor beliefs are sparse and skewed. We propose the Frictional Agent Alignment Framework (FAAF), to generate precise, context-aware "friction" that prompts for deliberation and re-examination of existing evidence. FAAF's two-player objective decouples from data skew: a frictive-state policy identifies belief misalignments, while an intervention policy crafts collaborator-preferred responses. We derive an analytical solution to this objective, enabling training a single policy via a simple supervised loss. Experiments on three benchmarks show FAAF outperforms competitors in producing concise, interpretable friction and in OOD generalization. By aligning LLMs to act as adaptive "thought partners" -- not passive responders -- FAAF advances scalable, dynamic human-AI collaboration. Our code and data can be found at https://github.com/csu-signal/FAAF_ACL.
TRACE: Real-Time Multimodal Common Ground Tracking in Situated Collaborative Dialogues
Mar 12, 2025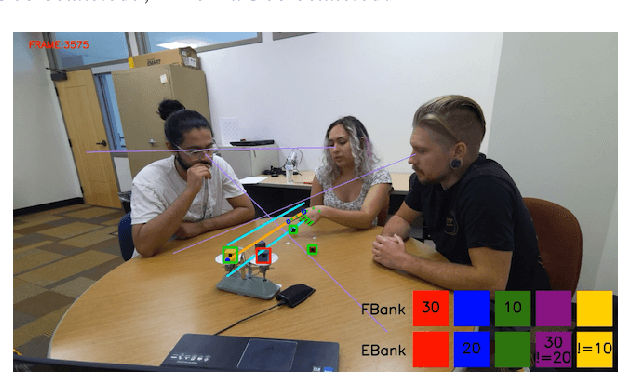

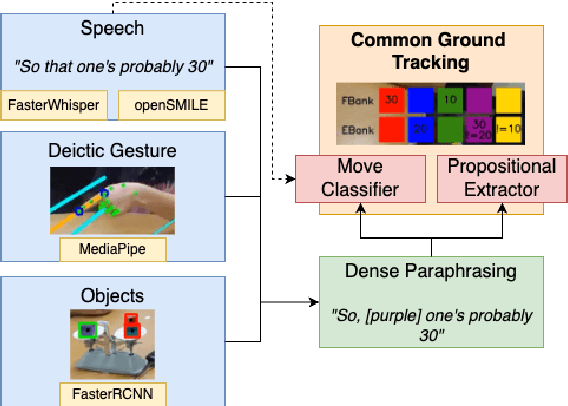
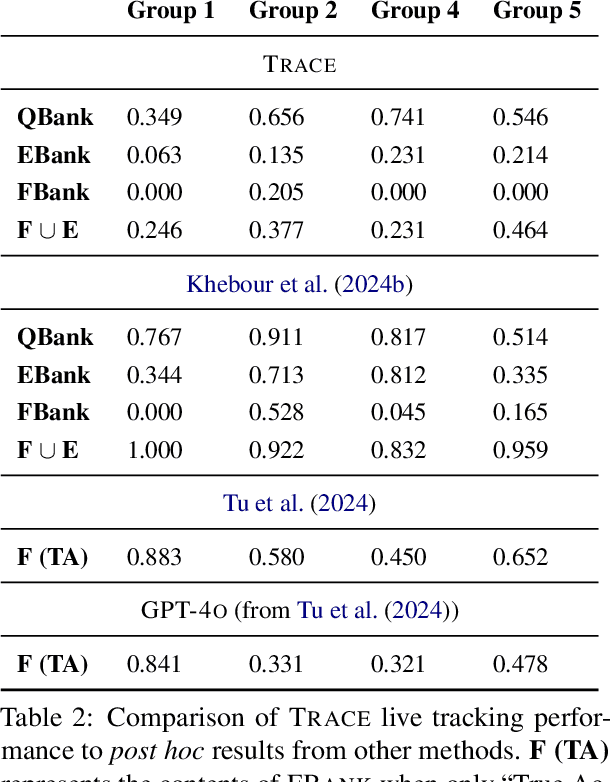
We present TRACE, a novel system for live *common ground* tracking in situated collaborative tasks. With a focus on fast, real-time performance, TRACE tracks the speech, actions, gestures, and visual attention of participants, uses these multimodal inputs to determine the set of task-relevant propositions that have been raised as the dialogue progresses, and tracks the group's epistemic position and beliefs toward them as the task unfolds. Amid increased interest in AI systems that can mediate collaborations, TRACE represents an important step forward for agents that can engage with multiparty, multimodal discourse.
Speech Is Not Enough: Interpreting Nonverbal Indicators of Common Knowledge and Engagement
Dec 08, 2024

Our goal is to develop an AI Partner that can provide support for group problem solving and social dynamics. In multi-party working group environments, multimodal analytics is crucial for identifying non-verbal interactions of group members. In conjunction with their verbal participation, this creates an holistic understanding of collaboration and engagement that provides necessary context for the AI Partner. In this demo, we illustrate our present capabilities at detecting and tracking nonverbal behavior in student task-oriented interactions in the classroom, and the implications for tracking common ground and engagement.