 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProof of Time: A Benchmark for Evaluating Scientific Idea Judgments
Jan 12, 2026Large language models are increasingly being used to assess and forecast research ideas, yet we lack scalable ways to evaluate the quality of models' judgments about these scientific ideas. Towards this goal, we introduce PoT, a semi-verifiable benchmarking framework that links scientific idea judgments to downstream signals that become observable later (e.g., citations and shifts in researchers' agendas). PoT freezes a pre-cutoff snapshot of evidence in an offline sandbox and asks models to forecast post-cutoff outcomes, enabling verifiable evaluation when ground truth arrives, scalable benchmarking without exhaustive expert annotation, and analysis of human-model misalignment against signals such as peer-review awards. In addition, PoT provides a controlled testbed for agent-based research judgments that evaluate scientific ideas, comparing tool-using agents to non-agent baselines under prompt ablations and budget scaling. Across 30,000+ instances spanning four benchmark domains, we find that, compared with non-agent baselines, higher interaction budgets generally improve agent performance, while the benefit of tool use is strongly task-dependent. By combining time-partitioned, future-verifiable targets with an offline sandbox for tool use, PoT supports scalable evaluation of agents on future-facing scientific idea judgment tasks.
TRACE: Real-Time Multimodal Common Ground Tracking in Situated Collaborative Dialogues
Mar 12, 2025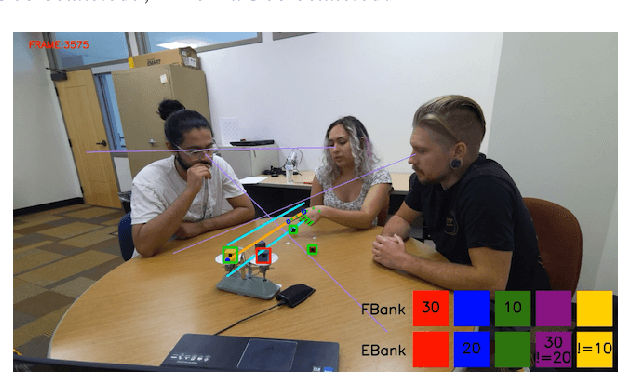

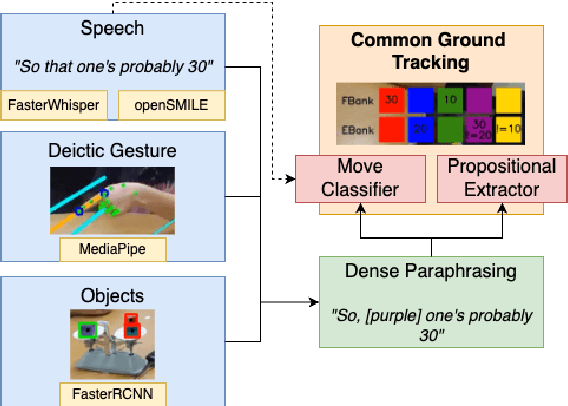
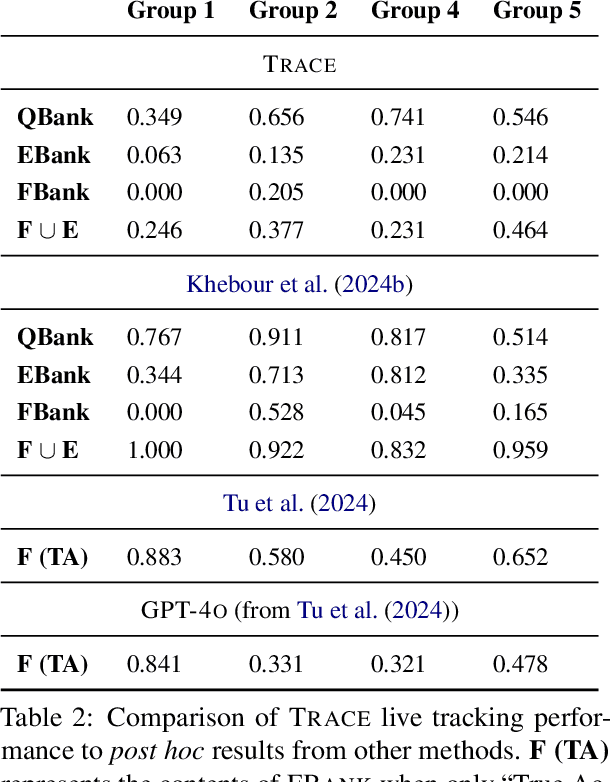
We present TRACE, a novel system for live *common ground* tracking in situated collaborative tasks. With a focus on fast, real-time performance, TRACE tracks the speech, actions, gestures, and visual attention of participants, uses these multimodal inputs to determine the set of task-relevant propositions that have been raised as the dialogue progresses, and tracks the group's epistemic position and beliefs toward them as the task unfolds. Amid increased interest in AI systems that can mediate collaborations, TRACE represents an important step forward for agents that can engage with multiparty, multimodal discourse.
Linguistically Conditioned Semantic Textual Similarity
Jun 06, 2024
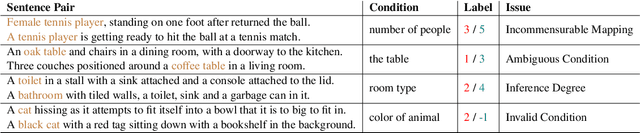
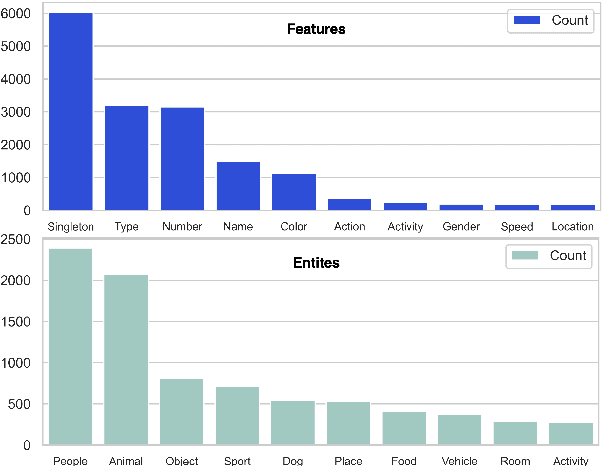

Semantic textual similarity (STS) is a fundamental NLP task that measures the semantic similarity between a pair of sentences. In order to reduce the inherent ambiguity posed from the sentences, a recent work called Conditional STS (C-STS) has been proposed to measure the sentences' similarity conditioned on a certain aspect. Despite the popularity of C-STS, we find that the current C-STS dataset suffers from various issues that could impede proper evaluation on this task. In this paper, we reannotate the C-STS validation set and observe an annotator discrepancy on 55% of the instances resulting from the annotation errors in the original label, ill-defined conditions, and the lack of clarity in the task definition. After a thorough dataset analysis, we improve the C-STS task by leveraging the models' capability to understand the conditions under a QA task setting. With the generated answers, we present an automatic error identification pipeline that is able to identify annotation errors from the C-STS data with over 80% F1 score. We also propose a new method that largely improves the performance over baselines on the C-STS data by training the models with the answers. Finally we discuss the conditionality annotation based on the typed-feature structure (TFS) of entity types. We show in examples that the TFS is able to provide a linguistic foundation for constructing C-STS data with new conditions.
Common Ground Tracking in Multimodal Dialogue
Mar 26, 2024



Within Dialogue Modeling research in AI and NLP, considerable attention has been spent on ``dialogue state tracking'' (DST), which is the ability to update the representations of the speaker's needs at each turn in the dialogue by taking into account the past dialogue moves and history. Less studied but just as important to dialogue modeling, however, is ``common ground tracking'' (CGT), which identifies the shared belief space held by all of the participants in a task-oriented dialogue: the task-relevant propositions all participants accept as true. In this paper we present a method for automatically identifying the current set of shared beliefs and ``questions under discussion'' (QUDs) of a group with a shared goal. We annotate a dataset of multimodal interactions in a shared physical space with speech transcriptions, prosodic features, gestures, actions, and facets of collaboration, and operationalize these features for use in a deep neural model to predict moves toward construction of common ground. Model outputs cascade into a set of formal closure rules derived from situated evidence and belief axioms and update operations. We empirically assess the contribution of each feature type toward successful construction of common ground relative to ground truth, establishing a benchmark in this novel, challenging task.
Designing Multimodal Datasets for NLP Challenges
May 12, 2021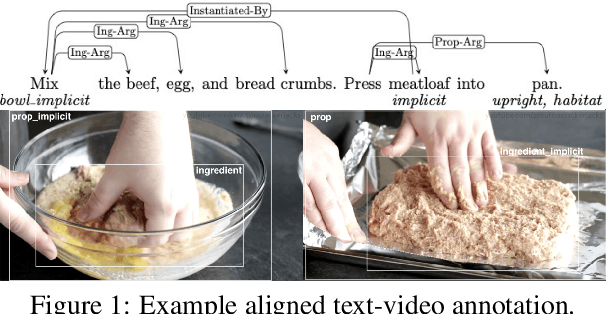


In this paper, we argue that the design and development of multimodal datasets for natural language processing (NLP) challenges should be enhanced in two significant respects: to more broadly represent commonsense semantic inferences; and to better reflect the dynamics of actions and events, through a substantive alignment of textual and visual information. We identify challenges and tasks that are reflective of linguistic and cognitive competencies that humans have when speaking and reasoning, rather than merely the performance of systems on isolated tasks. We introduce the distinction between challenge-based tasks and competence-based performance, and describe a diagnostic dataset, Recipe-to-Video Questions (R2VQ), designed for testing competence-based comprehension over a multimodal recipe collection (http://r2vq.org/). The corpus contains detailed annotation supporting such inferencing tasks and facilitating a rich set of question families that we use to evaluate NLP systems.
TMR: Evaluating NER Recall on Tough Mentions
Mar 23, 2021
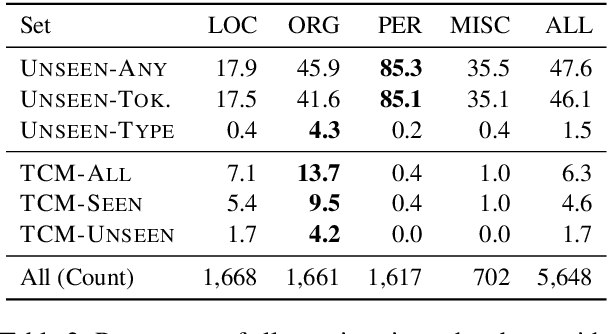
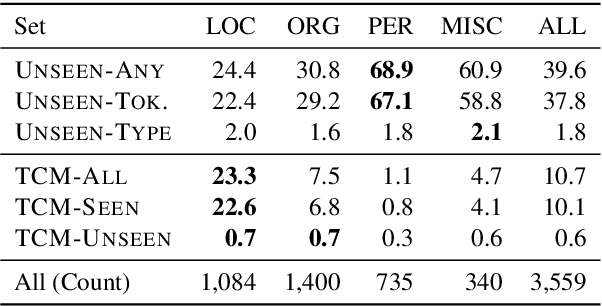
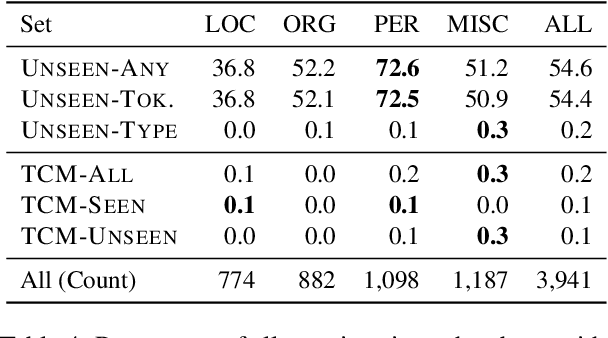
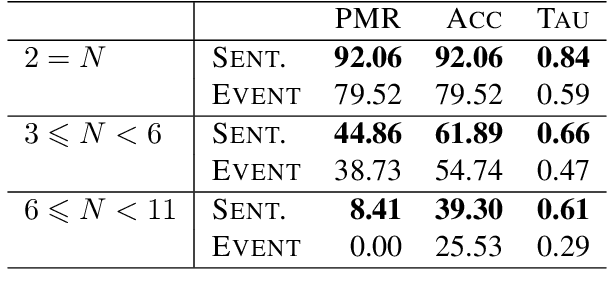
We propose the Tough Mentions Recall (TMR) metrics to supplement traditional named entity recognition (NER) evaluation by examining recall on specific subsets of "tough" mentions: unseen mentions, those whose tokens or token/type combination were not observed in training, and type-confusable mentions, token sequences with multiple entity types in the test data. We demonstrate the usefulness of these metrics by evaluating corpora of English, Spanish, and Dutch using five recent neural architectures. We identify subtle differences between the performance of BERT and Flair on two English NER corpora and identify a weak spot in the performance of current models in Spanish. We conclude that the TMR metrics enable differentiation between otherwise similar-scoring systems and identification of patterns in performance that would go unnoticed from overall precision, recall, and F1.
COVID-19 Literature Knowledge Graph Construction and Drug Repurposing Report Generation
Jul 06, 2020
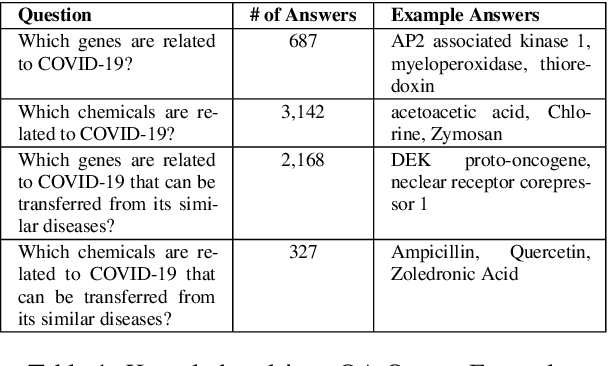
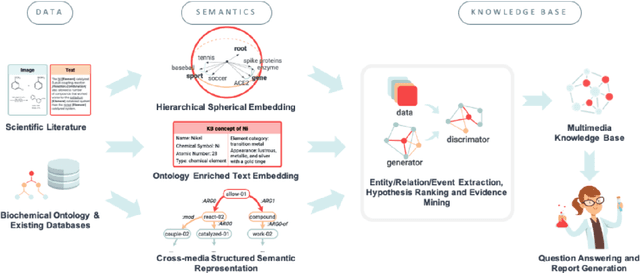
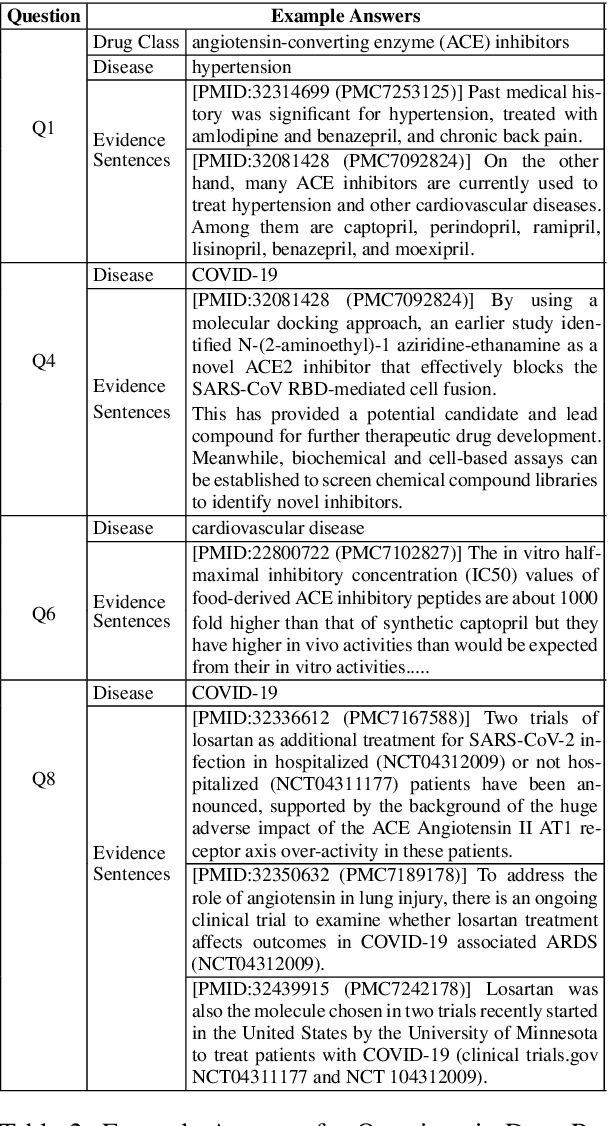
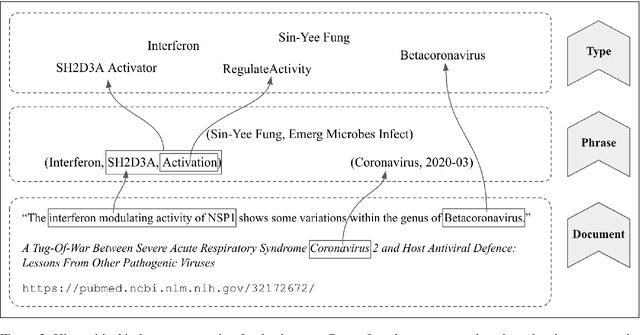
To combat COVID-19, clinicians and scientists all need to digest the vast amount of relevant biomedical knowledge in literature to understand the disease mechanism and the related biological functions. We have developed a novel and comprehensive knowledge discovery framework, COVID-KG, which leverages novel semantic representation and external ontologies to represent text and images in the input literature data, and then performs various extraction components to extract fine-grained multimedia knowledge elements (entities, relations and events). We then exploit the constructed multimedia KGs for question answering and report generation, using drug repurposing as a case study. Our framework also provides detailed contextual sentences, subfigures and knowledge subgraphs as evidence. All of the data, KGs, resources, and shared services are publicly available.
Exploration and Discovery of the COVID-19 Literature through Semantic Visualization
Jul 03, 2020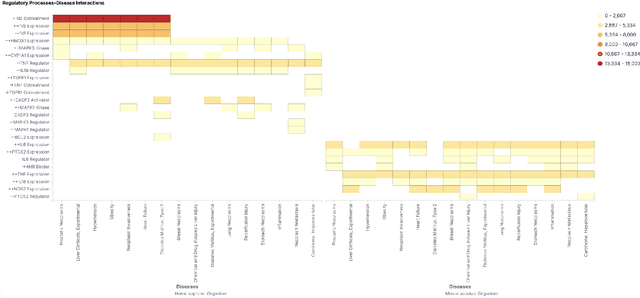

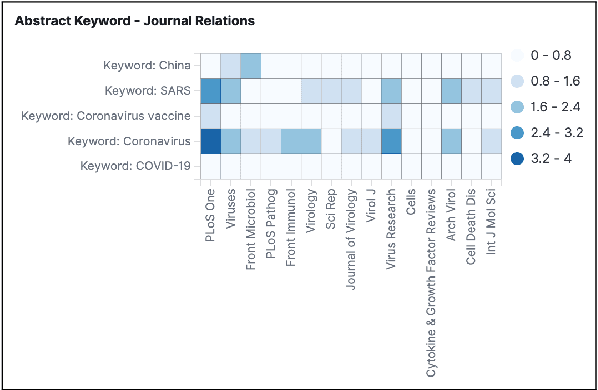
We are developing semantic visualization techniques in order to enhance exploration and enable discovery over large datasets of complex networks of relations. Semantic visualization is a method of enabling exploration and discovery over large datasets of complex networks by exploiting the semantics of the relations in them. This involves (i) NLP to extract named entities, relations and knowledge graphs from the original data; (ii) indexing the output and creating representations for all relevant entities and relations that can be visualized in many different ways, e.g., as tag clouds, heat maps, graphs, etc.; (iii) applying parameter reduction operations to the extracted relations, creating "relation containers", or functional entities that can also be visualized using the same methods, allowing the visualization of multiple relations, partial pathways, and exploration across multiple dimensions. Our hope is that this will enable the discovery of novel inferences over relations in complex data that otherwise would go unnoticed. We have applied this to analysis of the recently released CORD-19 dataset.